Download as PDF, PPTX









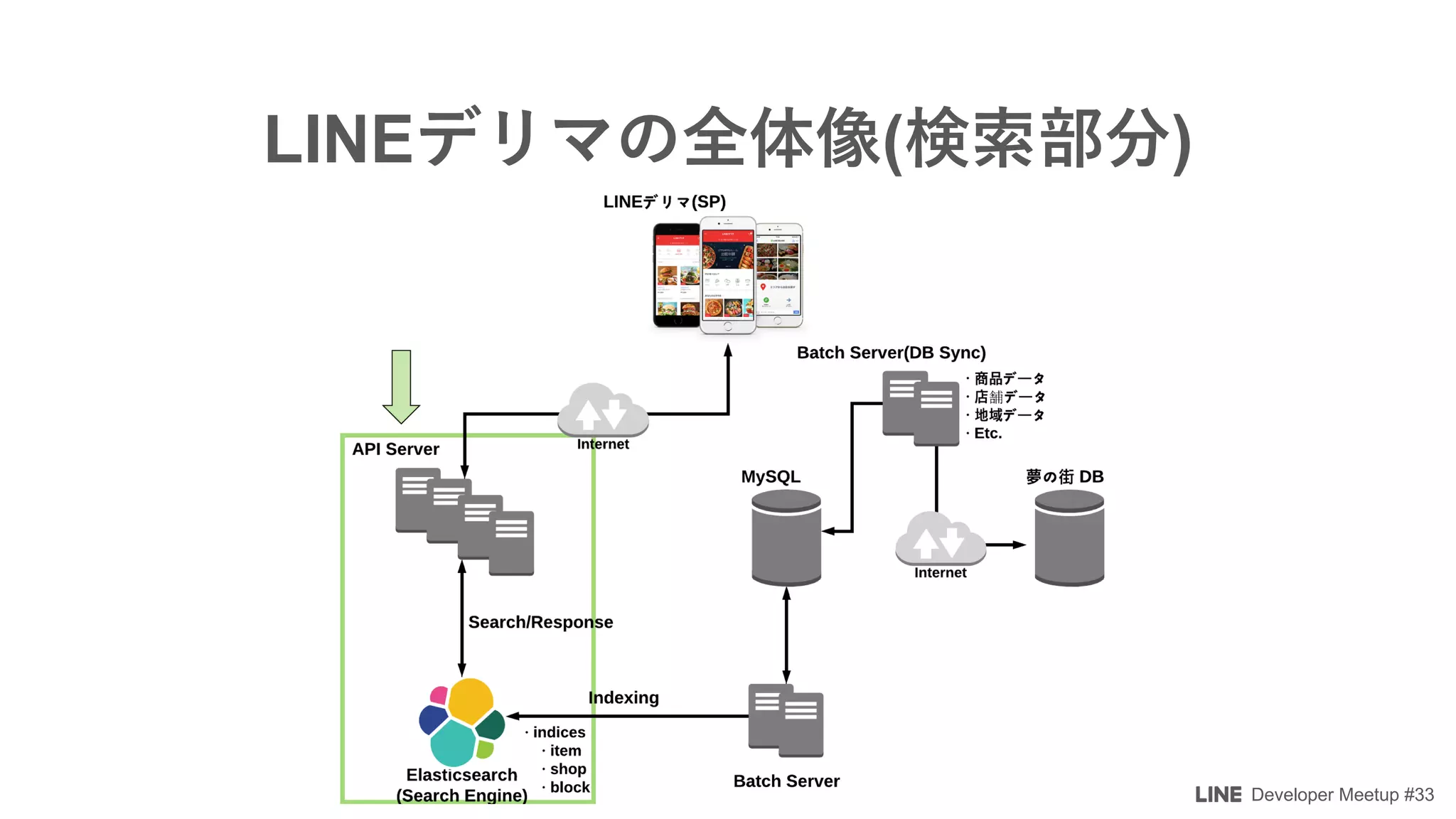





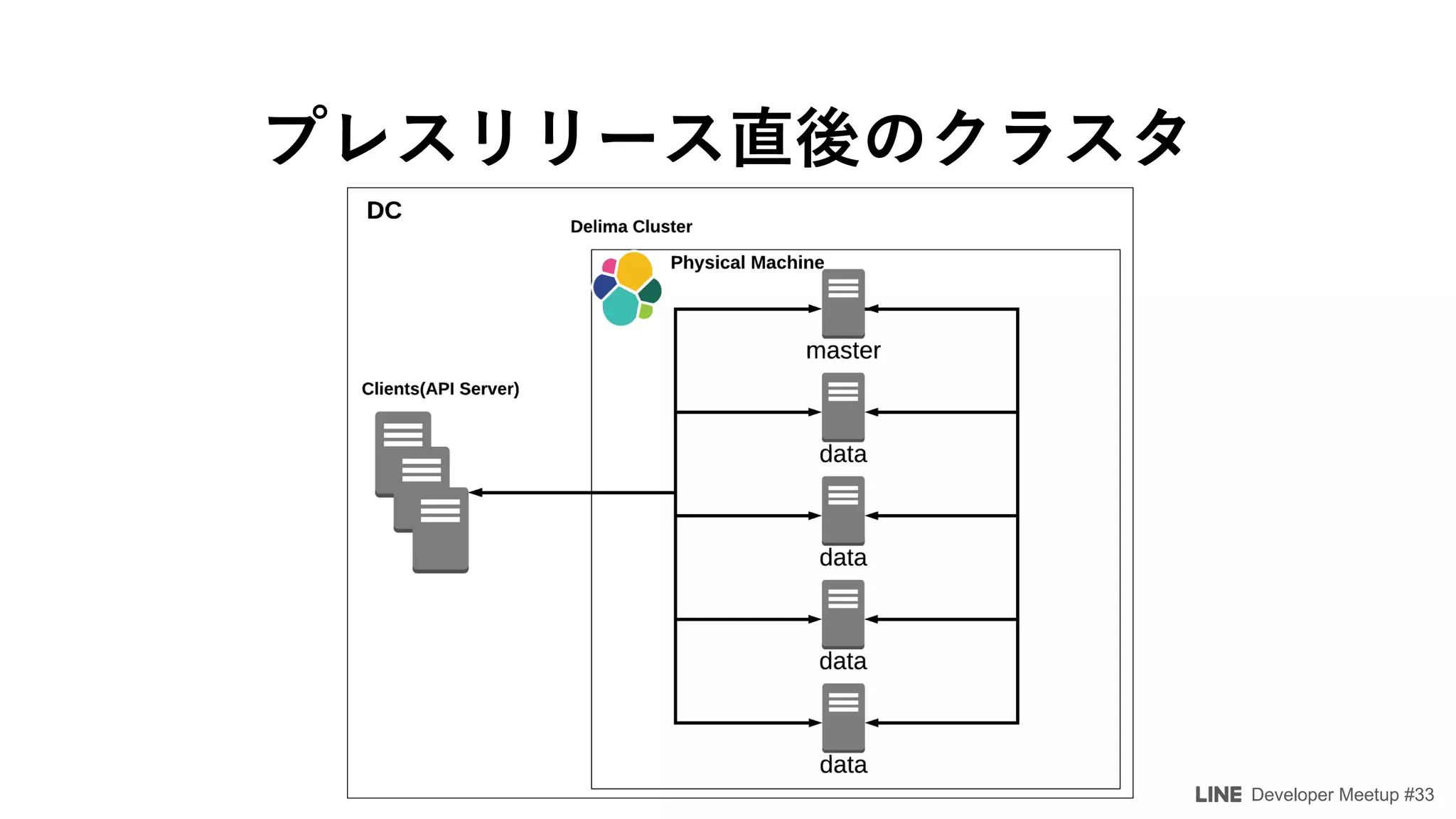

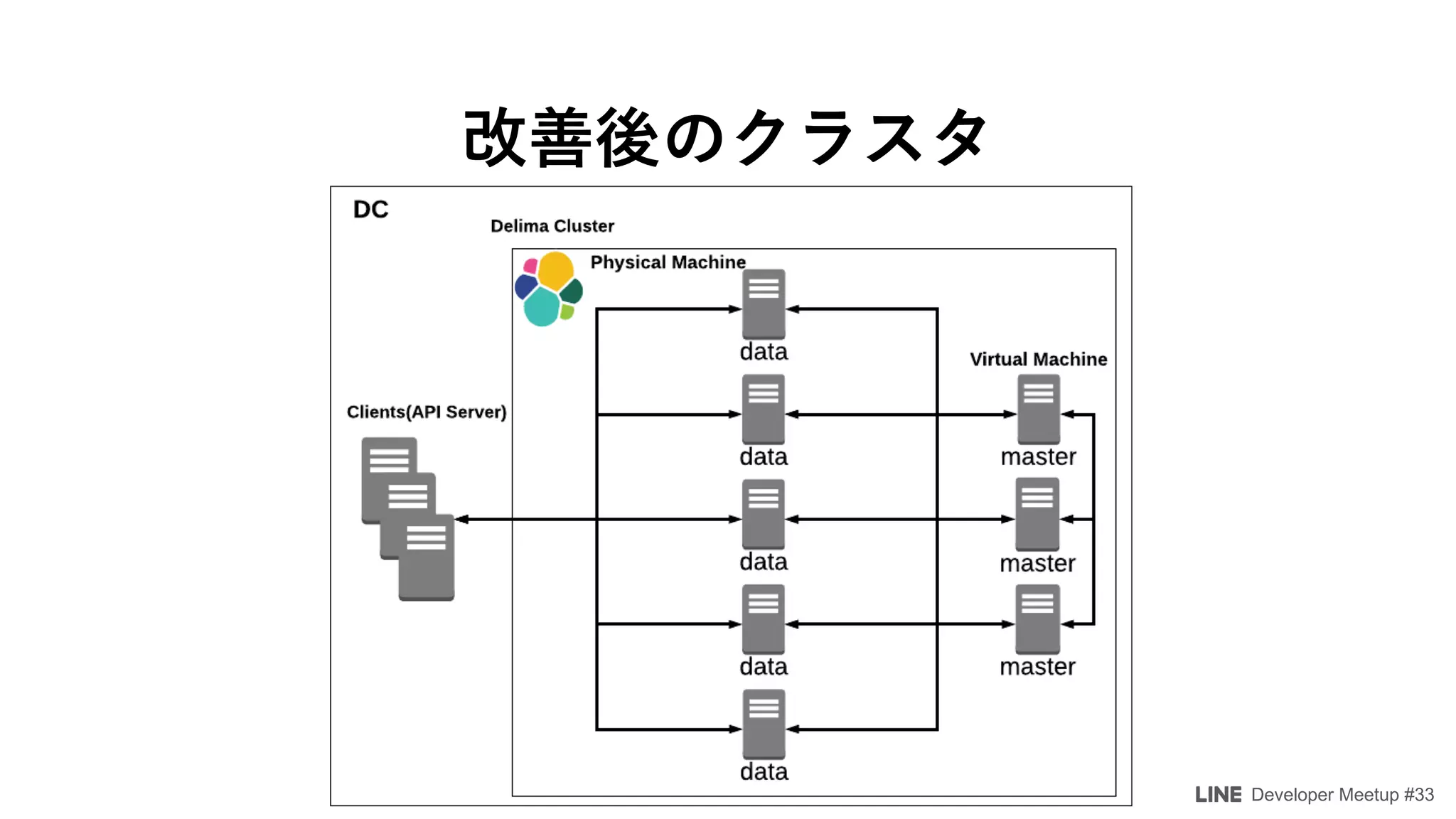








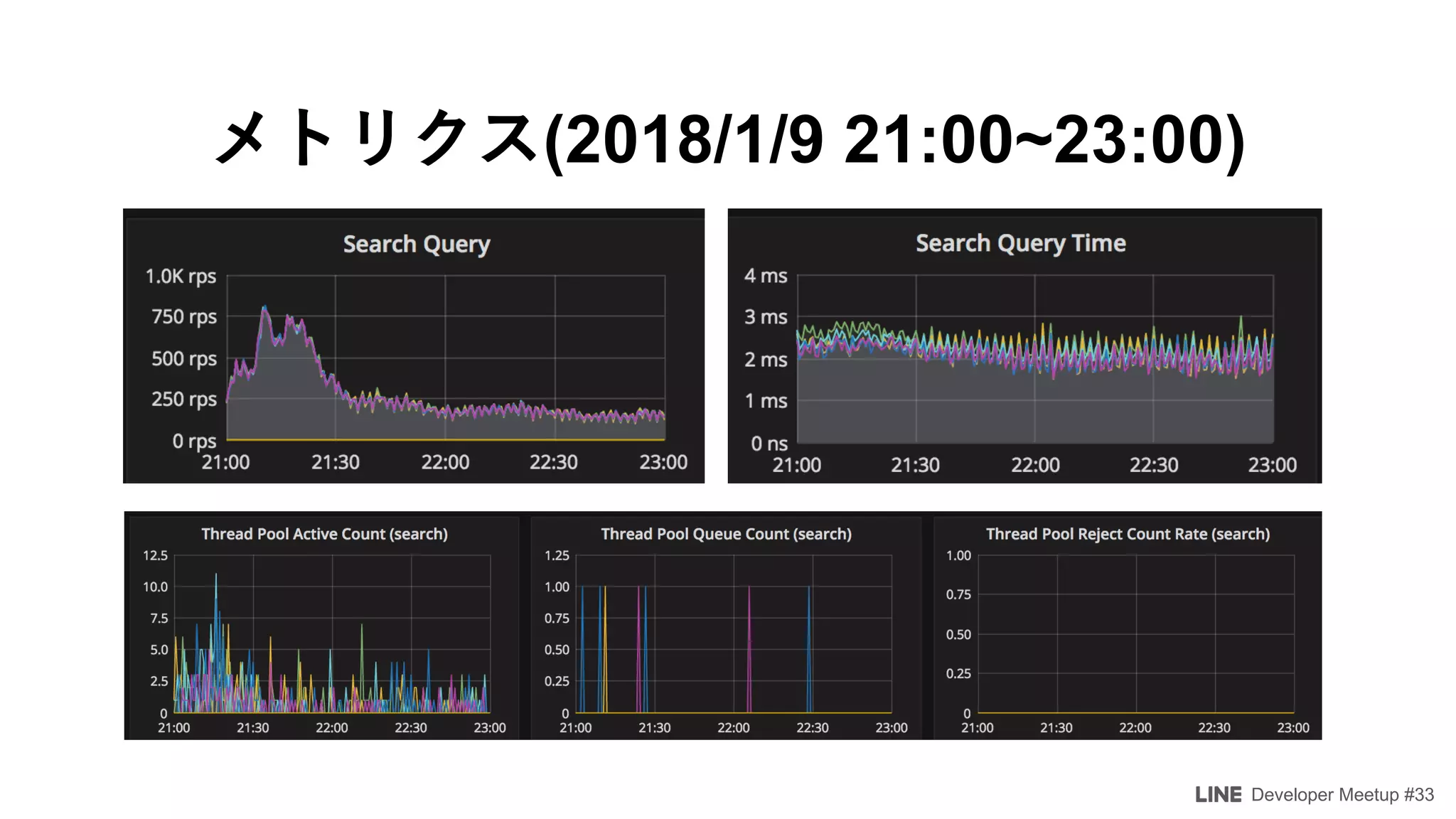







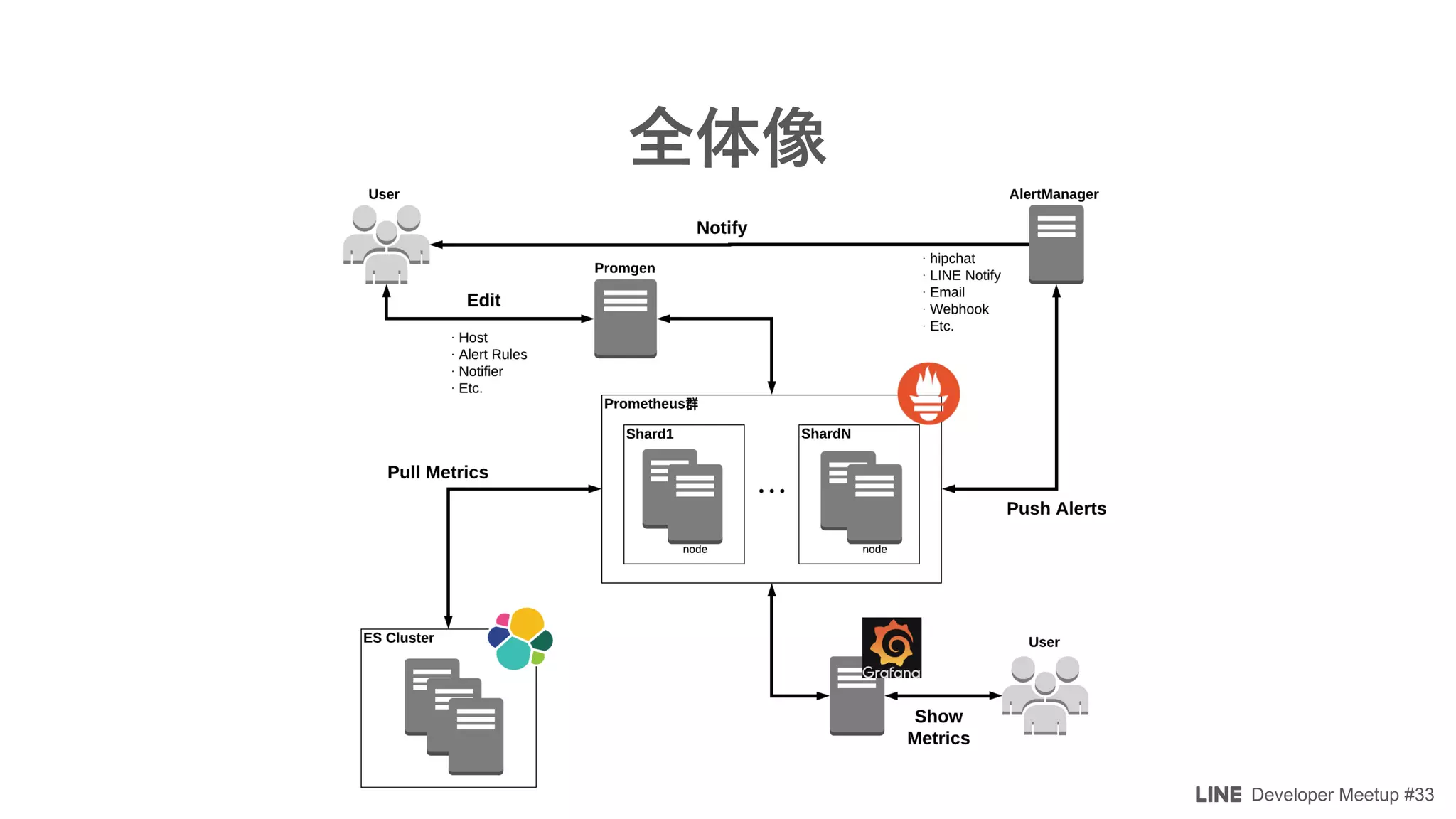










The document details a developer meetup focused on Elasticsearch and related technologies, featuring discussions on various topics such as configuration, performance optimization, and monitoring. Key points include shard allocation strategies, zone awareness for data nodes, and the transition from transport clients to high-level REST clients in Elasticsearch. Additionally, it covers integrations with Prometheus for monitoring and alerting systems using Grafana.






















































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)











