



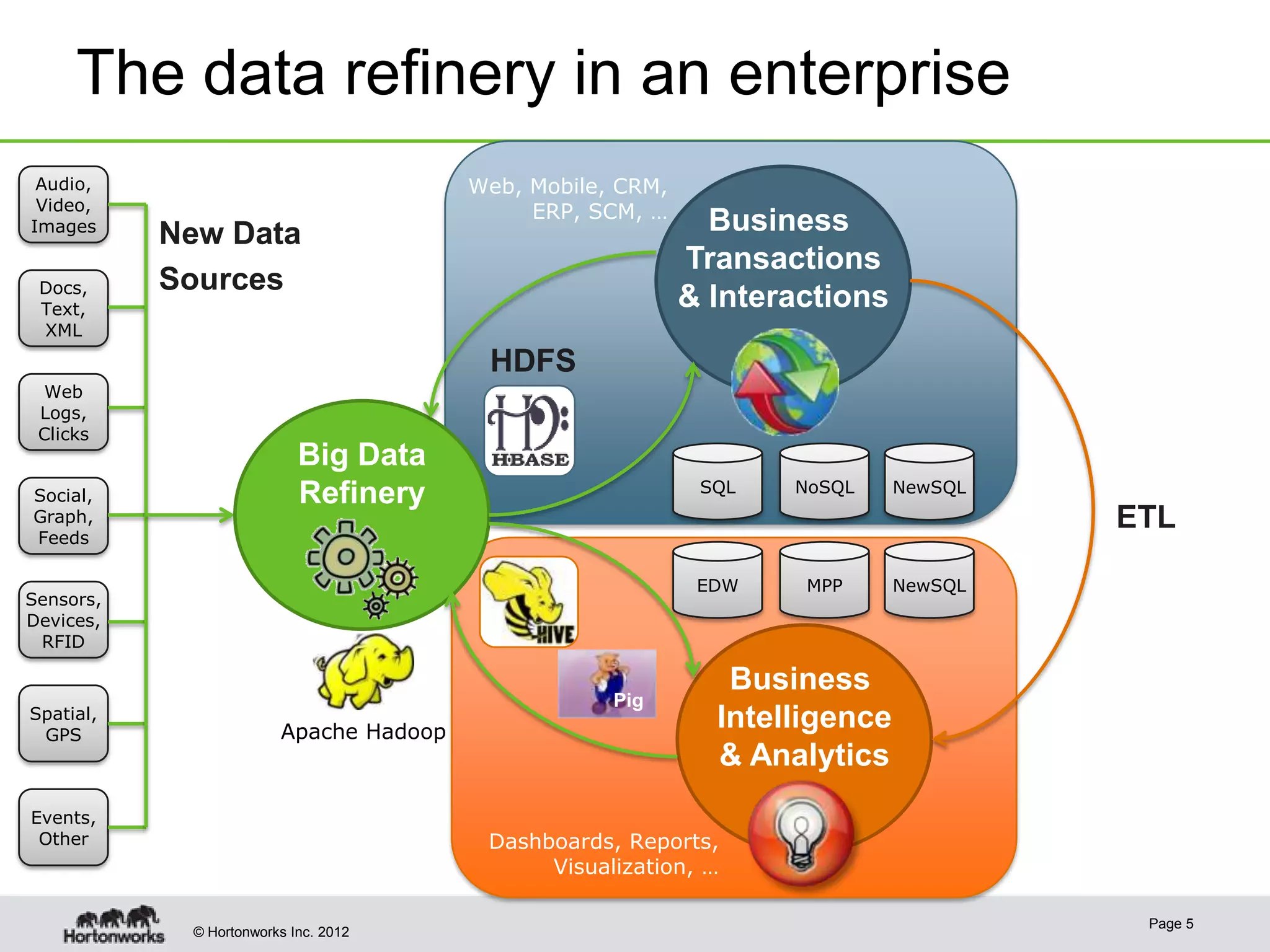


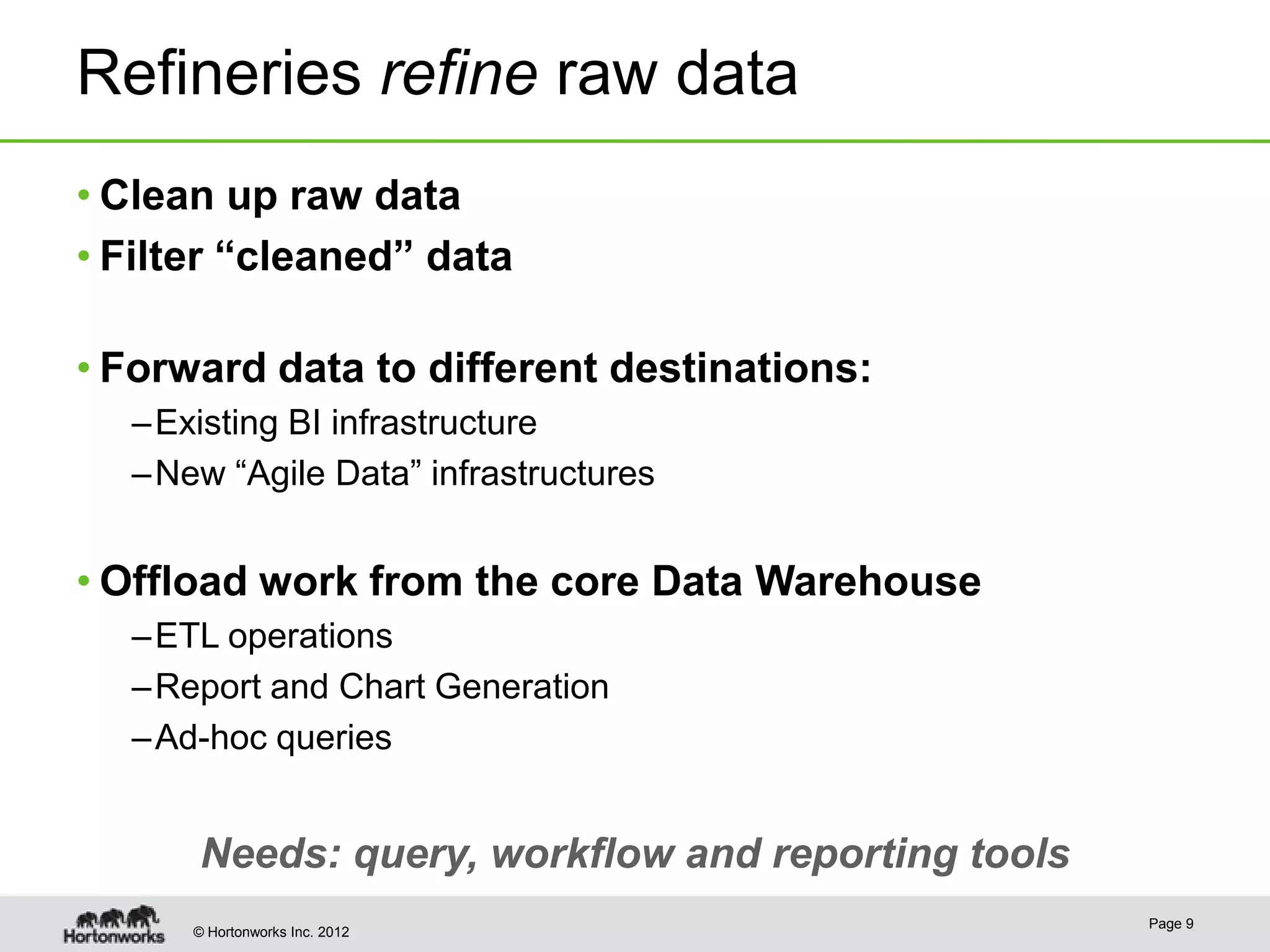





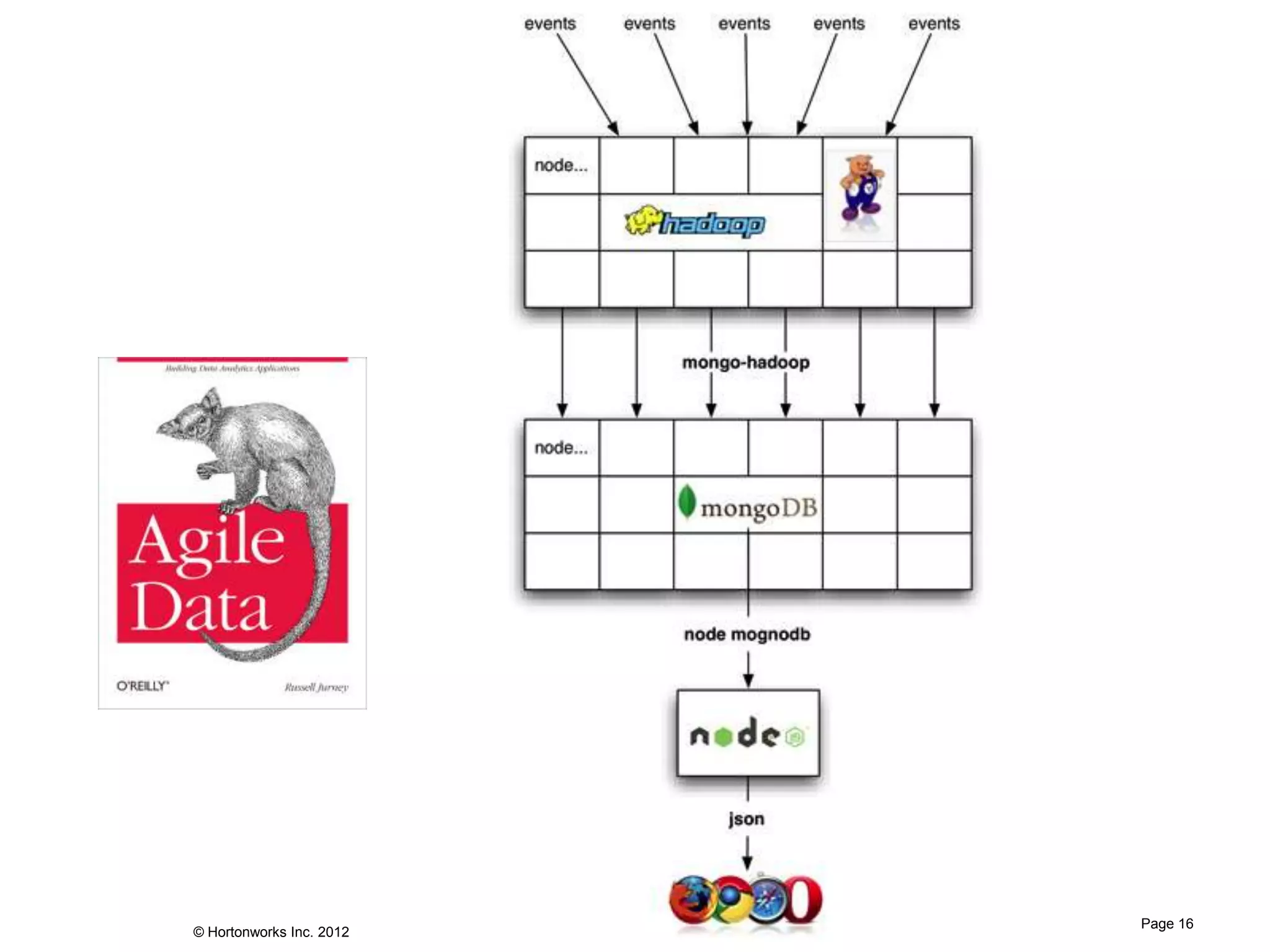


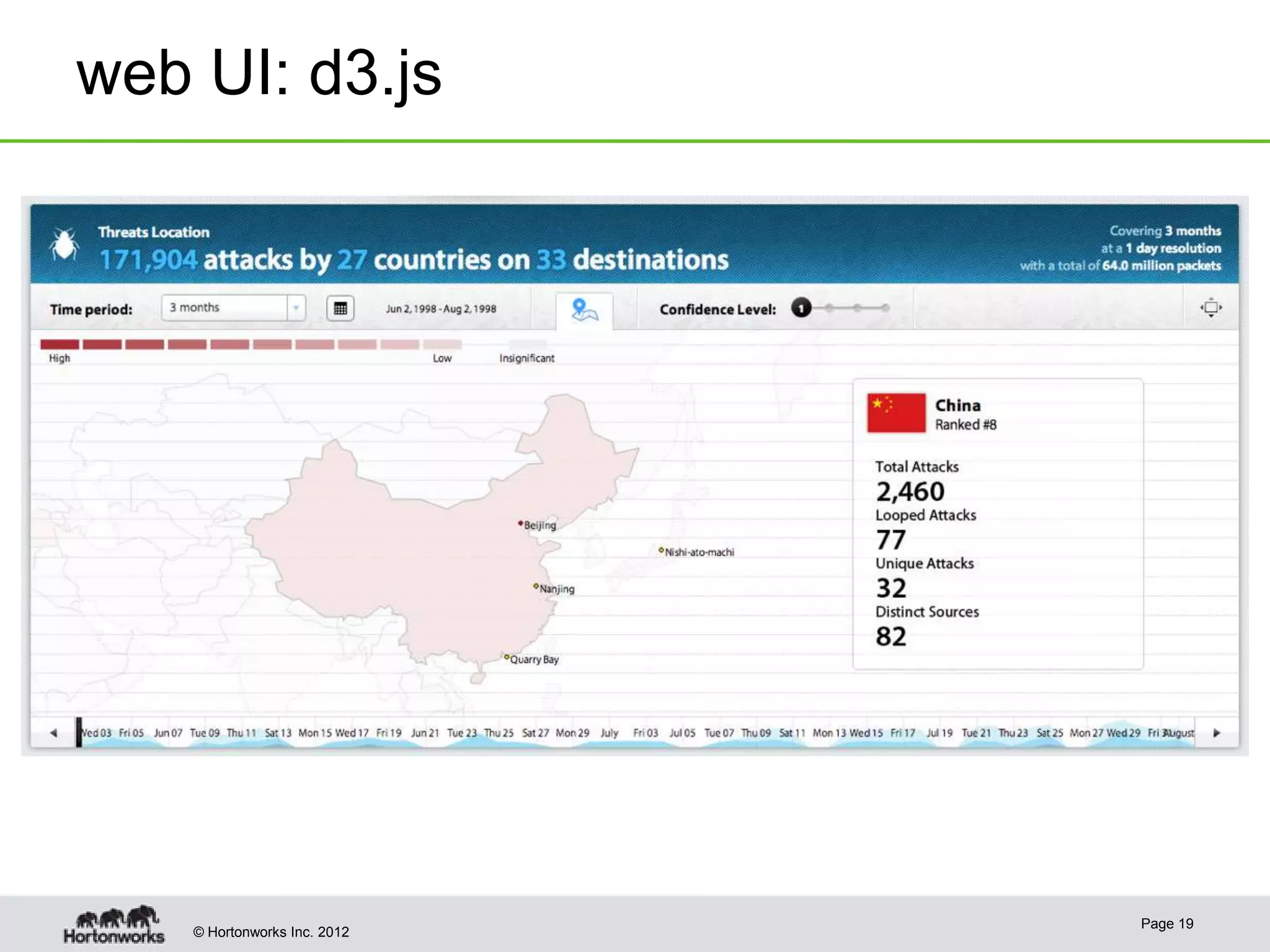




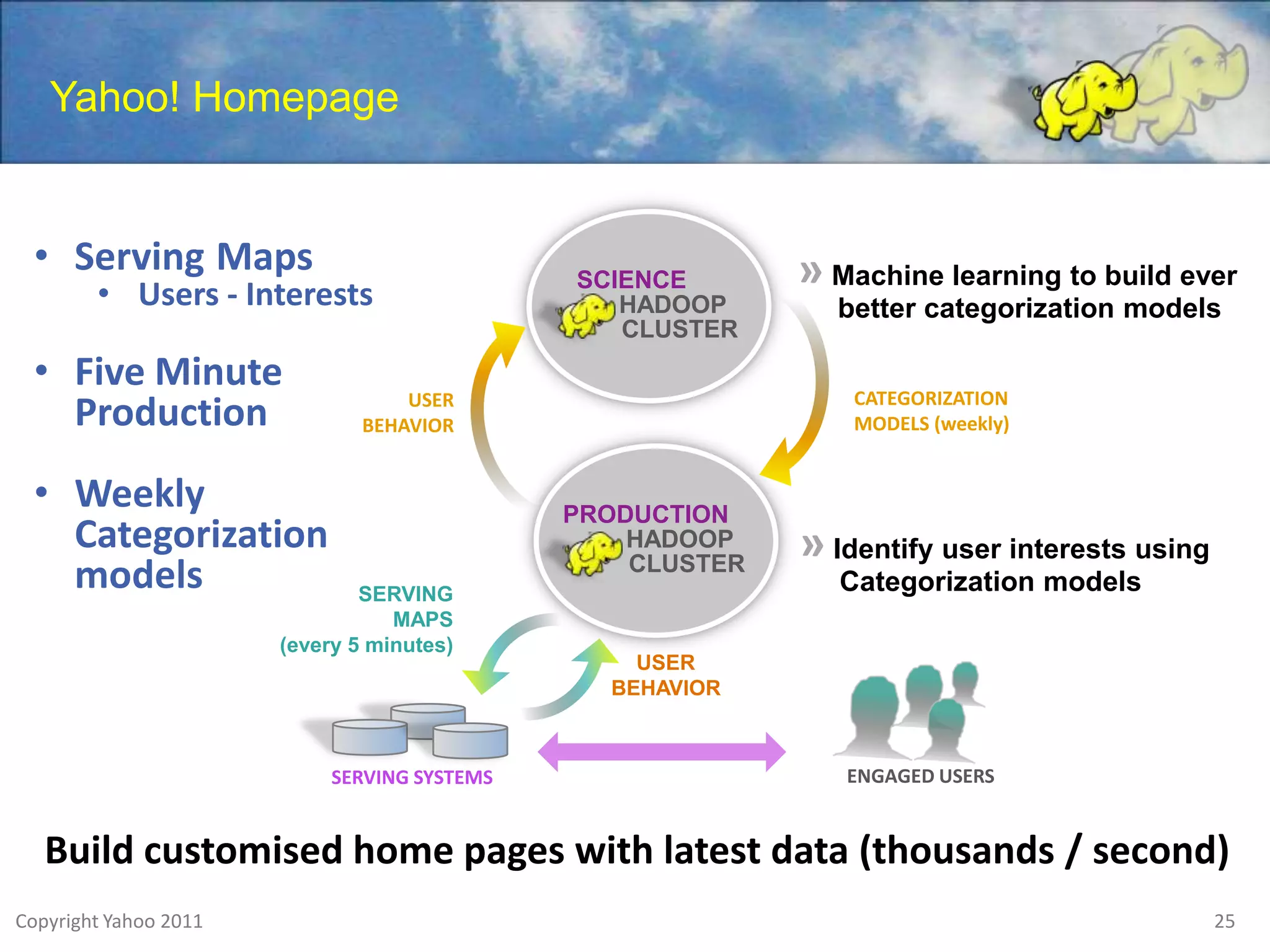


The document discusses Apache Hadoop as a framework for managing and analyzing big data, highlighting its role as a 'data refinery' that can store, clean, and process large datasets efficiently. It outlines the benefits of Hadoop in modern business intelligence, emphasizing agility in data handling and the ability to experiment with raw data. The presentation concludes that Hadoop can complement existing business intelligence systems by providing a platform for data science and advanced analysis.










































































































