Download as PDF, PPTX









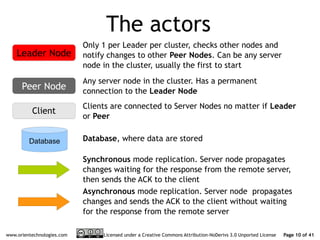



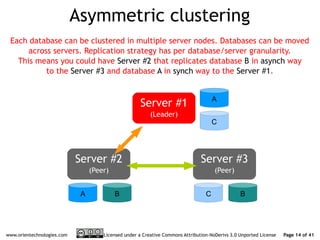
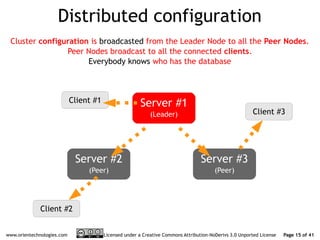

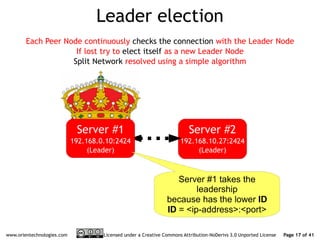
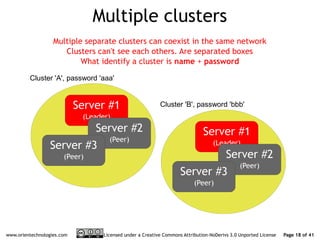
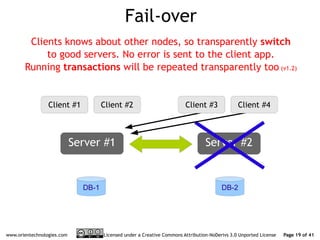


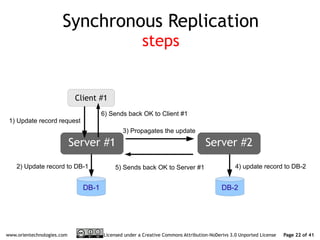

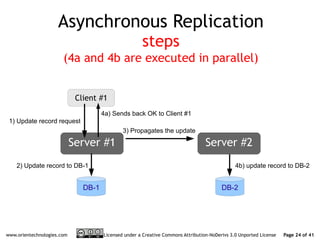

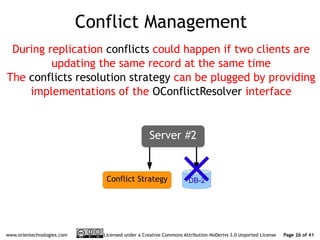
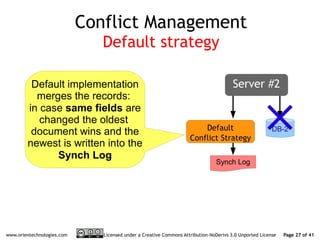



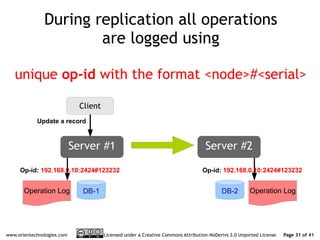
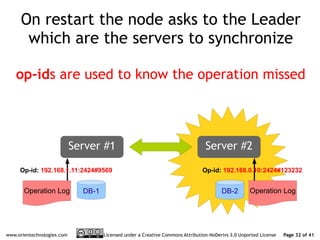

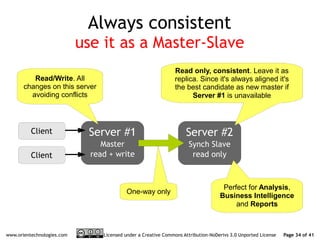
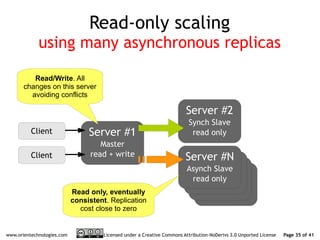
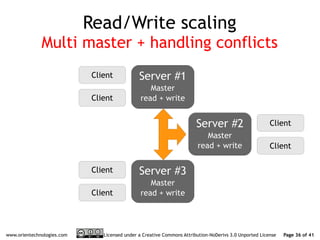
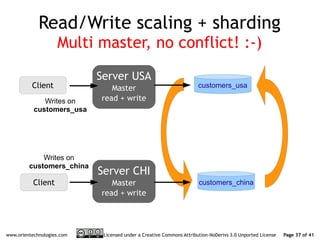





The document discusses OrientDB's transition from a master-slave architecture to a new multi-master distributed architecture. The new architecture allows any node to read and write, improves scalability, and handles conflicts intelligently. It will be released in OrientDB version 1.0 in December 2011.


































































































