Download to read offline


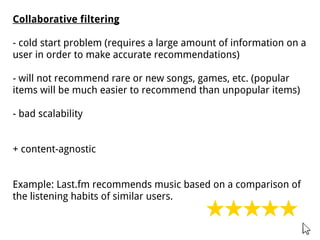















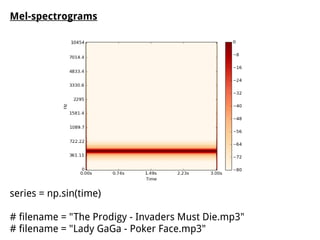




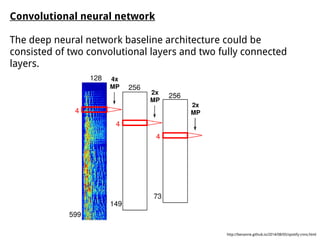
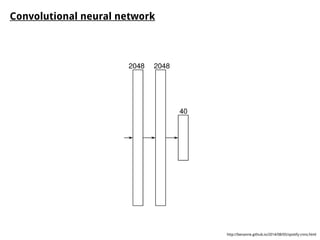
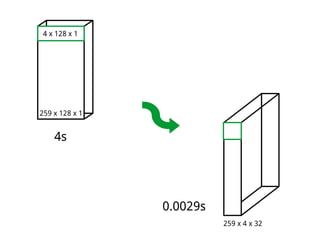










This document discusses different approaches for training music recommender systems using deep learning techniques. It describes using collaborative filtering to obtain latent representations of songs from user listening data. Convolutional neural networks can then be trained to predict these latent factors directly from mel-spectrograms of audio clips. This allows the system to recommend new songs without requiring a user's listening history. The document outlines the development process, including extracting mel-spectrograms from audio, performing weighted matrix factorization on user data, and using the neural network to map spectrograms to the latent factors.























































































