Downloaded 237 times







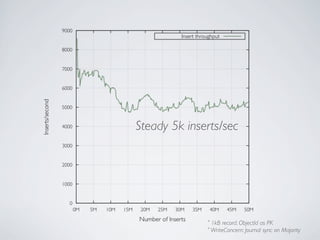

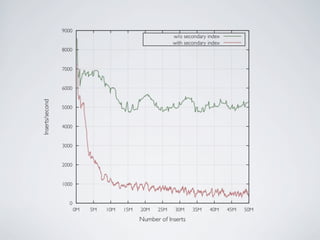



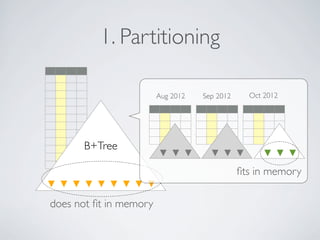

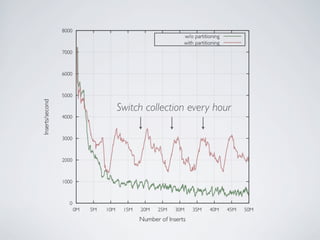

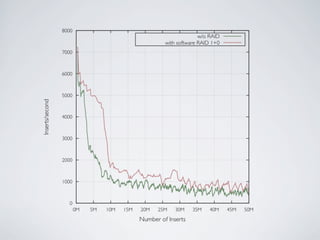
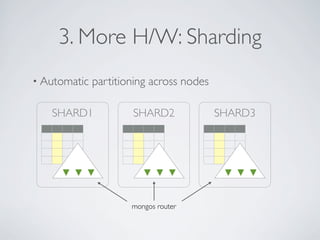
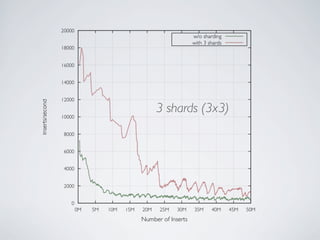
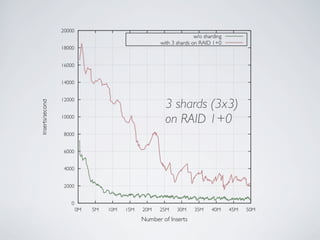




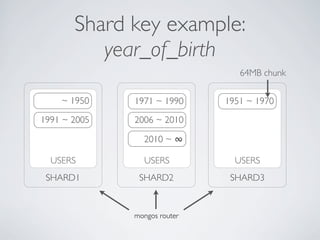
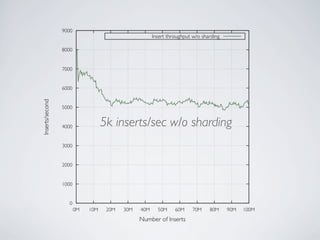

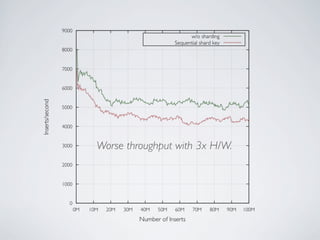



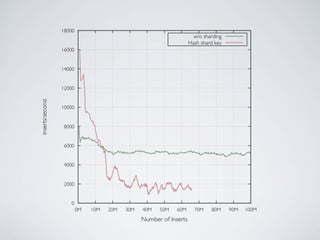






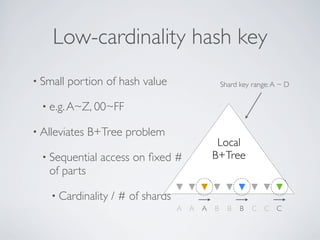
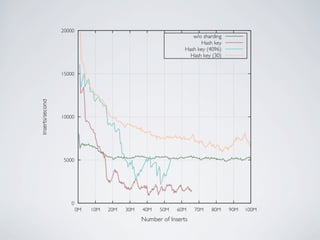


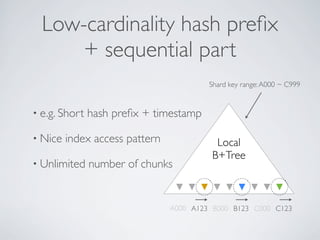
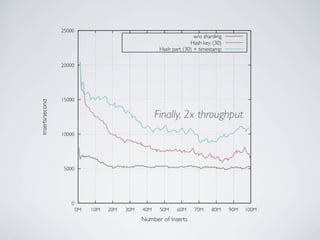



- MongoDB allows for automatic sharding of data across multiple servers to improve write performance. However, scaling write performance is challenging due to the way B-tree indexes handle random inserts. - To improve write performance, one can partition data by time or use a hash shard key. However, these have limitations as the data grows large. The best approach is to use a low-cardinality hash prefix combined with a sequential part for the shard key. - Proper choice of shard key is crucial for scaling MongoDB's write performance as data size increases. Linear scalability is difficult to achieve and alternative databases may be better if extremely high write throughput is required.


























































![Daum devday 13 [bap]](https://cdn.slidesharecdn.com/ss_thumbnails/daumdevday13-bap-130225010411-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)








