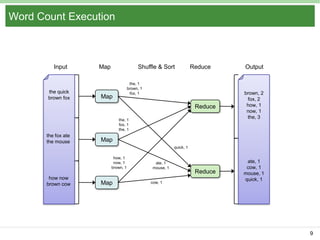
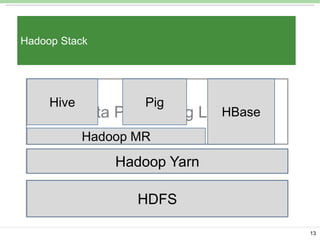
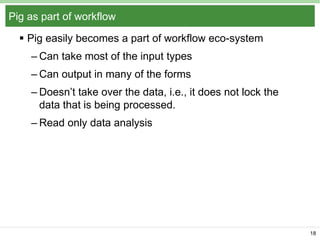
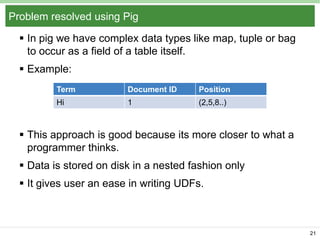
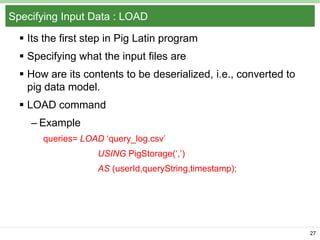
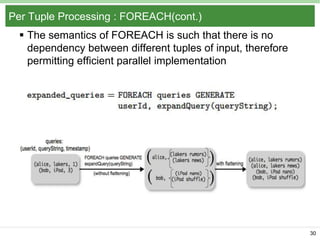
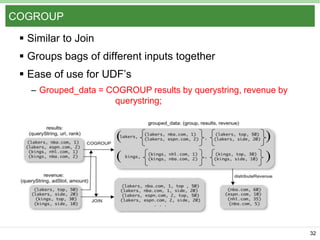
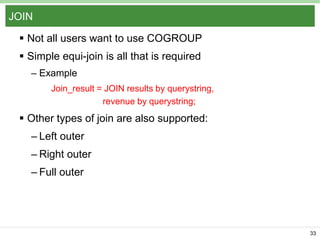
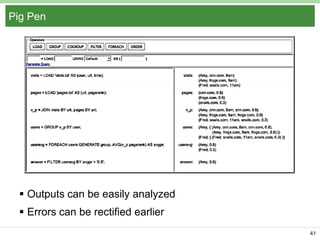
Pig Latin is a data flow language and execution framework for parallel computation. It allows users to express data analysis programs intuitively as a series of steps. Pig runs these steps on Hadoop for scalable processing. Key features include a simple declarative language, support for nested data types, user defined functions, and a debugging environment. The document provides an overview of Pig Latin concepts like loading and transforming data, filtering, joining, and outputting results. It also compares Pig Latin to MapReduce and SQL, highlighting Pig's advantages for iterative data analysis tasks on large datasets.