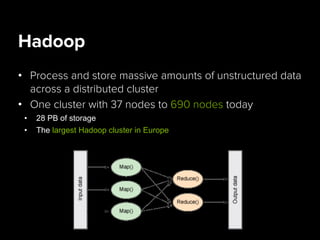
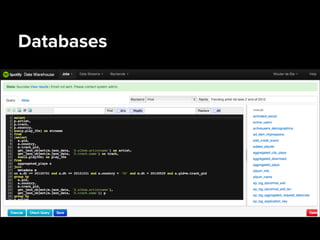
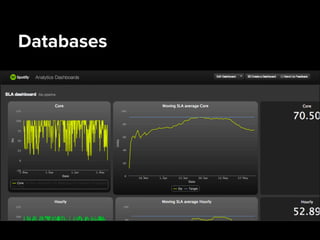
Danielle Jabin is a data engineer at Spotify who works on A/B testing infrastructure. She describes Spotify's big data landscape, which includes over 40 million active users generating 1.5 TB of compressed data per day. Spotify collects this user data using Kafka for high-volume data collection, processes it using Hadoop on a large cluster, and stores aggregates in databases like PostgreSQL and Cassandra for analytics and visualization.