Downloaded 23 times










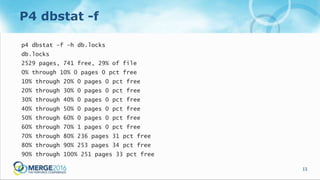
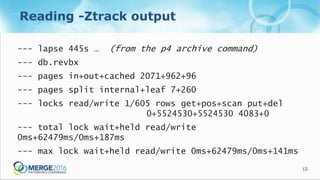
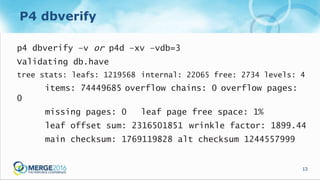
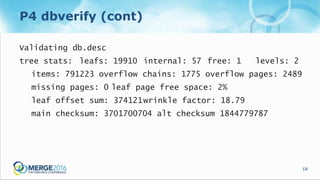




The document discusses updates and operational changes in the p4d database, including advances in storage technology like SSDs and the impact of various database management practices. Key topics covered include the importance of file system caching, the nuances of database reorganization, and performance monitoring techniques. The document also contrasts the specific functionalities of p4d as a specialized database management system against general-purpose DBMS options.


































































