Download as PDF, PPTX
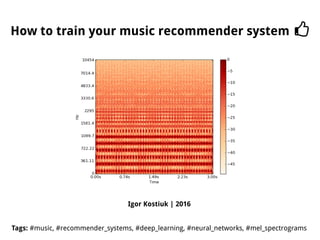
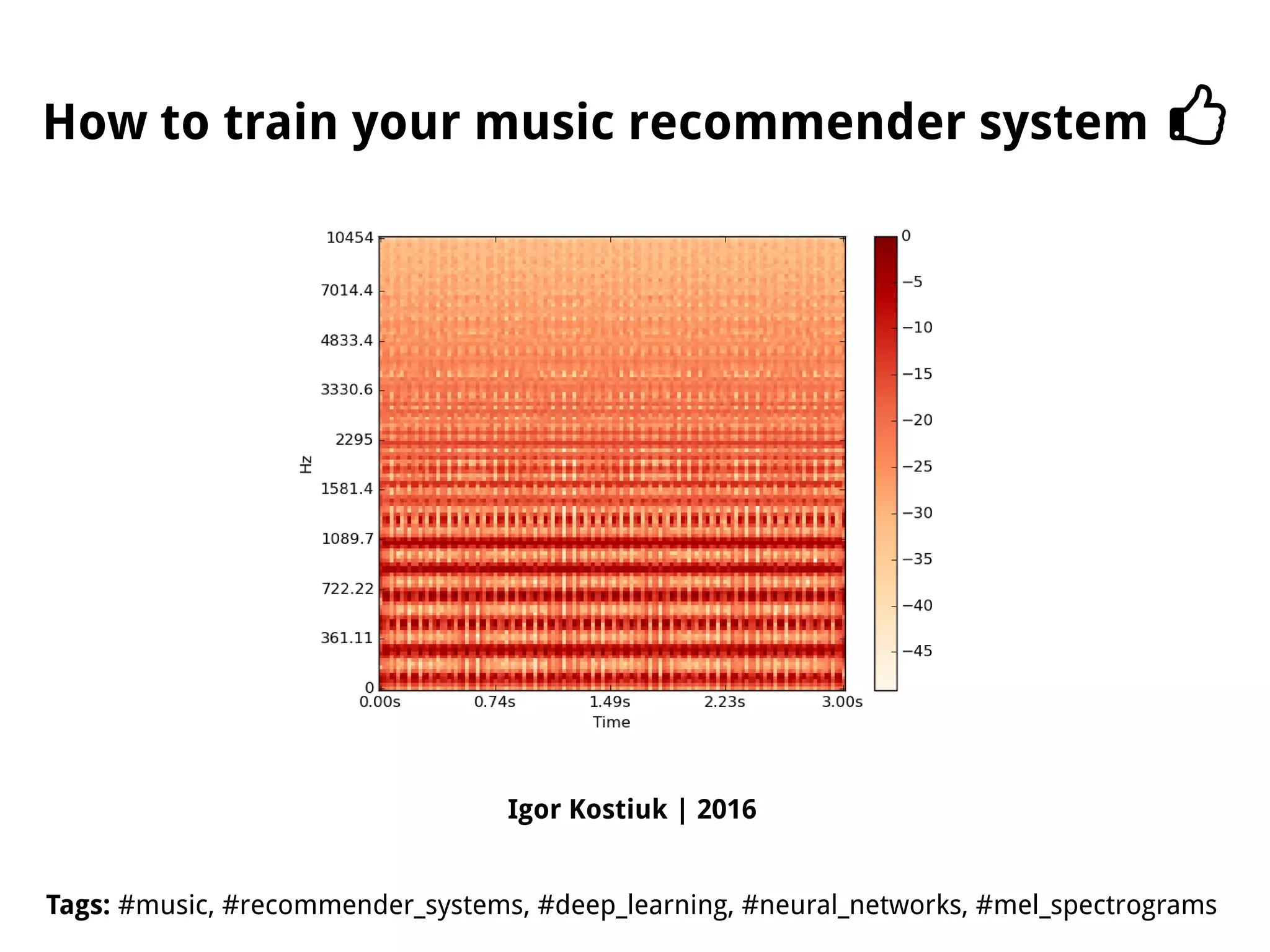

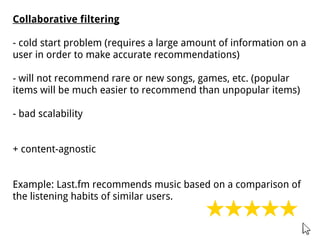


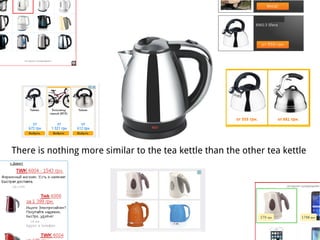

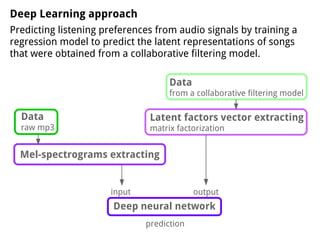



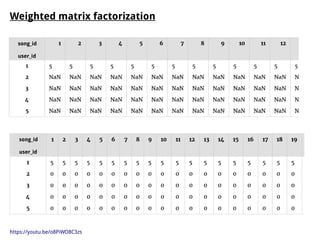
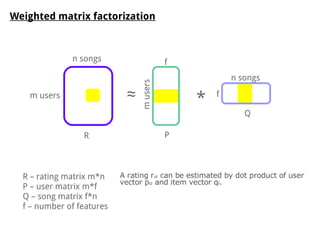


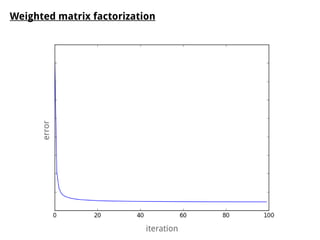

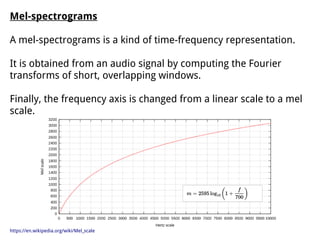
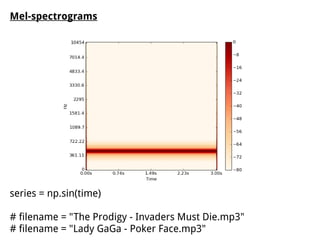
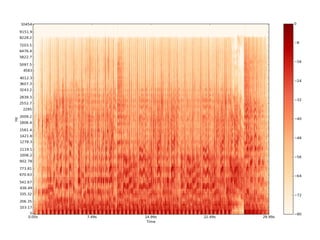
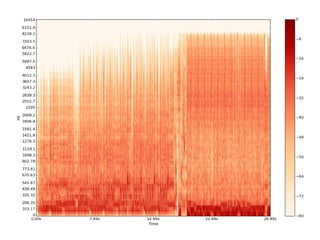

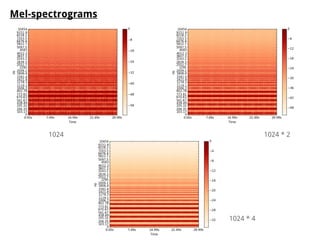
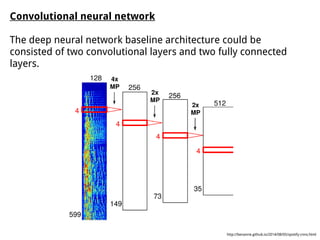
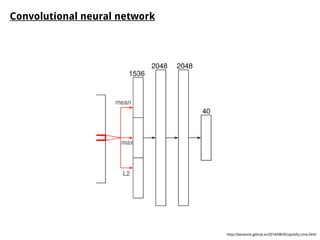





The document discusses methods for training music recommender systems, highlighting collaborative filtering and content-based filtering as key approaches. It mentions challenges like the cold start problem and the semantic gap in user preferences, while proposing solutions such as automatic social tag generation and deep learning models to enhance recommendations. Additionally, it describes the use of mel-spectrograms and convolutional neural networks for predicting user preferences from audio signals.
















































































