Downloaded 464 times



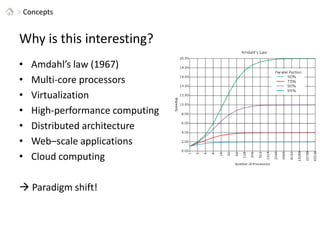


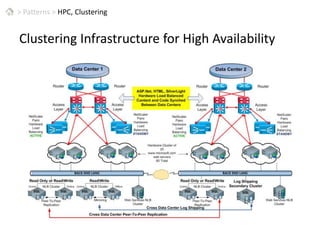
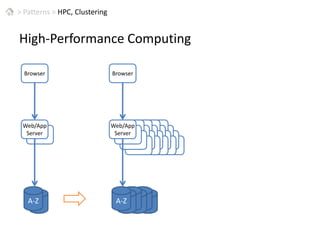

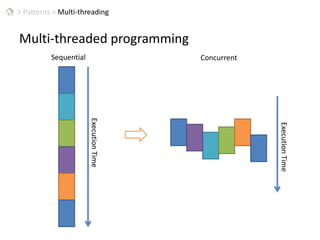

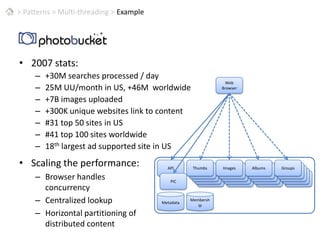

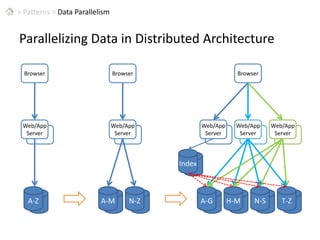



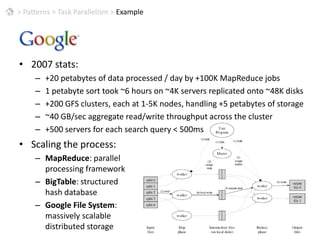


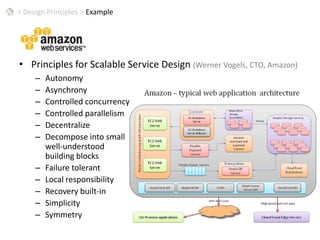

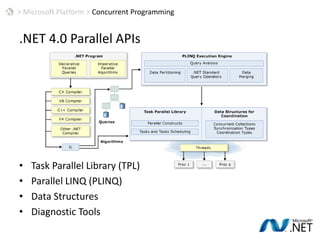

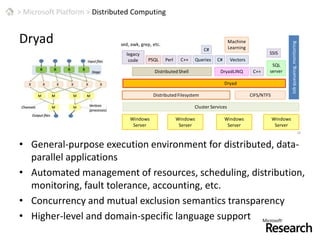
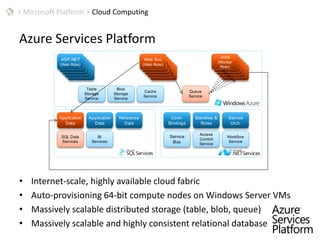
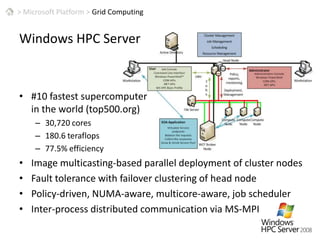
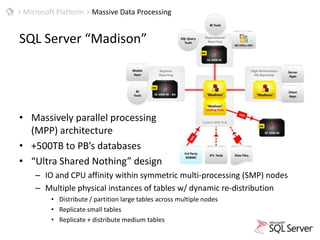




This document discusses patterns for parallel computing. It outlines key concepts like Amdahl's law and types of parallelism like data and task parallelism. Examples are provided of how major tech companies like Microsoft, Google, Amazon implement parallelism at different levels of their infrastructure and applications to scale efficiently. Design principles are discussed for converting sequential programs to parallel programs while maintaining performance.



































































































