Downloaded 242 times






























![Sample Document Structure
Compound, unique
Index identifies the
Individual document
{ _id: ObjectId("5382ccdd58db8b81730344e2"),
segId: "900006",
date: ISODate("2014-03-12T17:00:00Z"),
data: [
{ speed: NaN, time: NaN },
{ speed: NaN, time: NaN },
{ speed: NaN, time: NaN },
...
],
conditions: {
status: "Snow / Ice Conditions",
pavement: "Icy Spots",
weather: "Light Snow"
}
}](https://image.slidesharecdn.com/timeseriesdata-mongodb-webinar-150127130417-conversion-gate01/85/MongoDB-for-Time-Series-Data-41-320.jpg)
![Sample Document Structure
Saves an extra index
{ _id: "900006:14031217",
data: [
{ speed: NaN, time: NaN },
{ speed: NaN, time: NaN },
{ speed: NaN, time: NaN },
...
],
conditions: {
status: "Snow / Ice Conditions",
pavement: "Icy Spots",
weather: "Light Snow"
}
}](https://image.slidesharecdn.com/timeseriesdata-mongodb-webinar-150127130417-conversion-gate01/85/MongoDB-for-Time-Series-Data-43-320.jpg)
![{ _id: "900006:14031217",
data: [
{ speed: NaN, time: NaN },
{ speed: NaN, time: NaN },
{ speed: NaN, time: NaN },
...
],
conditions: {
status: "Snow / Ice Conditions",
pavement: "Icy Spots",
weather: "Light Snow"
}
}
Sample Document Structure
Range queries:
/^900006:1403/
Regex must be
left-anchored &
case-sensitive](https://image.slidesharecdn.com/timeseriesdata-mongodb-webinar-150127130417-conversion-gate01/85/MongoDB-for-Time-Series-Data-44-320.jpg)
![{ _id: "900006:140312",
data: [
{ speed: NaN, time: NaN },
{ speed: NaN, time: NaN },
{ speed: NaN, time: NaN },
...
],
conditions: {
status: "Snow / Ice Conditions",
pavement: "Icy Spots",
weather: "Light Snow"
}
}
Sample Document Structure
Pre-allocated,
60 element array of
per-minute data](https://image.slidesharecdn.com/timeseriesdata-mongodb-webinar-150127130417-conversion-gate01/85/MongoDB-for-Time-Series-Data-45-320.jpg)







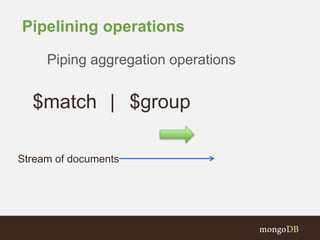
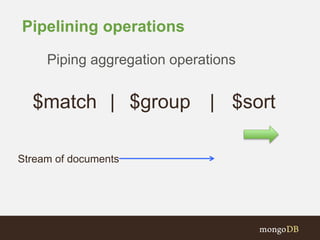
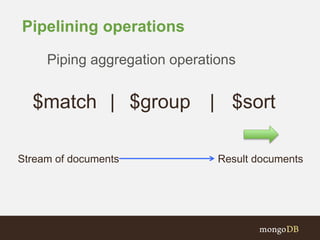





![More Sophisticated Pipelines:
average speed with variance
{ "$project" : {
mean: "$meanSpd",
spdDiffSqrd : {
"$map" : {
"input": {
"$map" : {
"input" : "$speeds",
"as" : "samp",
"in" : { "$subtract" : [ "$$samp", "$meanSpd" ] }
}
},
as: "df", in: { $multiply: [ "$$df", "$$df" ] }
} } } },
{ $unwind: "$spdDiffSqrd" },
{ $group: { _id: mean: "$mean", variance: { $avg: "$spdDiffSqrd" } } }](https://image.slidesharecdn.com/timeseriesdata-mongodb-webinar-150127130417-conversion-gate01/85/MongoDB-for-Time-Series-Data-61-320.jpg)






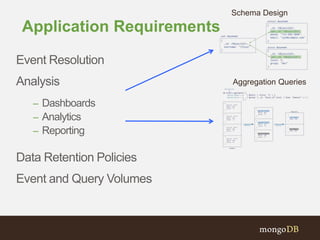
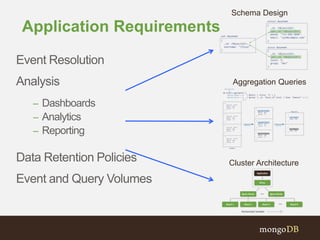
The document discusses the implementation of MongoDB for managing time series data, highlighting its various applications in sectors like finance, industrial monitoring, and social media. It emphasizes considerations for schema design, data retention strategies, and aggregation techniques to optimize performance for high-volume datasets such as traffic monitoring systems. Key insights include the importance of tailoring data structures to specific application needs to enhance write and read efficiencies.






















































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)































