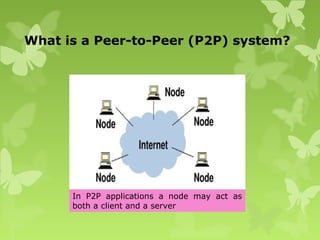
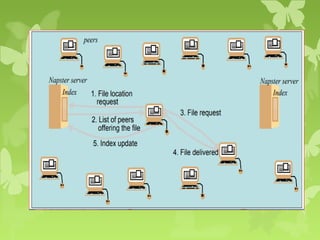
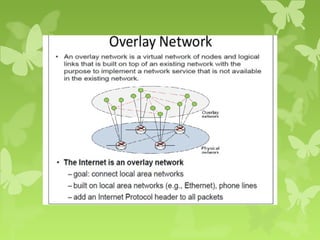
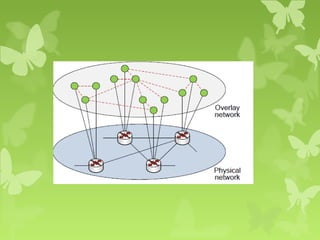
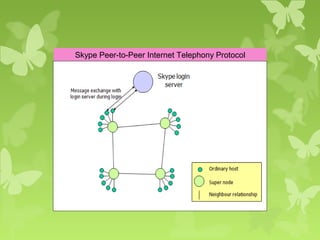
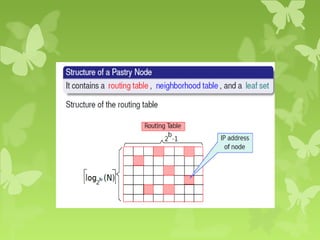
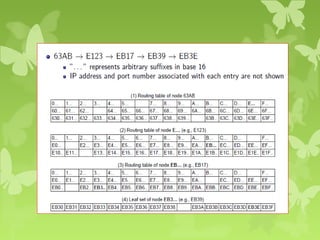
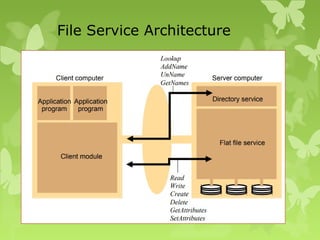
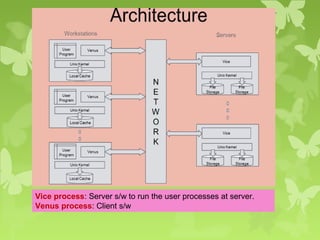
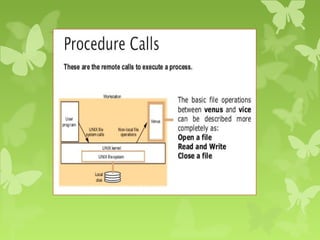
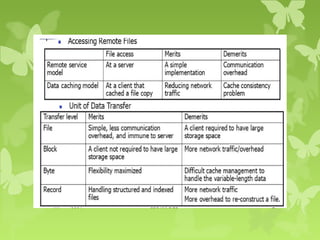
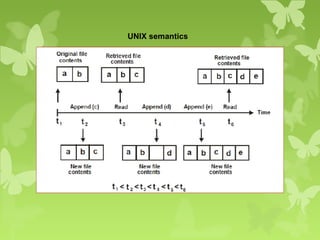
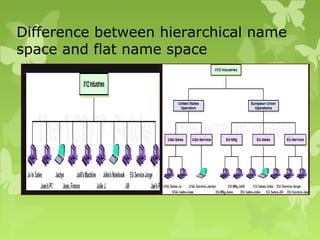
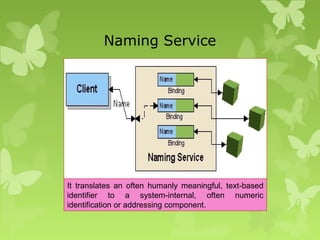
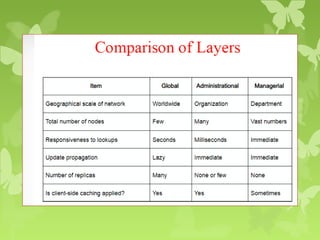
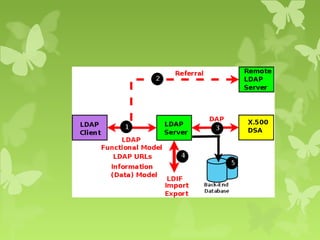
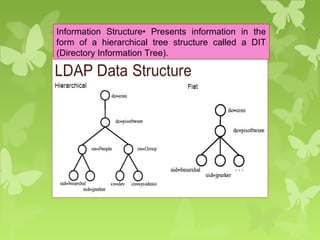
A peer-to-peer (P2P) system is a decentralized architecture where all nodes share resources and operate without a central server, enhancing scalability and fault tolerance. Key challenges include peer identification and location, with implementations like BitTorrent and Skype exemplifying P2P applications. The document also discusses centralized P2P systems like Napster and distributed file systems, highlighting the importance of routing algorithms, such as the pastry routing algorithm, in efficiently locating data within these networks.