Download as PDF, PPTX


![Extracting Features
●
●
●
●
●
●
●
●
●
●
●
●
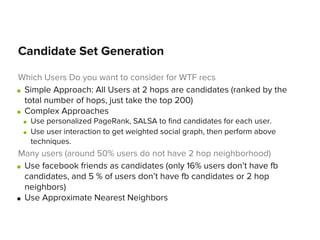
hops: number of paths of length 2 between user1 and user2
hopslog: hops/log(# of subscribers user2 has)
common: no. of common neighbors shared by user1 and user2
jaccard: common/(union of neighbors of user1 and user2)
cosine: cosine similarity of user vectors of user1 and user2
adamic: summation over neighbors of user1 [1/log(# of subscribers of
the neighbor)]
indegree: in degree of user2
fraction_n2: for 2 users i and j, fraction of subscriptions of i that are
following j
fraction_n1: for 2 users i and j, fraction of subscriptions of j that have i
follows
pref_attachment: number of subscriptions of i * num of followers of j
reverse_edge: of i,j = 1 if j follows i
Label: positive or negative class, as described in slide 2.](https://image.slidesharecdn.com/internshippptslideshare-131220150159-phpapp02/85/WhoToFollow-Spotify-4-320.jpg)



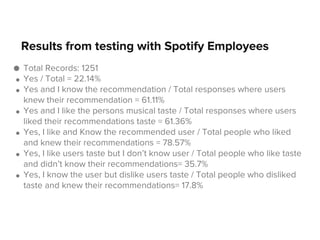




This document discusses Spotify's approach to generating recommendations for who a user should follow. It first generates candidate recommendations for each user using their 2-hop social network or Facebook friends. It then trains a machine learning model to rank these candidates by extracting features like the number of common connections, cosine similarity of profiles, etc. It found gradient boosted decision trees performed best. Testing recommendations on Spotify employees found over 60% liked and knew the recommended user. It optimized the process by loading data into a database instead of memory to allow for multiprocessing.















































