Download as PDF, PPTX





























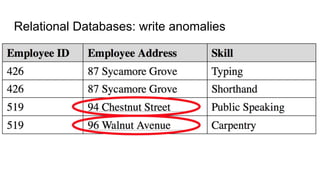





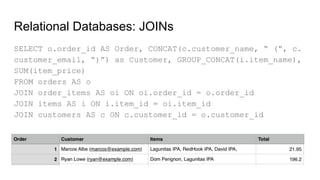



























































































































































![● Lucene based
● Quite cryptic query interface - Innovator’s Dilemma
● Support for SQL based query on 6.1
● Structured schema, data types needs to be predefined
● Written in Java, JVM limitation applies i.e. GC
● Near realtime indexing - DIH,
● Rich document handling - PDF, doc[x]
● SolrCloud support for sharding and replication
Fulltext Search: Solr](https://image.slidesharecdn.com/heterogeneouspersistence-160422055632/85/Heterogenous-Persistence-194-320.jpg)
![● Lucene based
● Quite cryptic query interface - Innovator’s Dilemma
● Support for SQL based query on 6.1
● Structured schema, data types needs to be predefined
● Written in Java, JVM limitation applies i.e. GC
● Near realtime indexing - DIH,
● Rich document handling - PDF, doc[x]
● SolrCloud support for sharding and replication
Fulltext Search: Solr](https://image.slidesharecdn.com/heterogeneouspersistence-160422055632/85/Heterogenous-Persistence-195-320.jpg)
![● Lucene based
● Quite cryptic query interface - Innovator’s Dilemma
● Support for SQL based query on 6.1
● Structured schema, data types needs to be predefined
● Written in Java, JVM limitation applies i.e. GC
● Near realtime indexing - DIH,
● Rich document handling - PDF, doc[x]
● SolrCloud support for sharding and replication
Fulltext Search: Solr](https://image.slidesharecdn.com/heterogeneouspersistence-160422055632/85/Heterogenous-Persistence-196-320.jpg)
![● Lucene based
● Quite cryptic query interface - Innovator’s Dilemma
● Support for SQL based query on 6.1
● Structured schema, data types needs to be predefined
● Written in Java, JVM limitation applies i.e. GC
● Near realtime indexing - DIH,
● Rich document handling - PDF, doc[x]
● SolrCloud support for sharding and replication
Fulltext Search: Solr](https://image.slidesharecdn.com/heterogeneouspersistence-160422055632/85/Heterogenous-Persistence-197-320.jpg)
![● Lucene based
● Quite cryptic query interface - Innovator’s Dilemma
● Support for SQL based query on 6.1
● Structured schema, data types needs to be predefined
● Written in Java, JVM limitation applies i.e. GC
● Near realtime indexing - DIH,
● Rich document handling - PDF, doc[x]
● SolrCloud support for sharding and replication
Fulltext Search: Solr](https://image.slidesharecdn.com/heterogeneouspersistence-160422055632/85/Heterogenous-Persistence-198-320.jpg)
![● Lucene based
● Quite cryptic query interface - Innovator’s Dilemma
● Support for SQL based query on 6.1
● Structured schema, data types needs to be predefined
● Written in Java, JVM limitation applies i.e. GC
● Near real-time indexing - DIH,
● Rich document handling - PDF, doc[x]
● SolrCloud support for sharding and replication
Fulltext Search: Solr](https://image.slidesharecdn.com/heterogeneouspersistence-160422055632/85/Heterogenous-Persistence-199-320.jpg)
![● Lucene based
● Quite cryptic query interface - Innovator’s Dilemma
● Support for SQL based query on 6.1
● Structured schema, data types needs to be predefined
● Written in Java, JVM limitation applies i.e. GC
● Near realtime indexing - DIH,
● Rich document handling - PDF, doc[x]
● SolrCloud support for sharding and replication
Fulltext Search: Solr](https://image.slidesharecdn.com/heterogeneouspersistence-160422055632/85/Heterogenous-Persistence-200-320.jpg)
![● Lucene based
● Quite cryptic query interface - Innovator’s Dilemma
● Support for SQL based query on 6.1
● Structured schema, data types needs to be predefined
● Written in Java, JVM limitation applies i.e. GC
● Near realtime indexing - DIH,
● Rich document handling - PDF, doc[x]
● SolrCloud support for sharding and replication
Fulltext Search: Solr](https://image.slidesharecdn.com/heterogeneouspersistence-160422055632/85/Heterogenous-Persistence-201-320.jpg)



![● Structured data
● MySQL protocol - SphinxQL
● Durable indexes via binary logs
● Realtime indexes via MySQL queries
● Distributed index for scaling
● No native support for replication i.e. via rsync
● Very good documentation
● Fastest full indexing/reindexing [?]
Fulltext Search: Sphinx Search](https://image.slidesharecdn.com/heterogeneouspersistence-160422055632/85/Heterogenous-Persistence-205-320.jpg)
![● Structured data
● MySQL protocol - SphinxQL
● Durable indexes via binary logs
● Realtime indexes via MySQL queries
● Distributed index for scaling
● No native support for replication i.e. via rsync
● Very good documentation
● Fastest full indexing/reindexing [?]
Fulltext Search: Sphinx Search](https://image.slidesharecdn.com/heterogeneouspersistence-160422055632/85/Heterogenous-Persistence-206-320.jpg)
![● Structured data
● MySQL protocol - SphinxQL
● Durable indexes via binary logs
● Realtime indexes via MySQL queries
● Distributed index for scaling
● No native support for replication i.e. via rsync
● Very good documentation
● Fastest full indexing/reindexing [?]
Fulltext Search: Sphinx Search](https://image.slidesharecdn.com/heterogeneouspersistence-160422055632/85/Heterogenous-Persistence-207-320.jpg)
![● Structured data
● MySQL protocol - SphinxQL
● Durable indexes via binary logs
● Realtime indexes via MySQL queries
● Distributed index for scaling
● No native support for replication i.e. via rsync
● Very good documentation
● Fastest full indexing/reindexing [?]
Fulltext Search: Sphinx Search](https://image.slidesharecdn.com/heterogeneouspersistence-160422055632/85/Heterogenous-Persistence-208-320.jpg)
![● Structured data
● MySQL protocol - SphinxQL
● Durable indexes via binary logs
● Realtime indexes via MySQL queries
● Distributed index for scaling
● No native support for replication i.e. via rsync
● Very good documentation
● Fastest full indexing/reindexing [?]
Fulltext Search: Sphinx Search](https://image.slidesharecdn.com/heterogeneouspersistence-160422055632/85/Heterogenous-Persistence-209-320.jpg)
![● Structured data
● MySQL protocol - SphinxQL
● Durable indexes via binary logs
● Realtime indexes via MySQL queries
● Distributed index for scaling
● No native support for replication i.e. via rsync
● Very good documentation
● Fastest full indexing/reindexing [?]
Fulltext Search: Sphinx Search](https://image.slidesharecdn.com/heterogeneouspersistence-160422055632/85/Heterogenous-Persistence-210-320.jpg)
![● Structured data
● MySQL protocol - SphinxQL
● Durable indexes via binary logs
● Realtime indexes via MySQL queries
● Distributed index for scaling
● No native support for replication i.e. via rsync
● Very good documentation
● Fastest full indexing/reindexing [?]
Fulltext Search: Sphinx Search](https://image.slidesharecdn.com/heterogeneouspersistence-160422055632/85/Heterogenous-Persistence-211-320.jpg)











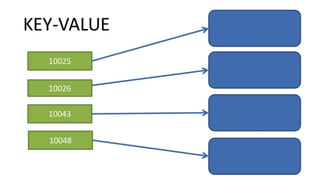
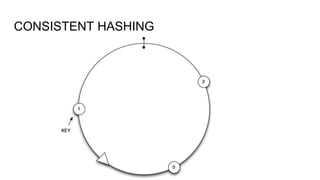
This document provides an overview of heterogeneous persistence and different database management systems (DBMS). It discusses why a single DBMS is often not sufficient and describes different types of DBMS including relational databases, key-value stores, and columnar databases. For each type, it outlines good and bad use cases, examples, considerations, and pros and cons. The document aims to help readers understand the different flavors of DBMS and how to choose the right ones for their specific data and access needs.
















































































![[DSC Europe 25] Stefan Brankovic - #ResumeIsDead. AI-Powered Interviews and C...](https://cdn.slidesharecdn.com/ss_thumbnails/qnmbsv0xq3uysdrq3sev-2-stefan-brankovic-job-bolt-260114111931-a065aa3d-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Elena Menshikova - AI-Powered Operational Excellence: Revolut...](https://cdn.slidesharecdn.com/ss_thumbnails/es6nholbqy3zaao2c2yd-2-elena-menshikova-data-ai-in-decision-making-260115093812-4fba8b38-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Nikola Vasiljevic - Player segmentation by combat playstyles ...](https://cdn.slidesharecdn.com/ss_thumbnails/mnvbf0yvrwaqsipzrrv3-2-nikola-vasiljevic-player-segmentation-by-playstyles-in-action-shooter-games-260114111931-b4d766cd-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DSC Europe 25] Mijat Kustudic - Building Financial Intelligence with AI Agen...](https://cdn.slidesharecdn.com/ss_thumbnails/38y2lb5lse6wstegtvas-3-mijat-kustudic-building-financial-intelligence-with-ai-agents-260114111931-1a4783ce-thumbnail.jpg?width=640&height=640&fit=bounds)




