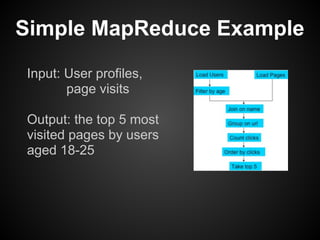
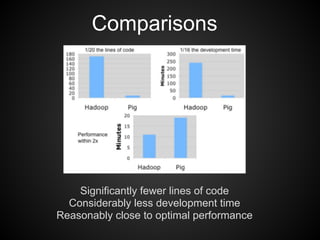
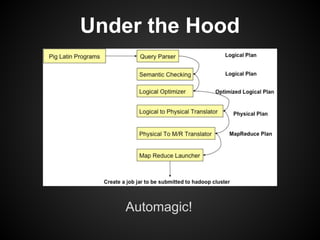
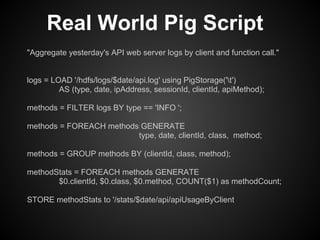
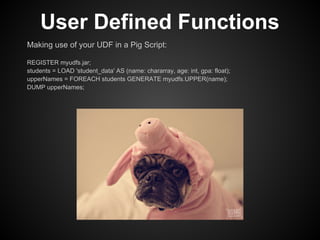
This document provides an overview of the Pig Latin data flow language for Hadoop. It discusses why Pig is useful for increasing productivity and insulating users from complexity when working with MapReduce. The document provides examples of simple Pig Latin scripts for common tasks like filtering, joining, grouping and aggregation. It also covers performance considerations, user defined functions, common pitfalls, and recommendations.