










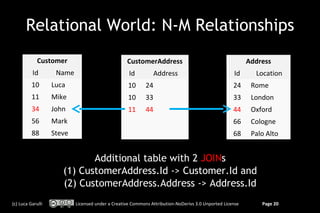






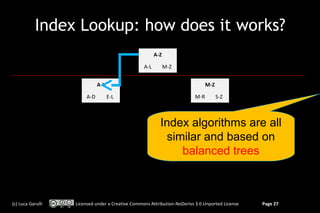
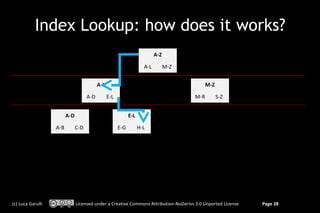
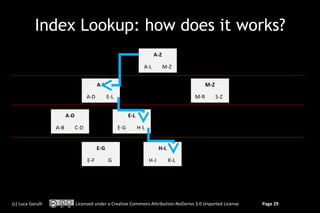
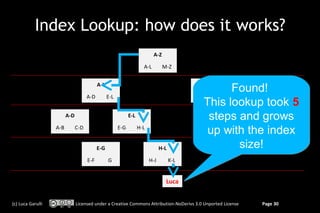






![OrientDB: traverse a relationship
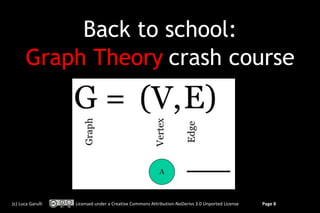
The Record ID (RID)
is the physical position
RID = #13:35
RID = #13:35 RID = #13:100
RID = #13:100
RID = #14:54
RID = #14:54
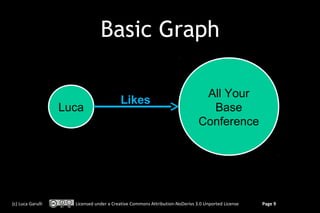
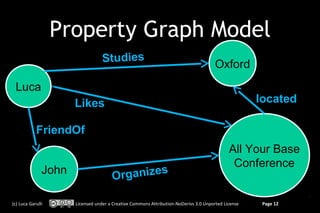
Lives
Luca
Luca Rome
Rome
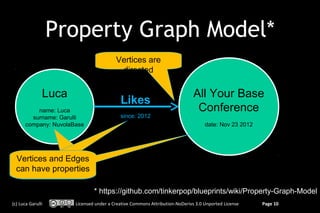
out: [#13:35]
out: [#13:35]
in: [#13:100]
in: [#13:100]
out : :[#14:54] Label : :‘Lives’
Label ‘Lives’ in: [#14:54]
out [#14:54] in: [#14:54]
label : :‘Customer’
label ‘Customer’ label = ‘Address’
label = ‘Address’
name : :‘Luca’
name ‘Luca’ name = ‘Rome’
name = ‘Rome’
(c) Luca Garulli Licensed under a Creative Commons Attribution-NoDerivs 3.0 Unported License Page 37](https://image.slidesharecdn.com/ayb-switchingfromrelational2graph-121123135852-phpapp02/85/Switching-from-relational-to-the-graph-model-37-320.jpg)





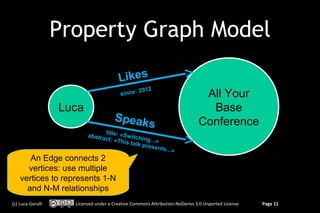
![Query the graph in SQL
orientdb> select in.out from Address where name = ‘Rome’
---+------+---------|--------------------+--------------------+--------+
#| RID |@class |label |out |in |
---+------+---------+--------------------+--------------------+--------+
0| 13:35|Customer |Luca |[#14:54] | |
---+------+---------+--------------------+--------------------+--------+
1 item(s) found. Query executed in 0.007 sec(s).
Incoming vertices
(c) Luca Garulli Licensed under a Creative Commons Attribution-NoDerivs 3.0 Unported License Page 43](https://image.slidesharecdn.com/ayb-switchingfromrelational2graph-121123135852-phpapp02/85/Switching-from-relational-to-the-graph-model-43-320.jpg)


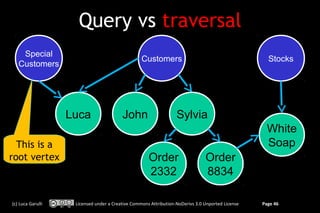

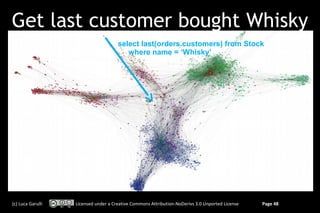







The document discusses switching from a relational database model to a graph database model. It begins with an overview of common objections to adopting NoSQL databases due to complexity of data modeling. It then provides a brief introduction to key-value stores, column-based databases, and document databases before arguing that graph databases are well-suited to complex domains. The remainder of the document focuses on explaining the graph database model and how it differs from and improves upon the relational model for managing relationships through index-free adjacency rather than joins. Code examples are provided for creating a simple graph representing customer and address data using the OrientDB graph database.











































![[20160813, PyCon2016APAC] 뉴스를 재미있게 만드는 방법; 뉴스잼](https://cdn.slidesharecdn.com/ss_thumbnails/random-160813075211-thumbnail.jpg?width=640&height=640&fit=bounds)

























































