Download to read offline








![13
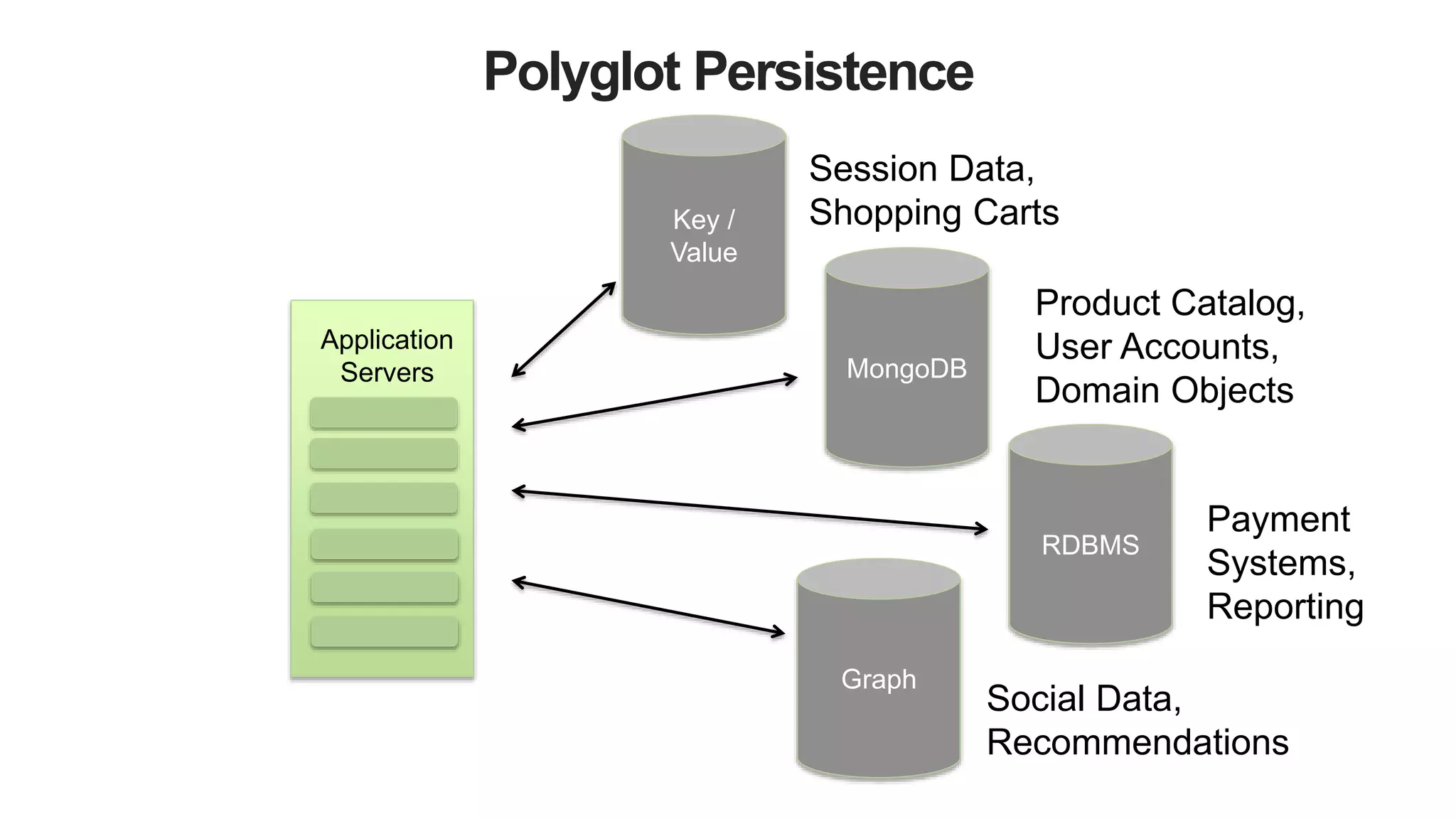
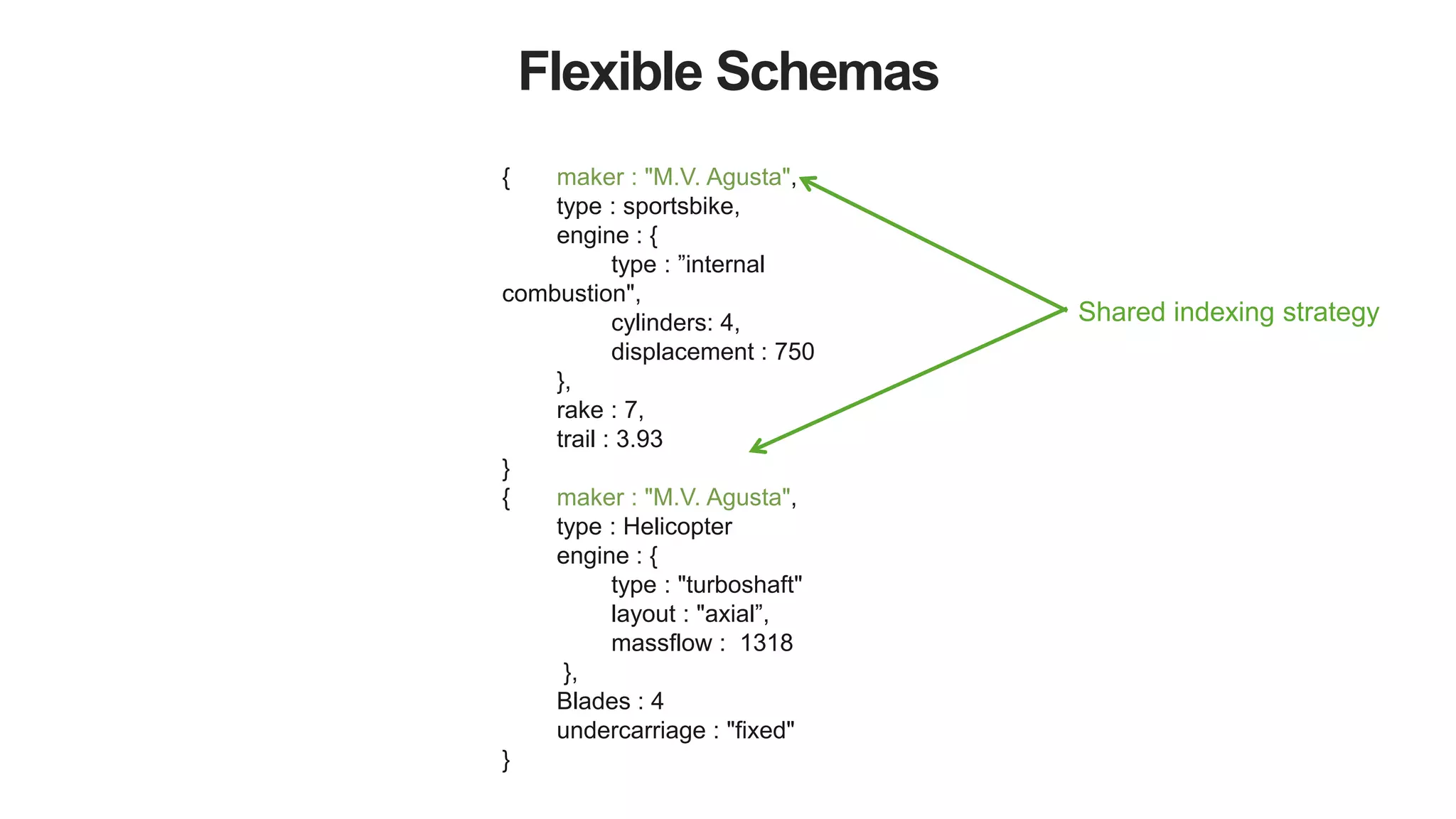
Variant Data Models
Document Databases
{
maker : ”Agusta",
type : sportbike,
rake : 7,
trail : 3.93,
engine : {
type : "internal combustion",
layout : "inline"
cylinders : 4,
displacement : 750,
},
transmission : {
type : "cassette",
speeds : 6,
pattern : "sequential”,
ratios : [ 2.7, 1.94, 1.34, 1, 0.83, 0.64
]
}
}](https://image.slidesharecdn.com/polyglotpersistence-150912232116-lva1-app6892/75/Polyglot-Persistence-13-2048.jpg)
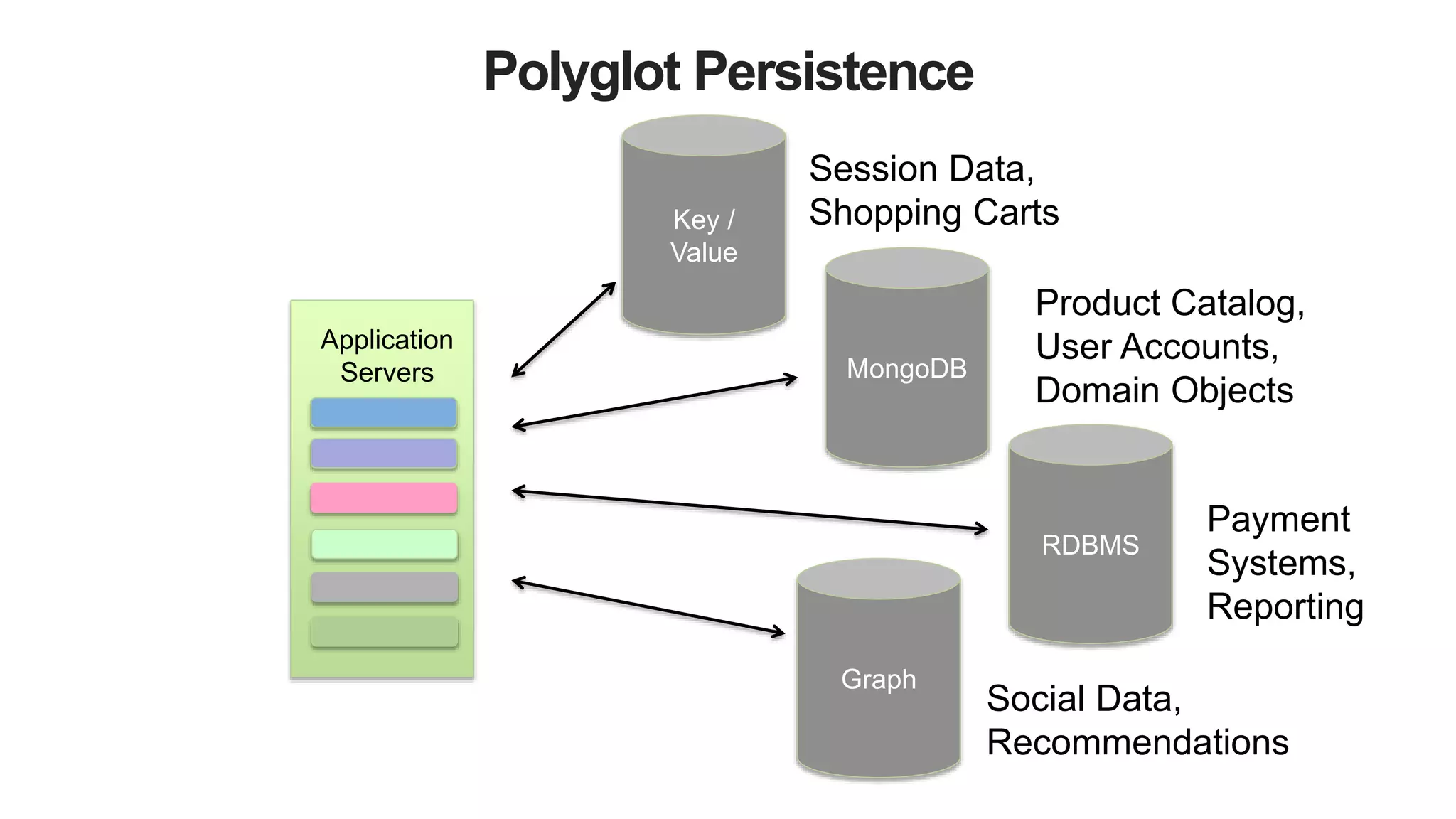




![Key Value Store
“{
maker : ‘Agusta’,
type : sportbike,
rake : 7,
trail : 3.93,
engine : {
type : ‘internal combustion’,
layout : ‘inline’,
cylinders : 4,
displacement : 750,
},
transmission : {
type : ‘cassette’,
speeds : 6,
pattern : ‘sequential’,
ratios : [ 2.7, 1.94, 1.34, 1, 0.83, 0.64 ]
}
}”](https://image.slidesharecdn.com/polyglotpersistence-150912232116-lva1-app6892/75/Polyglot-Persistence-20-2048.jpg)
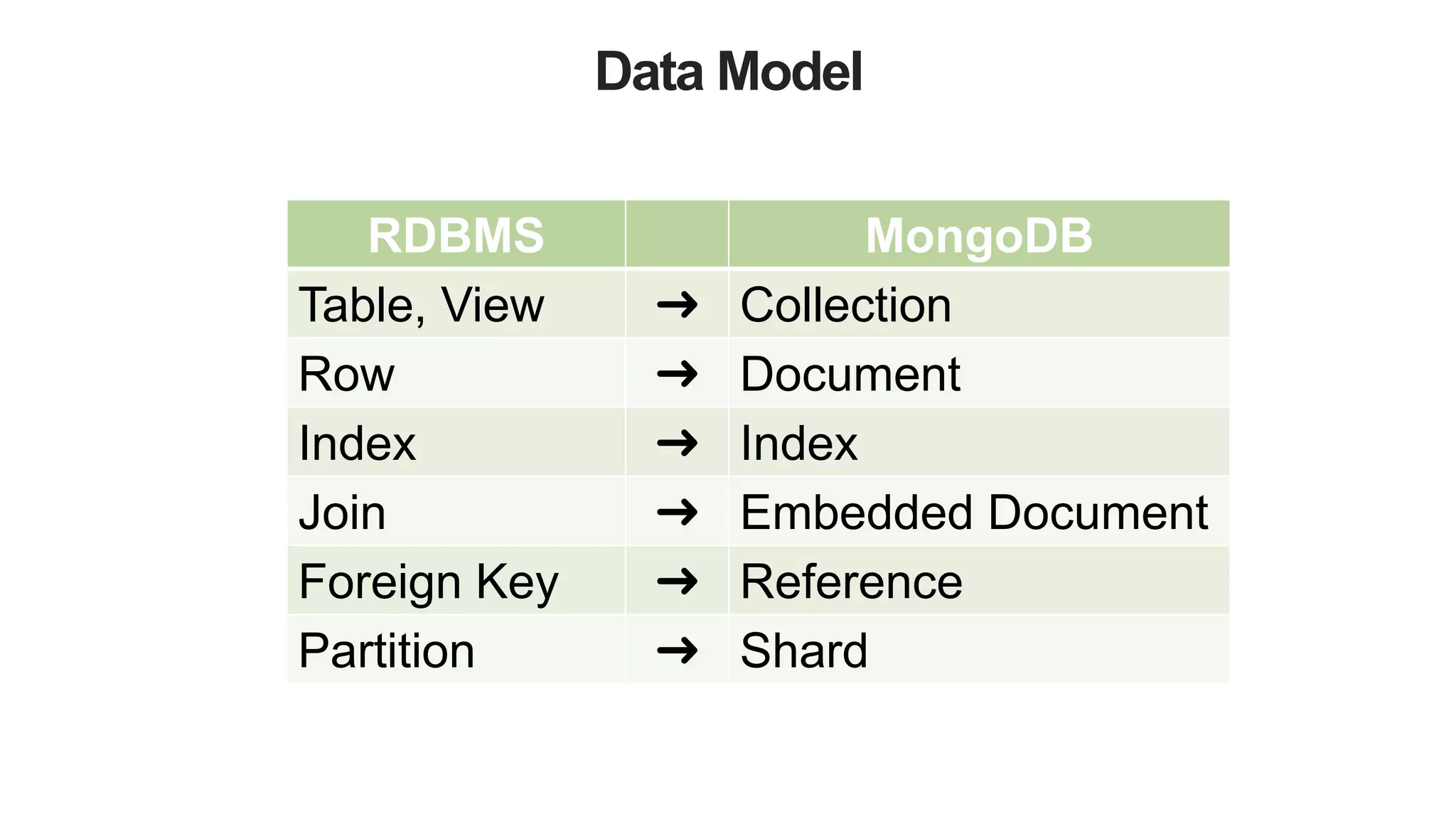
![MongoDB
{ _id: 78234974,
maker : ”Agusta",
type : sportbike,
rake : 7,
trail : 3.93,
engine : {
type : "internal combustion",
layout : "inline"
cylinders : 4,
displacement : 750,
},
transmission : {
type : "cassette",
speeds : 6,
pattern : "sequential”,
ratios : [ 2.7, 1.94, 1.34, 1, 0.83, 0.64 ]
}
}
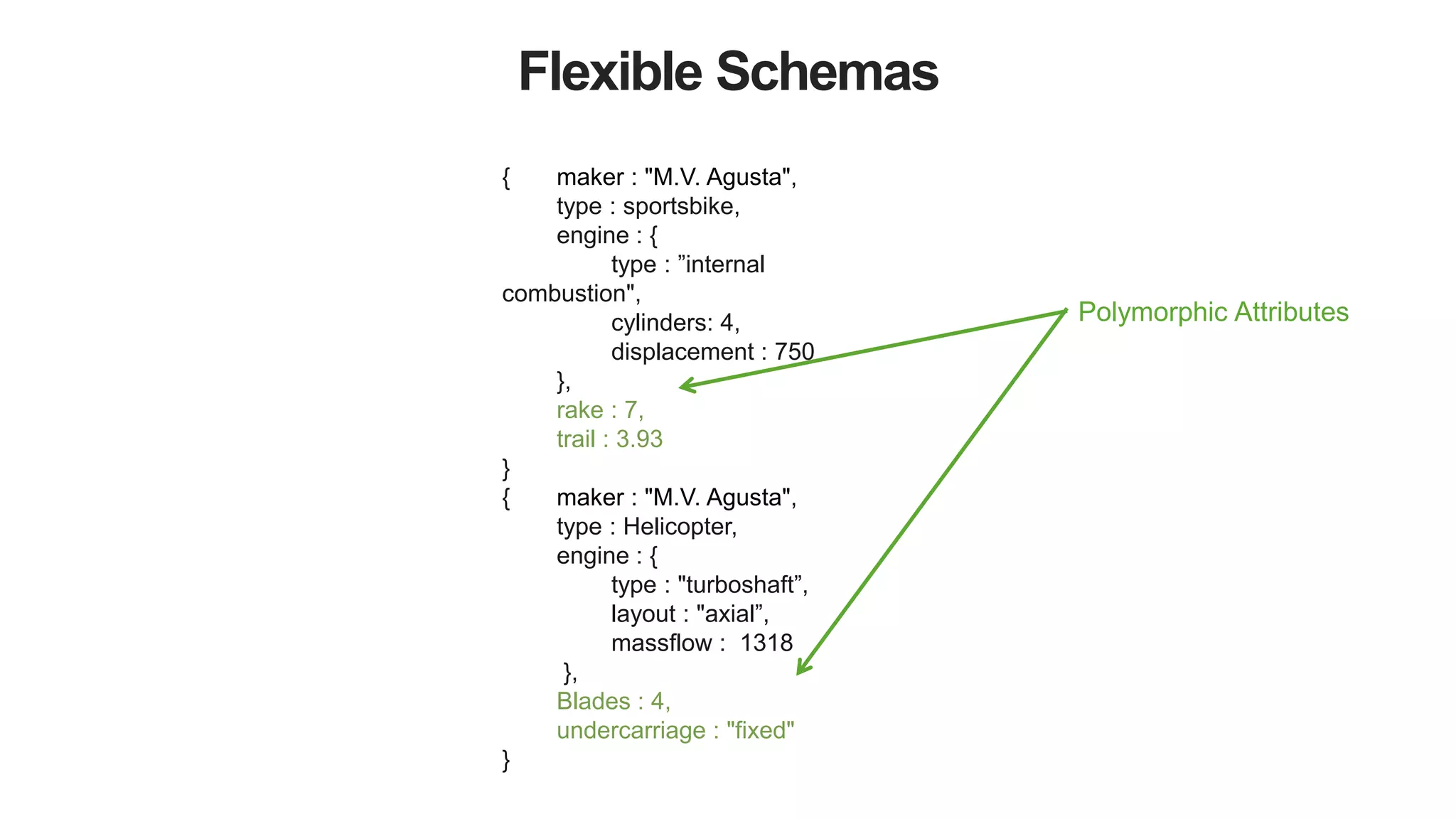
Self Defining Schema](https://image.slidesharecdn.com/polyglotpersistence-150912232116-lva1-app6892/75/Polyglot-Persistence-22-2048.jpg)
![MongoDB
{ _id: 78234974,
maker : ”Agusta",
type : sportbike,
rake : 7,
trail : 3.93,
engine : {
type : "internal combustion",
layout : "inline"
cylinders : 4,
displacement : 750,
},
transmission : {
type : "cassette",
speeds : 6,
pattern : "sequential”,
ratios : [ 2.7, 1.94, 1.34, 1, 0.83, 0.64 ]
}
}
Self Defining Schema
Nested Objects](https://image.slidesharecdn.com/polyglotpersistence-150912232116-lva1-app6892/75/Polyglot-Persistence-23-2048.jpg)
![MongoDB
{ _id: 78234974,
maker : ”Agusta",
type : sportbike,
rake : 7,
trail : 3.93,
engine : {
type : "internal combustion",
layout : "inline"
cylinders : 4,
displacement : 750,
},
transmission : {
type : "cassette",
speeds : 6,
pattern : "sequential”,
ratios : [ 2.7, 1.94, 1.34, 1, 0.83, 0.64 ]
}
}
Self Defining Schema
Nested Objects
Array types](https://image.slidesharecdn.com/polyglotpersistence-150912232116-lva1-app6892/75/Polyglot-Persistence-24-2048.jpg)
![MongoDB
{ _id: 78234974,
maker : ”Agusta",
type : sportbike,
rake : 7,
trail : 3.93,
engine : {
type : "internal combustion",
layout : "inline"
cylinders : 4,
displacement : 750,
},
transmission : {
type : "cassette",
speeds : 6,
pattern : "sequential”,
ratios : [ 2.7, 1.94, 1.34, 1, 0.83, 0.64 ]
}
}
Primary Key,
Auto indexed](https://image.slidesharecdn.com/polyglotpersistence-150912232116-lva1-app6892/75/Polyglot-Persistence-25-2048.jpg)
![Multiple Access Patterns
{ _id: 78234974,
maker : ”Agusta",
type : sportbike,
rake : 7,
trail : 3.93,
engine : {
type : "internal combustion",
layout : "inline"
cylinders : 4,
displacement : 750,
},
transmission : {
type : "cassette",
speeds : 6,
pattern : "sequential”,
ratios : [ 2.7, 1.94, 1.34, 1, 0.83, 0.64 ]
}
}
Secondary
indexes](https://image.slidesharecdn.com/polyglotpersistence-150912232116-lva1-app6892/75/Polyglot-Persistence-26-2048.jpg)
![Projections
{ _id: 78234974,
maker : ”Agusta",
type : sportbike,
rake : 7,
trail : 3.93,
engine : {
type : "internal combustion",
layout : "inline"
cylinders : 4,
displacement : 750,
},
transmission : {
type : "cassette",
speeds : 6,
pattern : "sequential”,
ratios : [ 2.7, 1.94, 1.34, 1, 0.83, 0.64 ]
}
}
Projections
db.vehicles.find (
{_id:78234974 },
{ engine:1,_id:0 }
)](https://image.slidesharecdn.com/polyglotpersistence-150912232116-lva1-app6892/75/Polyglot-Persistence-27-2048.jpg)


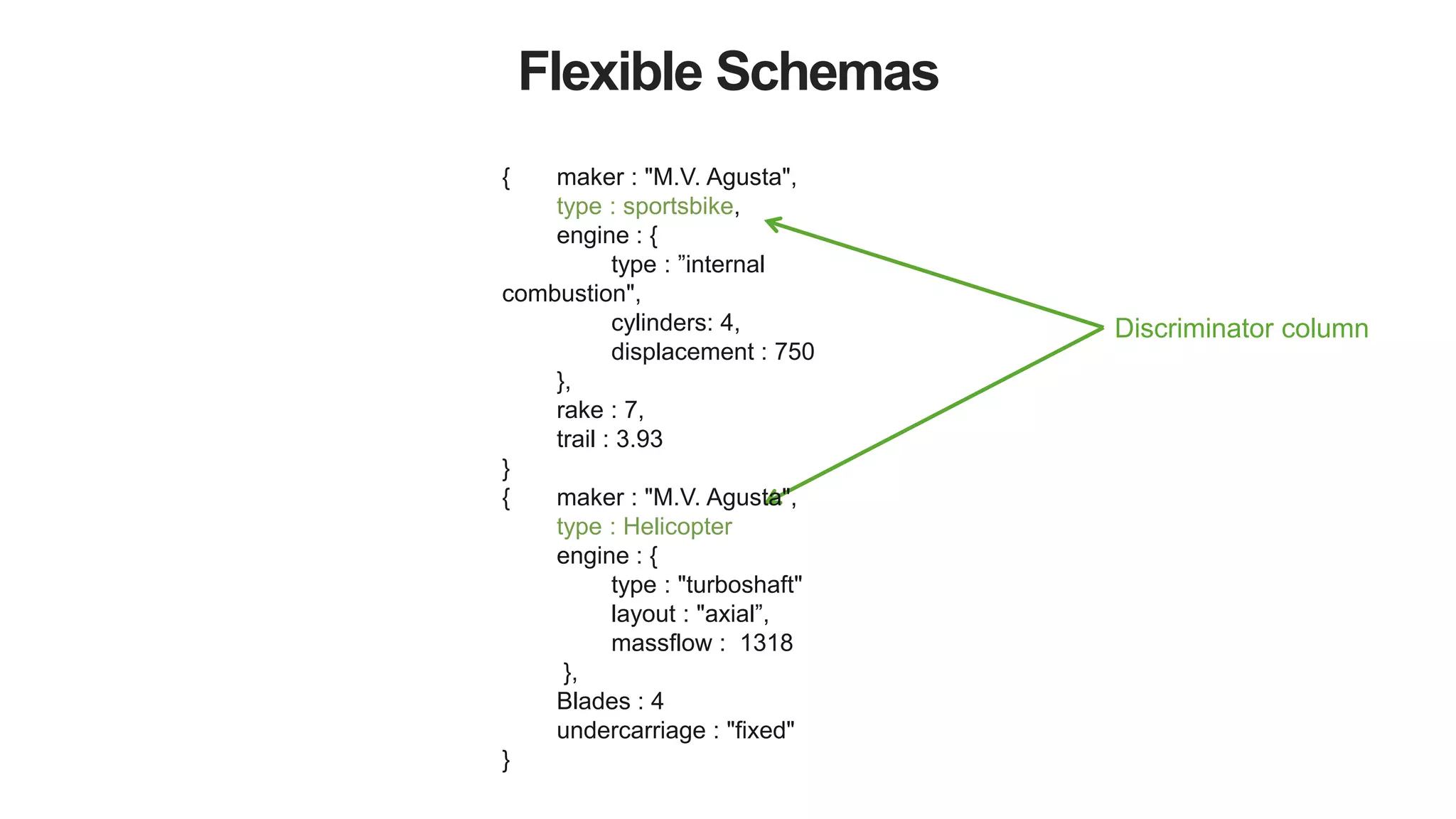






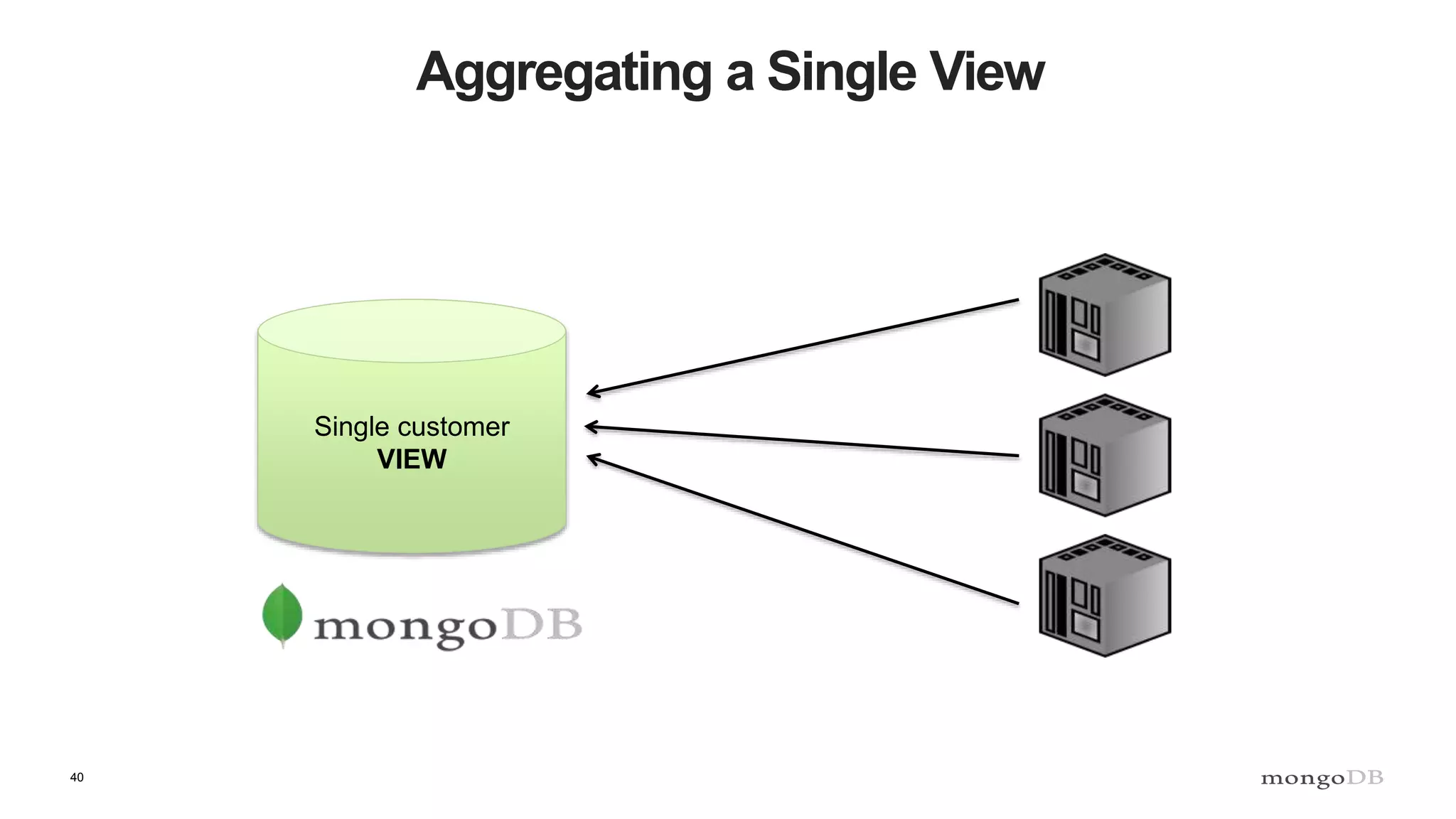
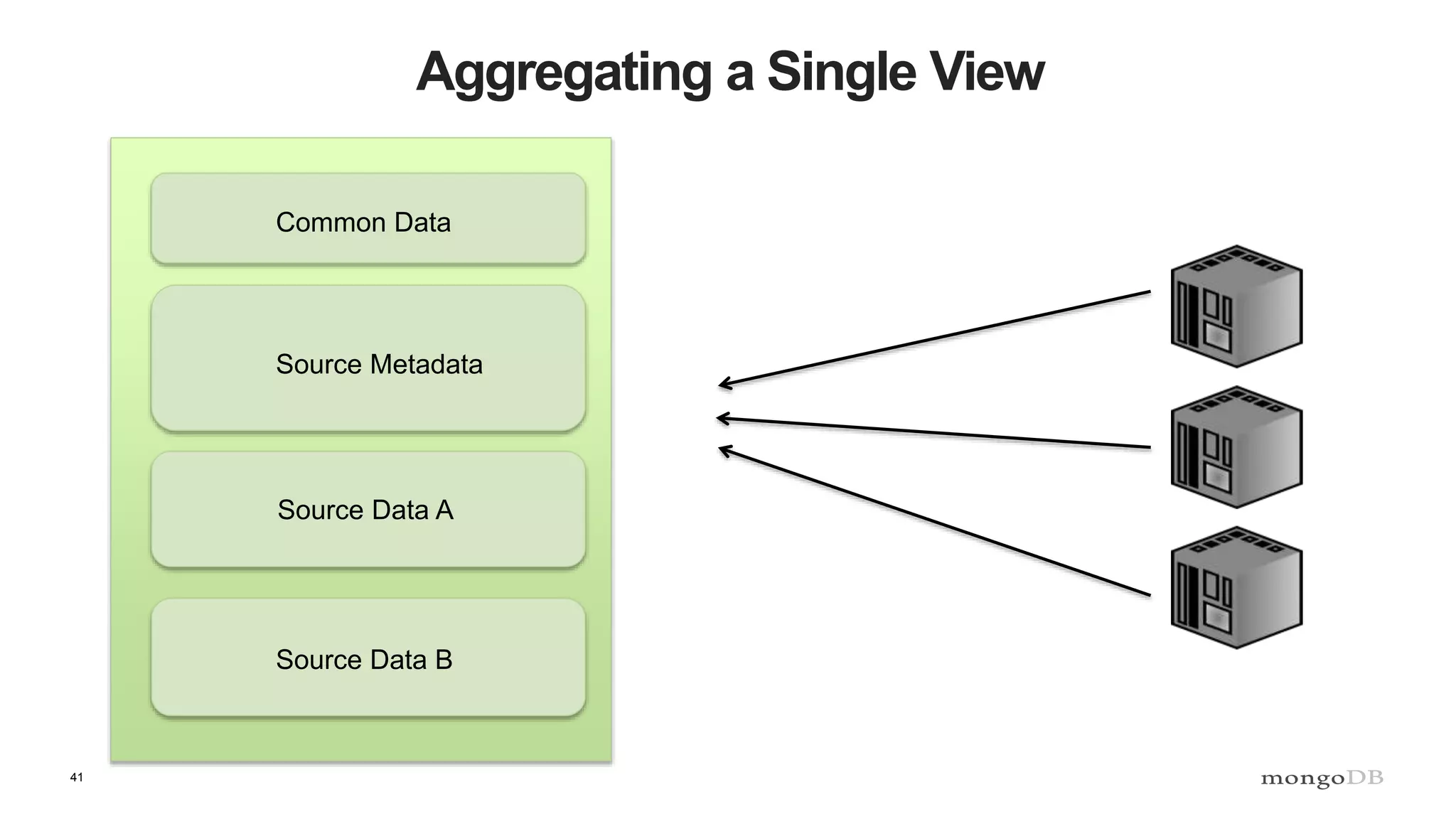
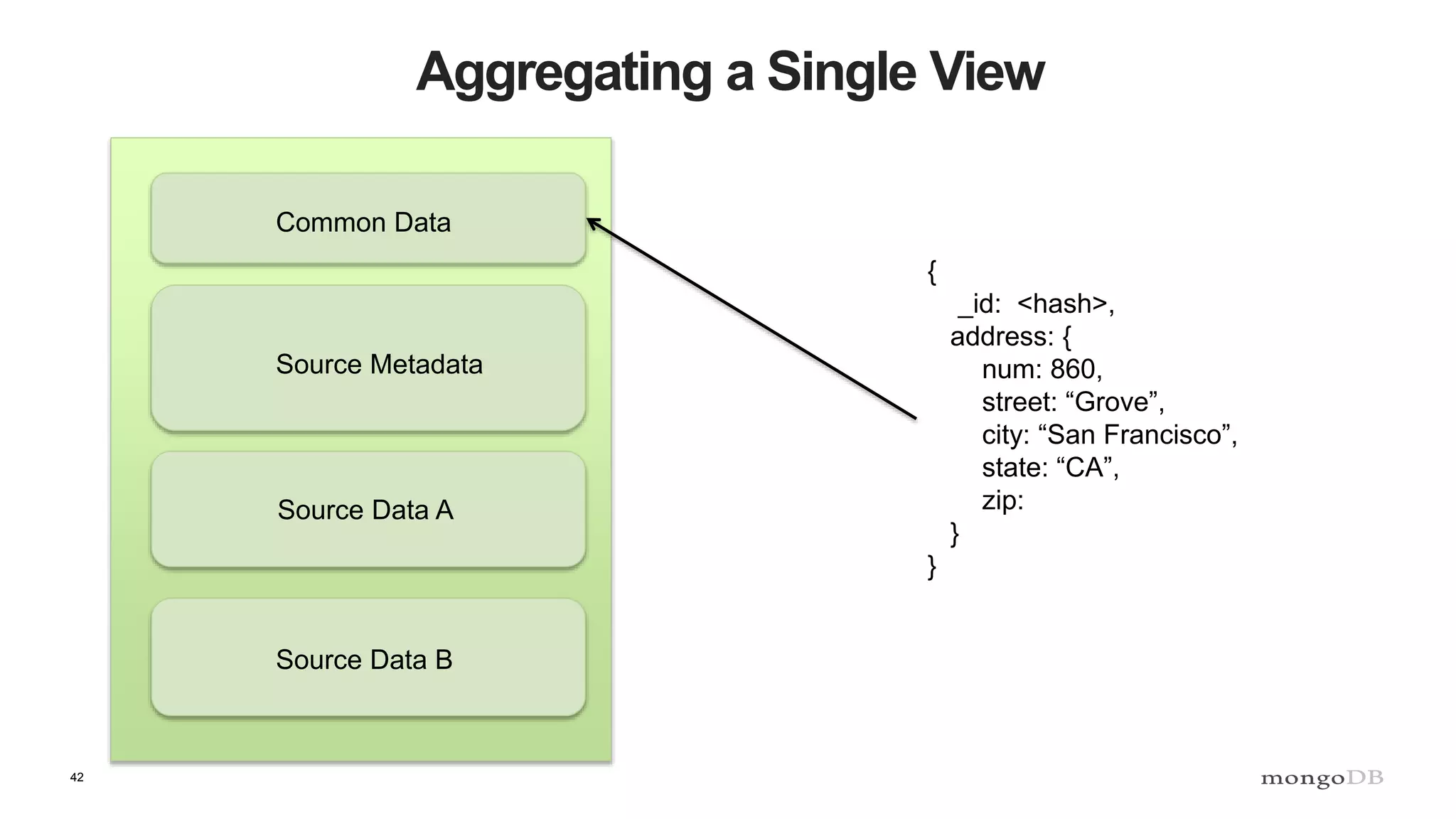
![43
Aggregating a Single View
Common Data
Source Metadata
Source Data A
Source Data B
{
sources: [
{
source: “URI”,
updated: ISODate(),
},
…
]
}](https://image.slidesharecdn.com/polyglotpersistence-150912232116-lva1-app6892/75/Polyglot-Persistence-43-2048.jpg)



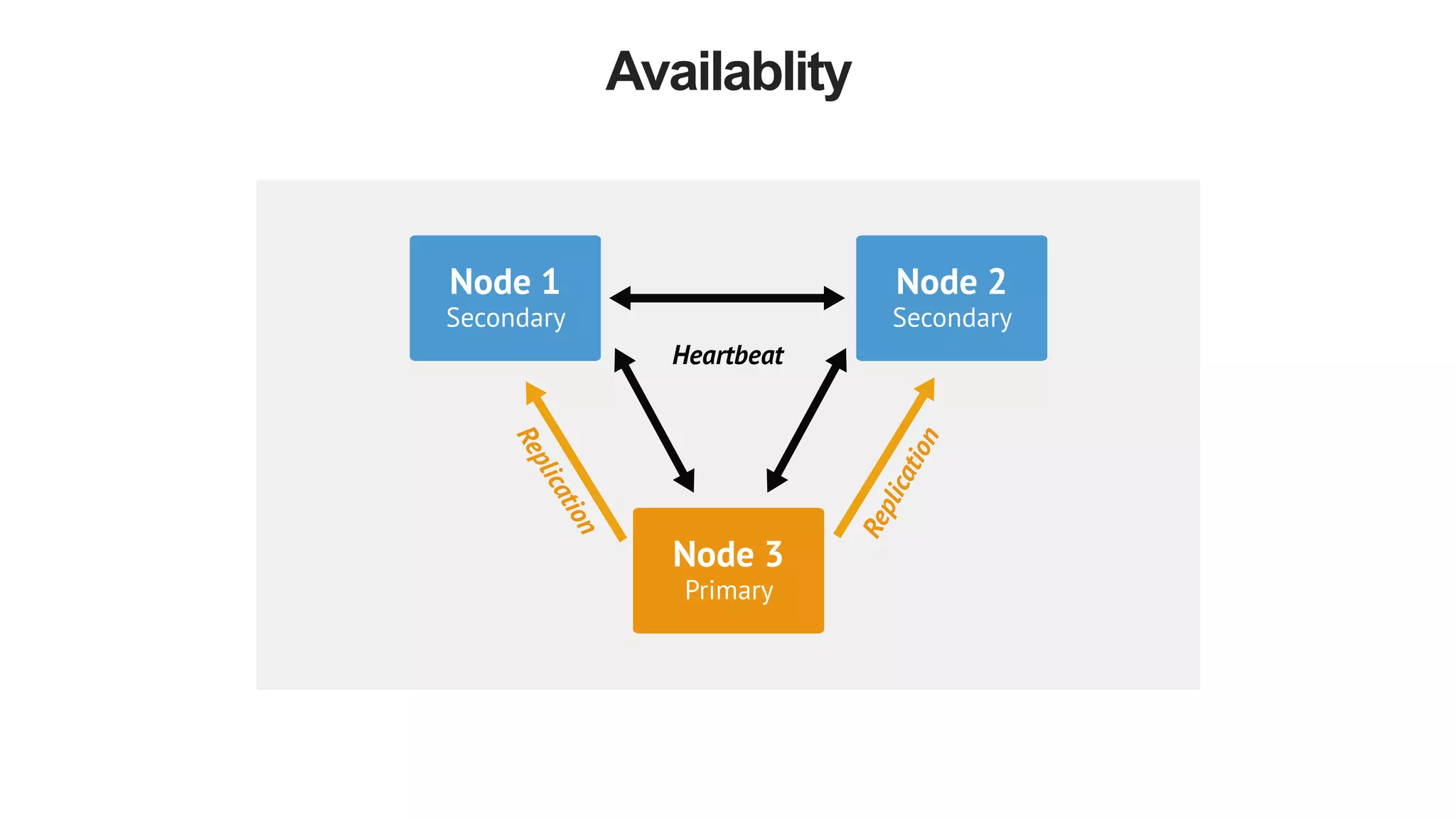
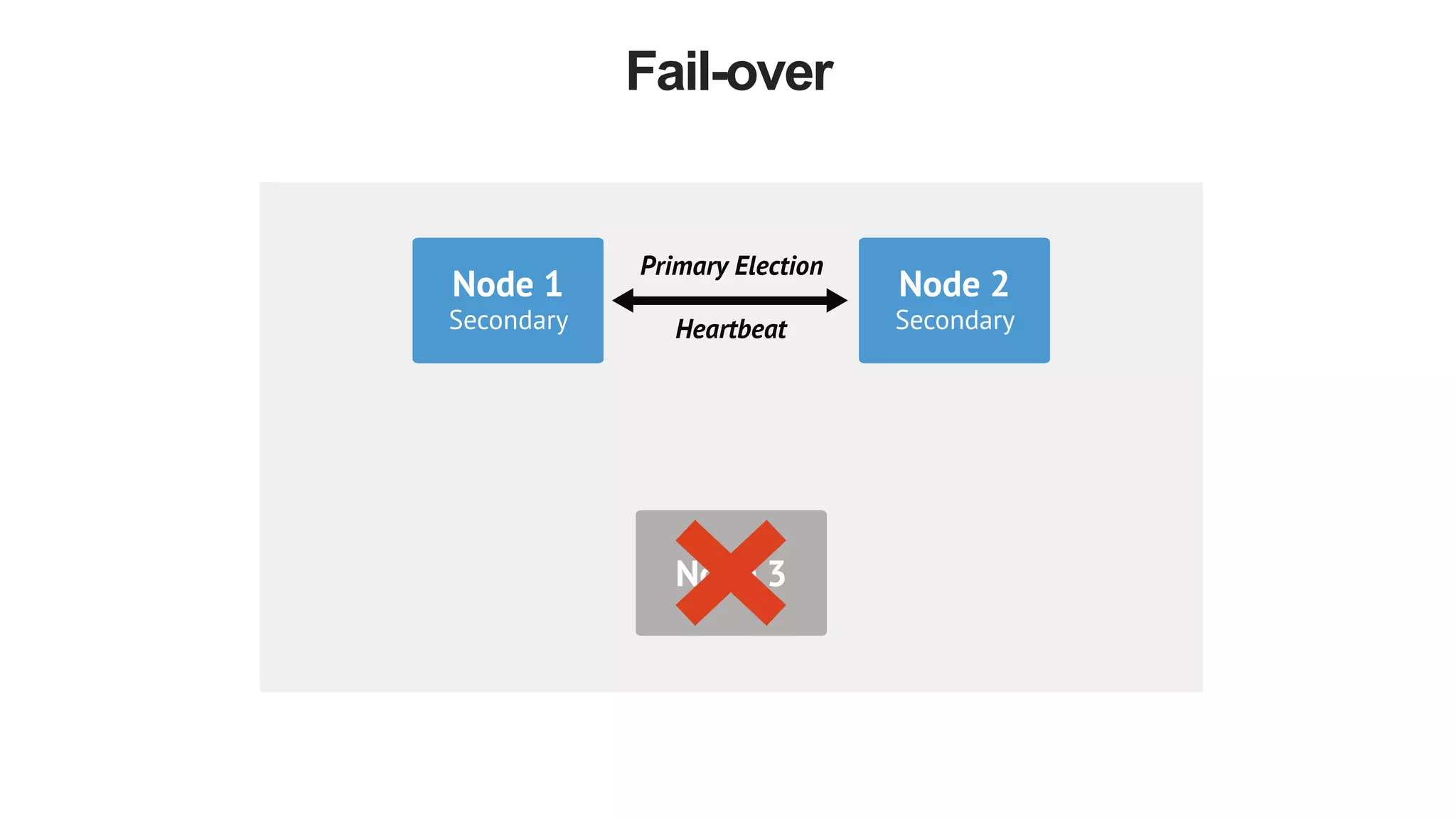
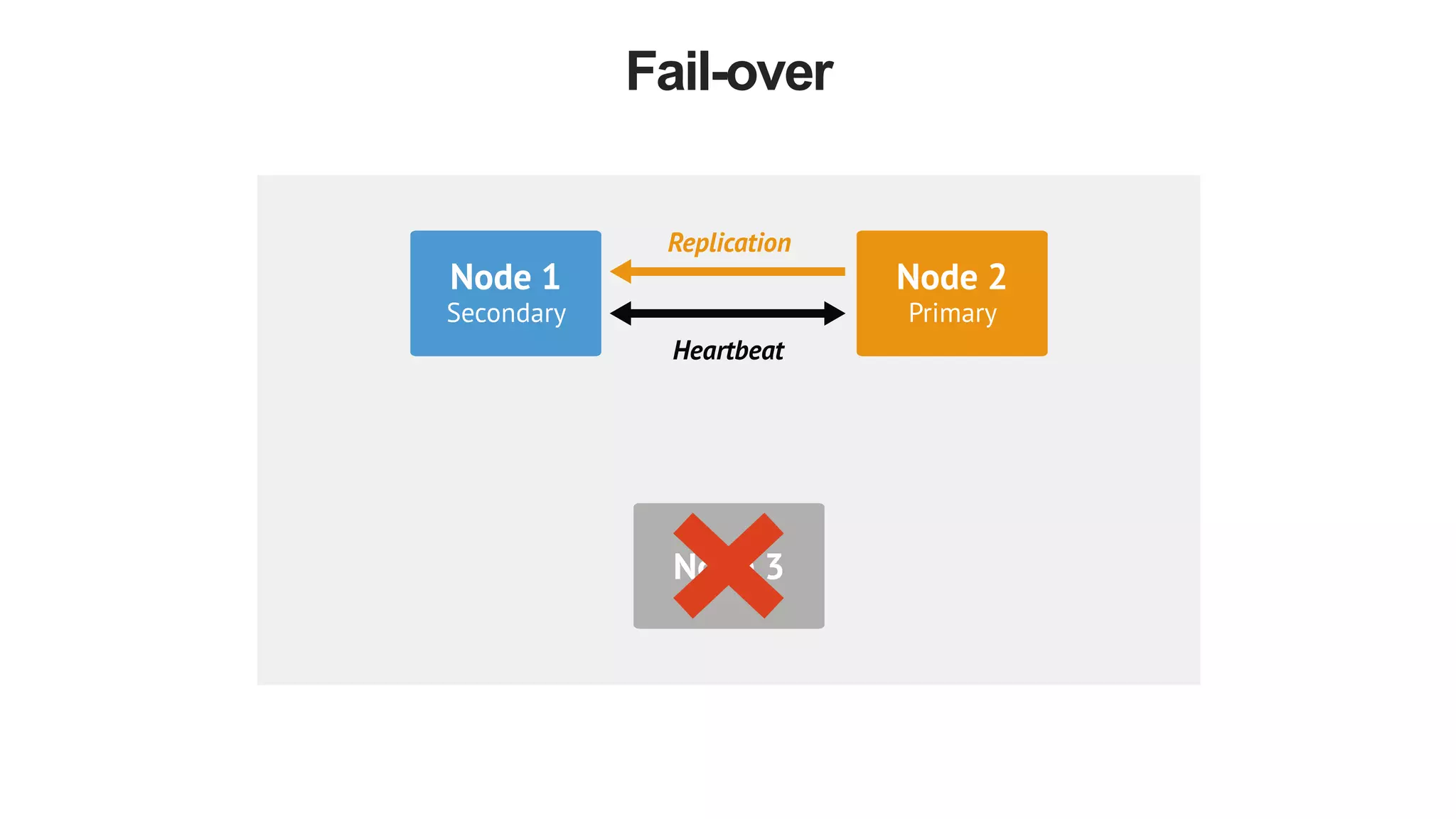







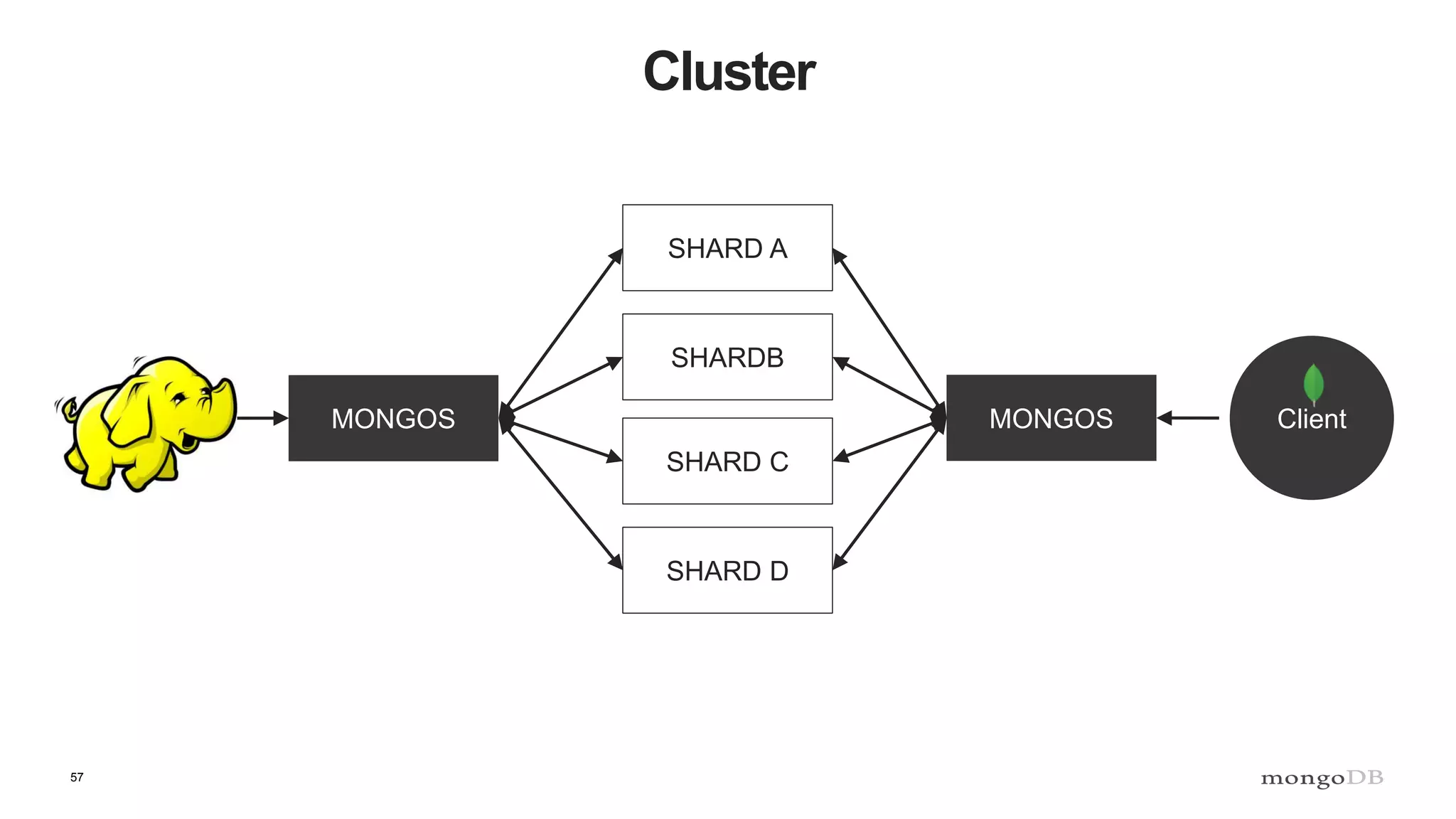



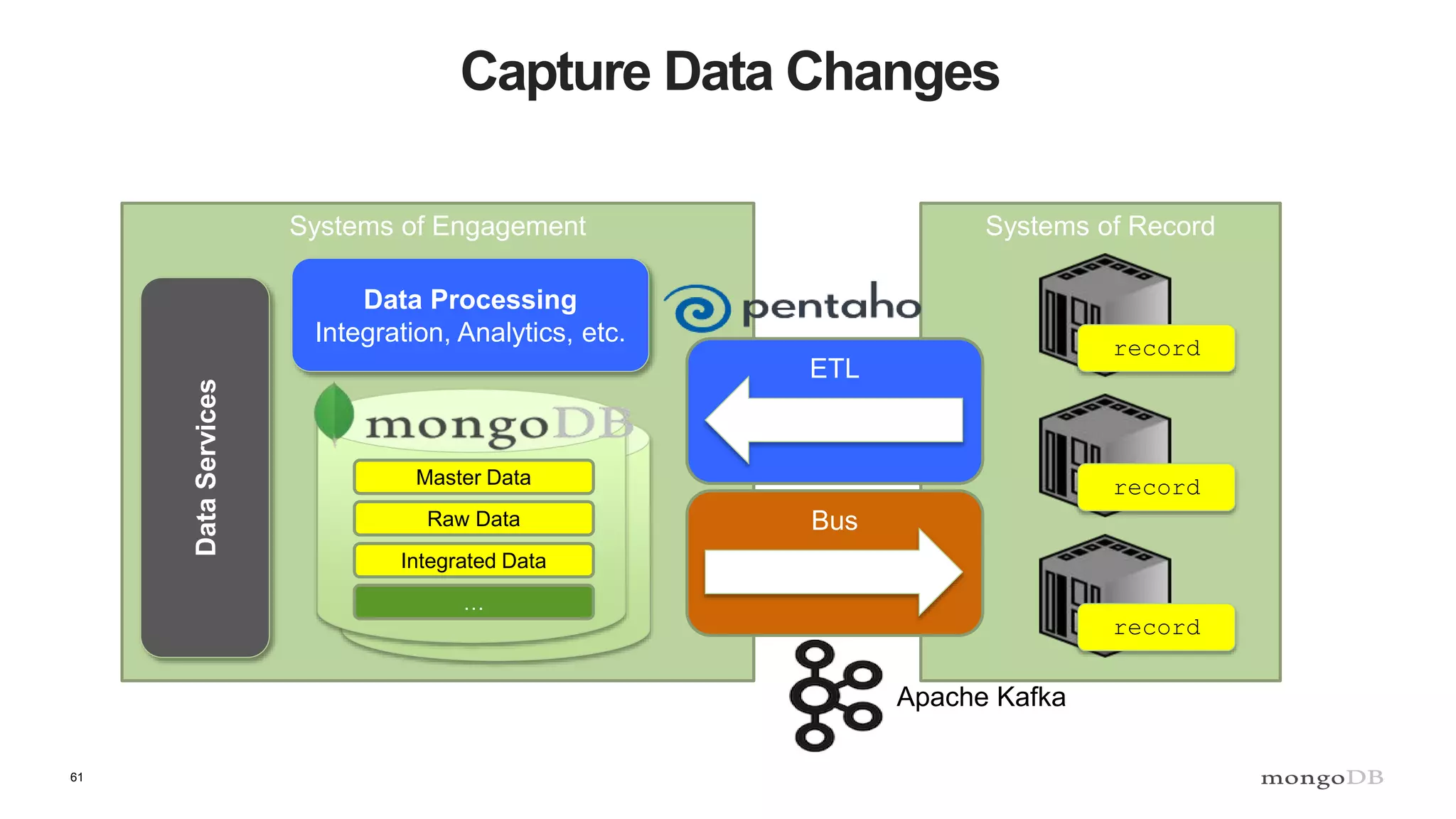
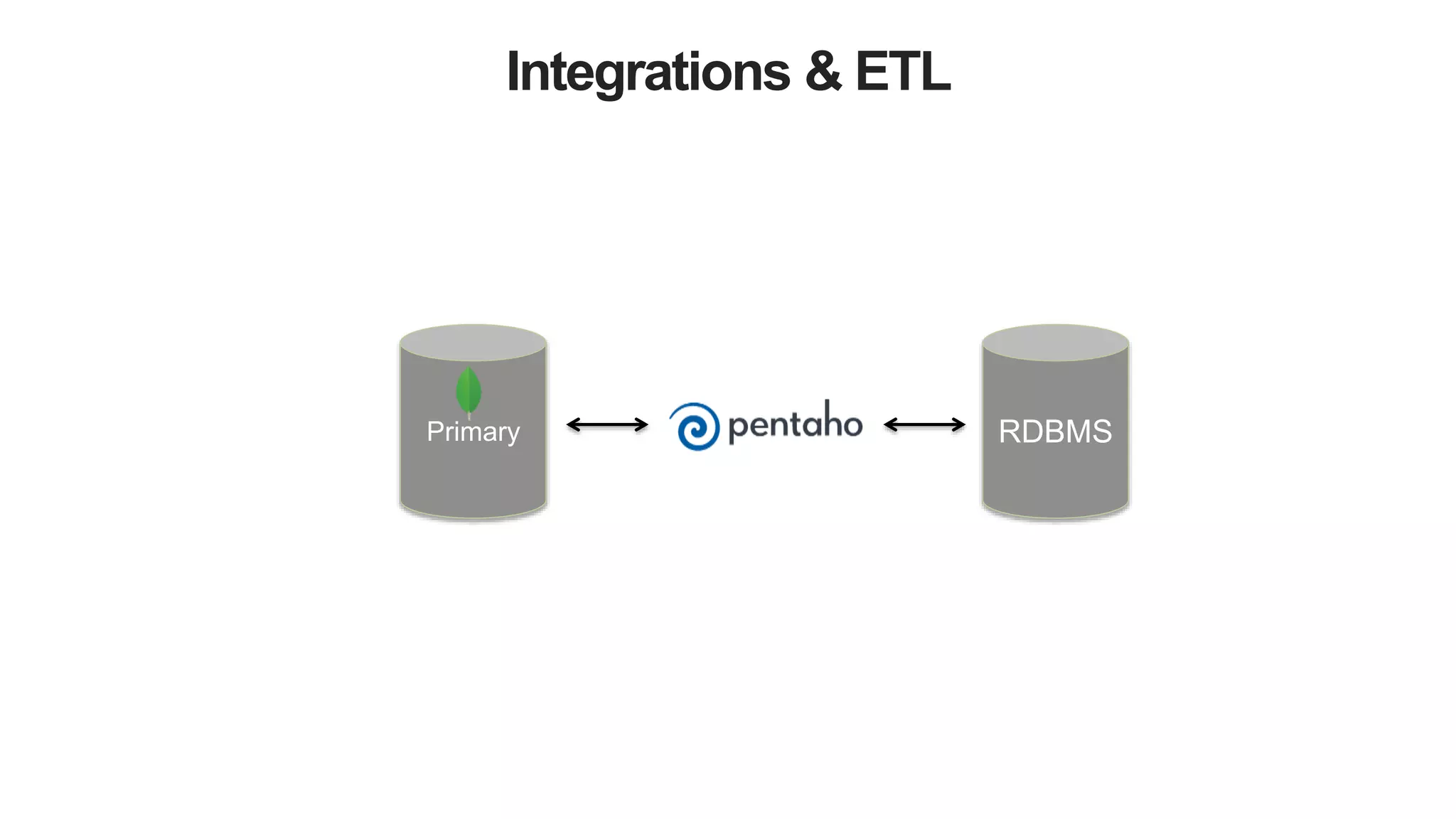
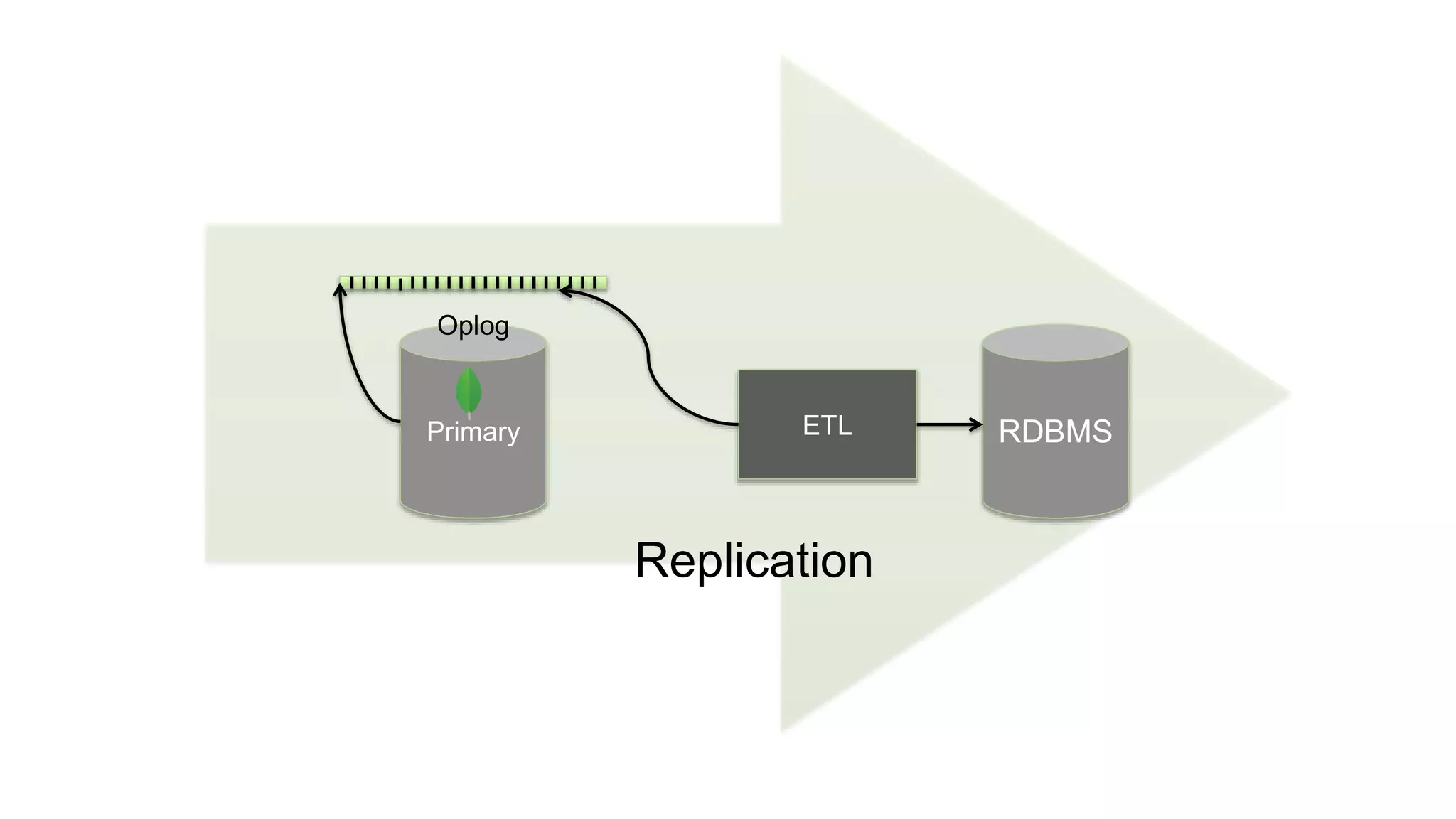
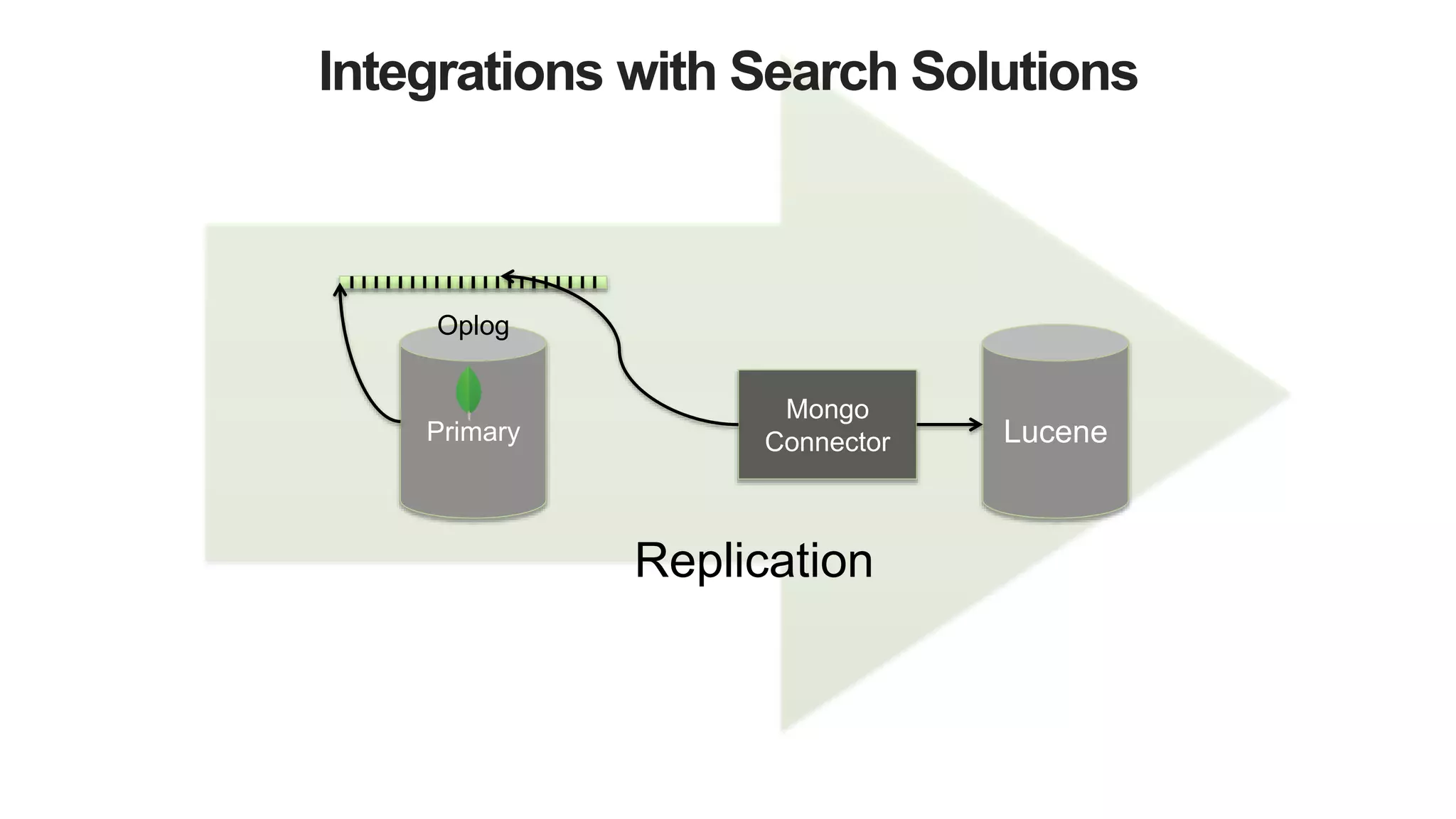



The document discusses polyglot persistence, which involves using multiple database technologies to leverage the right tool for specific application needs. It addresses the transition from traditional relational databases to other data models like key-value, document, and graph databases driven by higher performance requirements and larger datasets. Additionally, it highlights the importance of availability, scalability, and flexible schemas in modern application architecture.




























































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)















