Downloaded 18 times



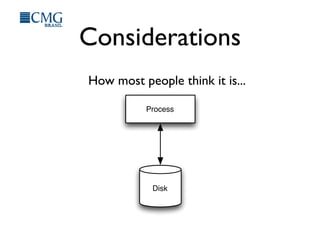
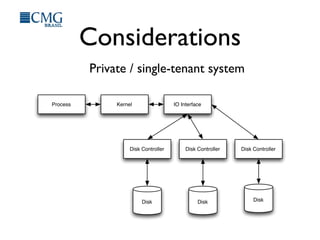
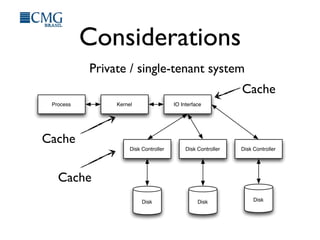
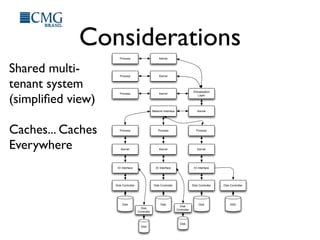













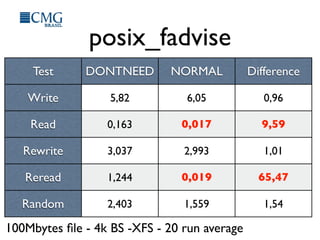






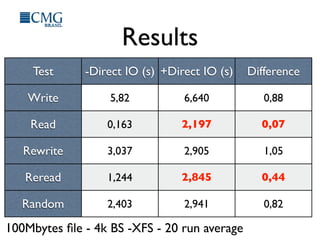
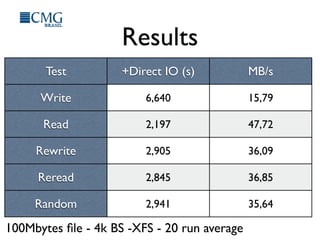




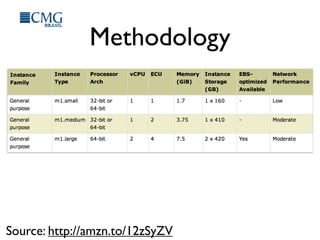

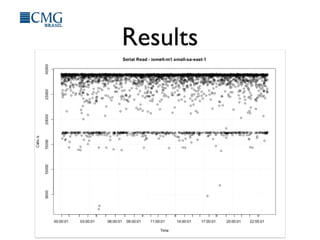

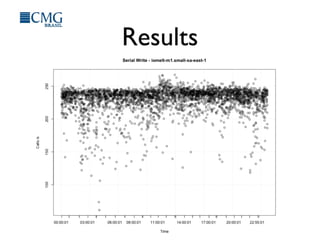
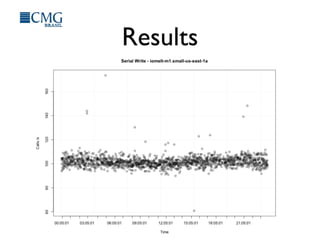

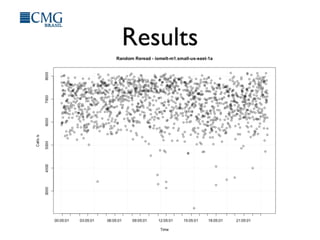




This document discusses benchmarking disk I/O performance in shared, multi-tenant cloud environments. It notes challenges with traditional tools and methodologies. It proposes a simple benchmarking tool called iomelt that uses direct I/O and fadvise calls to minimize buffering effects. Results show direct I/O can reduce performance compared to buffered I/O. The document recommends regularly benchmarking different instance types and regions over long periods to analyze performance consistency in shared environments.

















































![Oracle Open World 2014: Lies, Damned Lies, and I/O Statistics [ CON3671]](https://cdn.slidesharecdn.com/ss_thumbnails/thursday115ionfs-141107125307-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)

























































