Download as PDF, PPTX



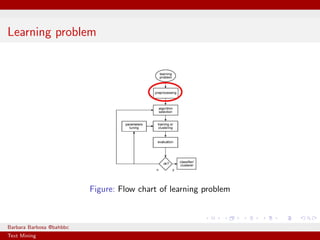





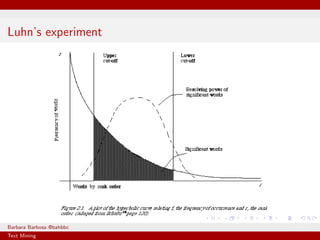




Text mining is the process of deriving information from text. It usually requires preprocessing the input data, which can include tokenizing, removing stopwords, and stemming. A corpus is the set of documents being analyzed, which can consist of text from a company's Facebook page. Common techniques in text mining include the vector space model and TF-IDF to characterize documents based on word frequencies.


































































































