Downloaded 237 times


















![Controversy about privacy issues
• The Pentium III was the first x86 CPU to include a unique,
retrievable, identification number, called PSN (Processor
Serial Number). A Pentium III's PSN can be read by software
through the CPUID instruction if this feature has not been
disabled through the BIOS.
• On November 29, 1999, the Science and Technology Options
Assessment (STOA) Panel of the European Parliament,
following their report on electronic surveillance techniques
asked parliamentary committee members to consider legal
measures that would "prevent these chips from being installed
in the computers of European citizens."[13]
• Eventually Intel decided to remove the PSN feature on
Tualatin-based Pentium IIIs, and the feature was not carried
through to the Pentium 4 or Pentium M. The feature does not
exist in modern Intel x86 CPUs.](https://image.slidesharecdn.com/pentiumiii-130420030505-phpapp02/85/Pentium-iii-21-320.jpg)



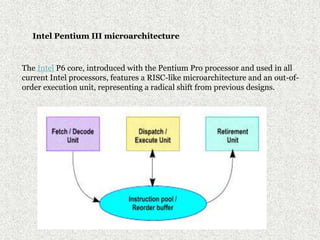
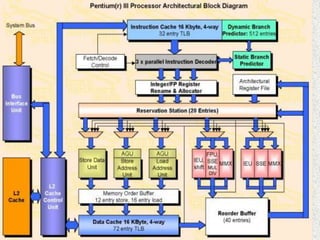
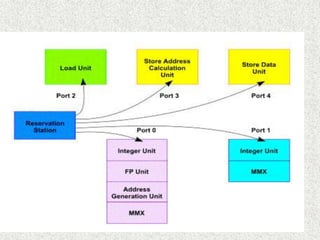
The Pentium III was a desktop and mobile CPU produced by Intel between 1999-2003. It had clock speeds between 400 MHz to 1.4 GHz and included features like MMX and SSE instructions. There were several stepping of the Pentium III including Katmai at 0.25 μm, Coppermine at 0.18 μm, Coppermine T at 0.18 μm, and Tualatin at 0.13 μm. Each stepping improved performance through higher clock speeds, larger caches, and support for newer instruction sets. Optimizing code for the Pentium III microarchitecture required techniques like scheduling instructions to maximize decoder throughput, balancing usage of execution units, and minimizing register dependencies. The Pentium III was also notable for including


































































