Downloaded 12 times













![Sample request and response
{"e": [ { {
"type": "SETKEYSPACE",
"exception":null,
"op": { "keyspace": "myks" }
"exceptionId":null,
}, {
"type": "SETCOLUMNFAMILY", "opsRes": {
"op": { "columnfamily": "mycf" } "0":"OK",
}, { "1":"OK",
"type": "SLICE",
"2":[{
"op": {
"name":"Founders",
"rowkey": "beers",
"start": "Allagash", "value":"Breakfast Stout"
"end": "Sierra Nevada", }]
"size": 9 }}
} }]}](https://image.slidesharecdn.com/intravert-130410171208-phpapp01/75/NYC-2013-Advanced-Data-Processing-Beyond-Queries-and-Slices-16-2048.jpg)




![Defining a filter JavaScript
● Syntax to create a filter
{
"type": "CREATEFILTER",
"op": {
"name": "stouts",
"spec": "javascript",
"value": "function(row) { if (row['value'] == 'Breakfast Stout')
return row; else return null; }"
}
},](https://image.slidesharecdn.com/intravert-130410171208-phpapp01/75/NYC-2013-Advanced-Data-Processing-Beyond-Queries-and-Slices-21-2048.jpg)
![Defining a filter Groovy/Java
● We can define a groovy closure or Java filter
{
"type": "CREATEFILTER",
"op": {
"name": "stouts",
"spec": "groovy",
"{ row -> if (row["value"] == "Breakfast Stout") return row else
return null }"
}
},](https://image.slidesharecdn.com/intravert-130410171208-phpapp01/75/NYC-2013-Advanced-Data-Processing-Beyond-Queries-and-Slices-22-2048.jpg)
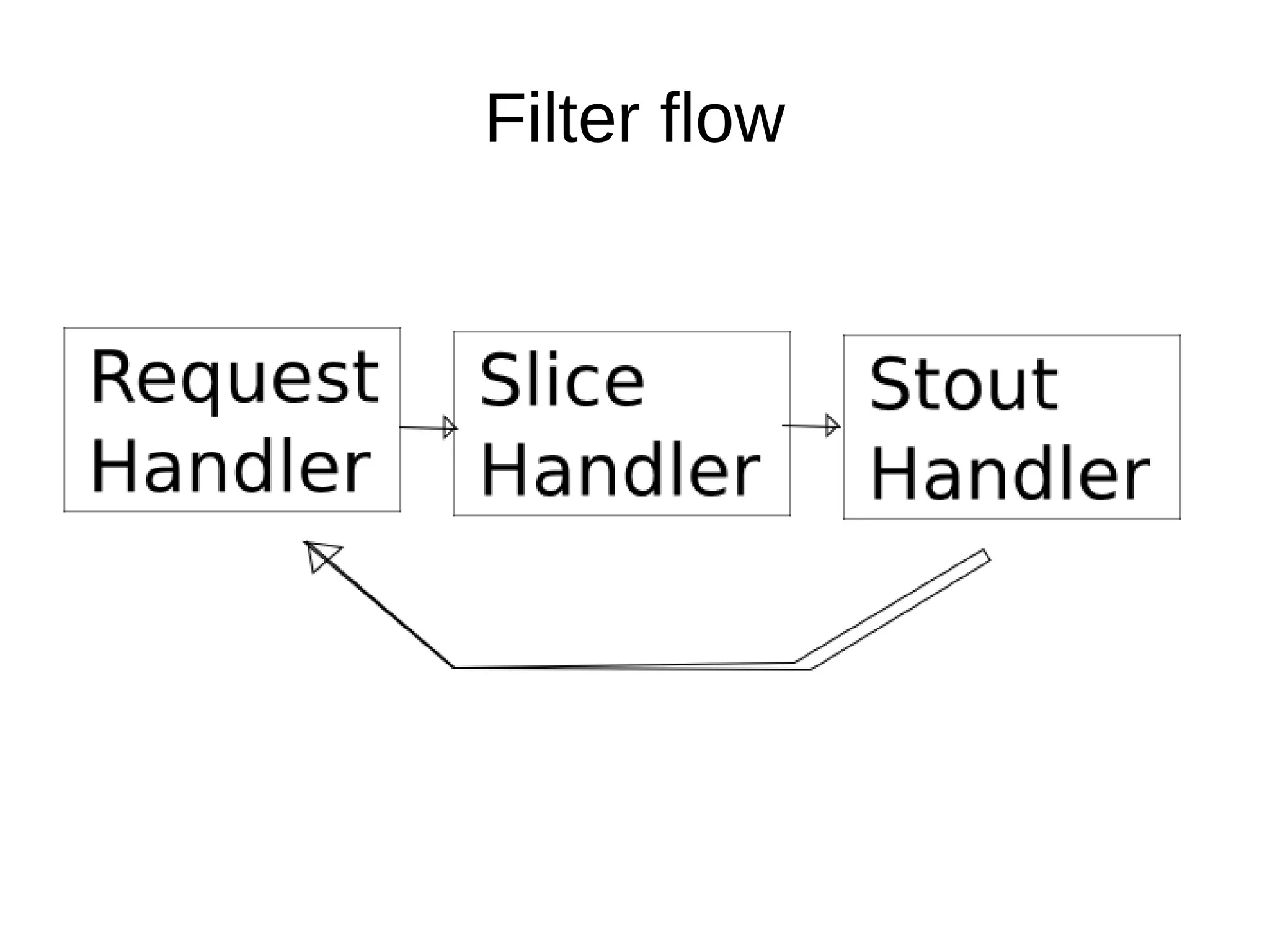



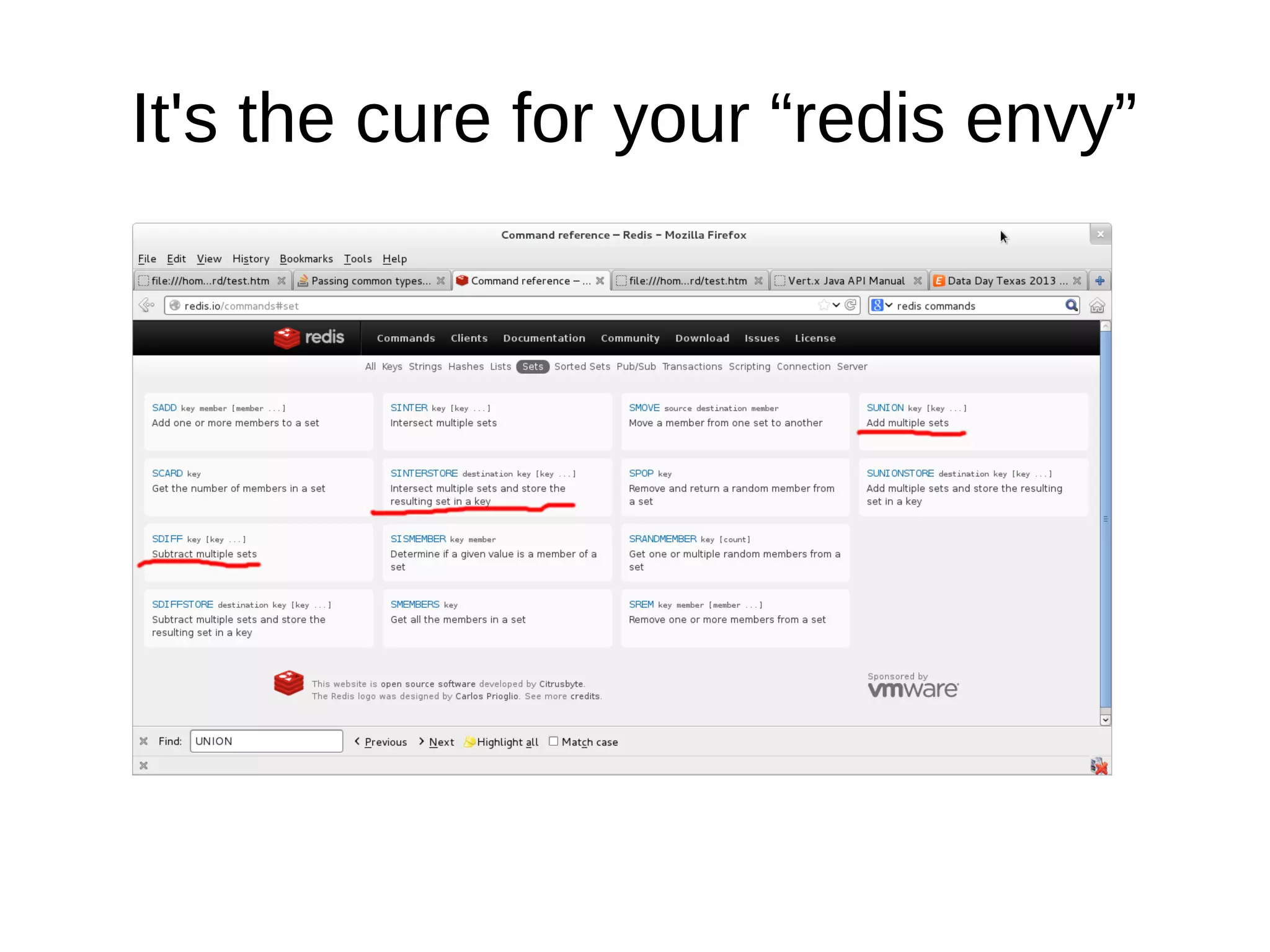



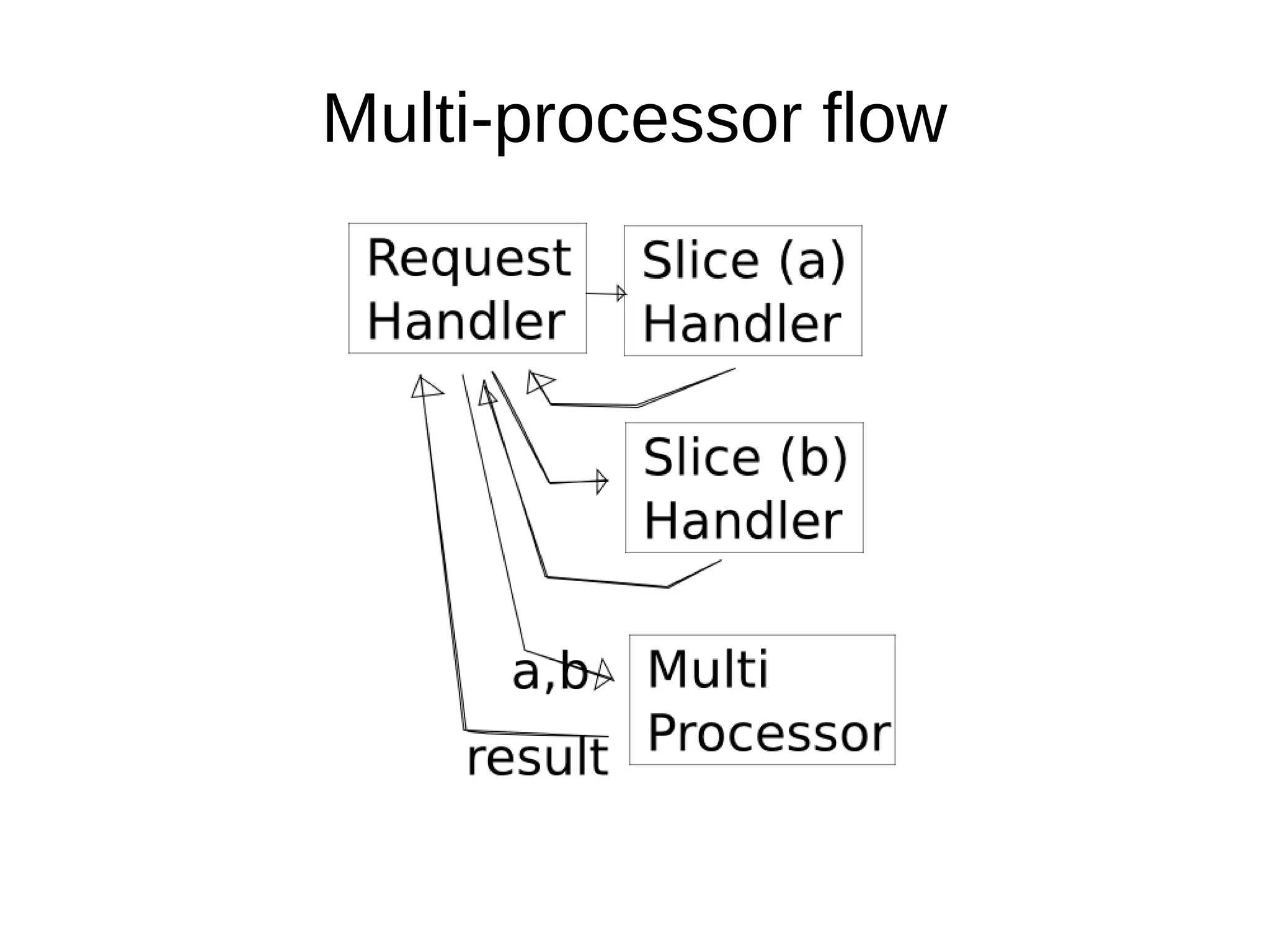





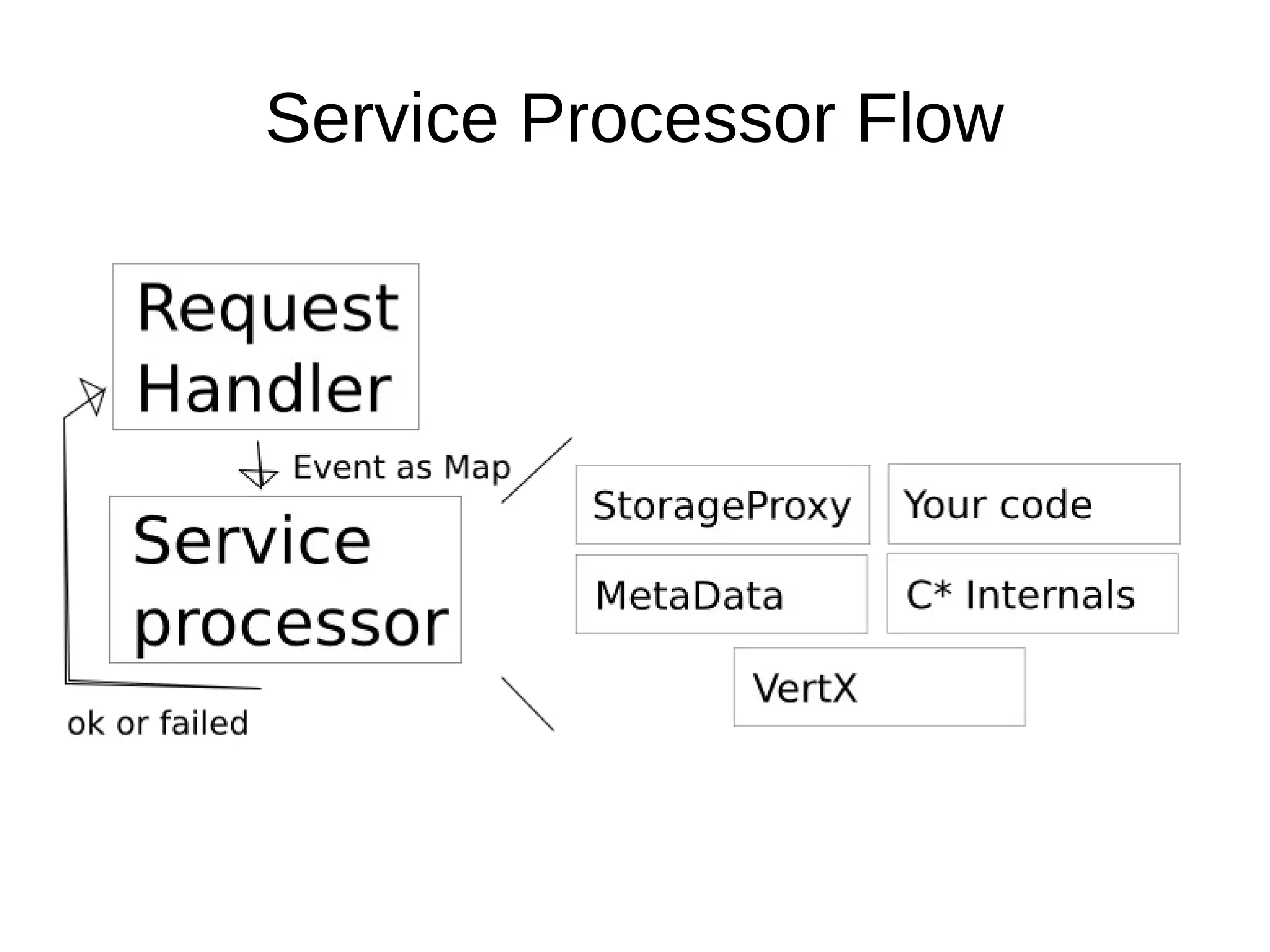



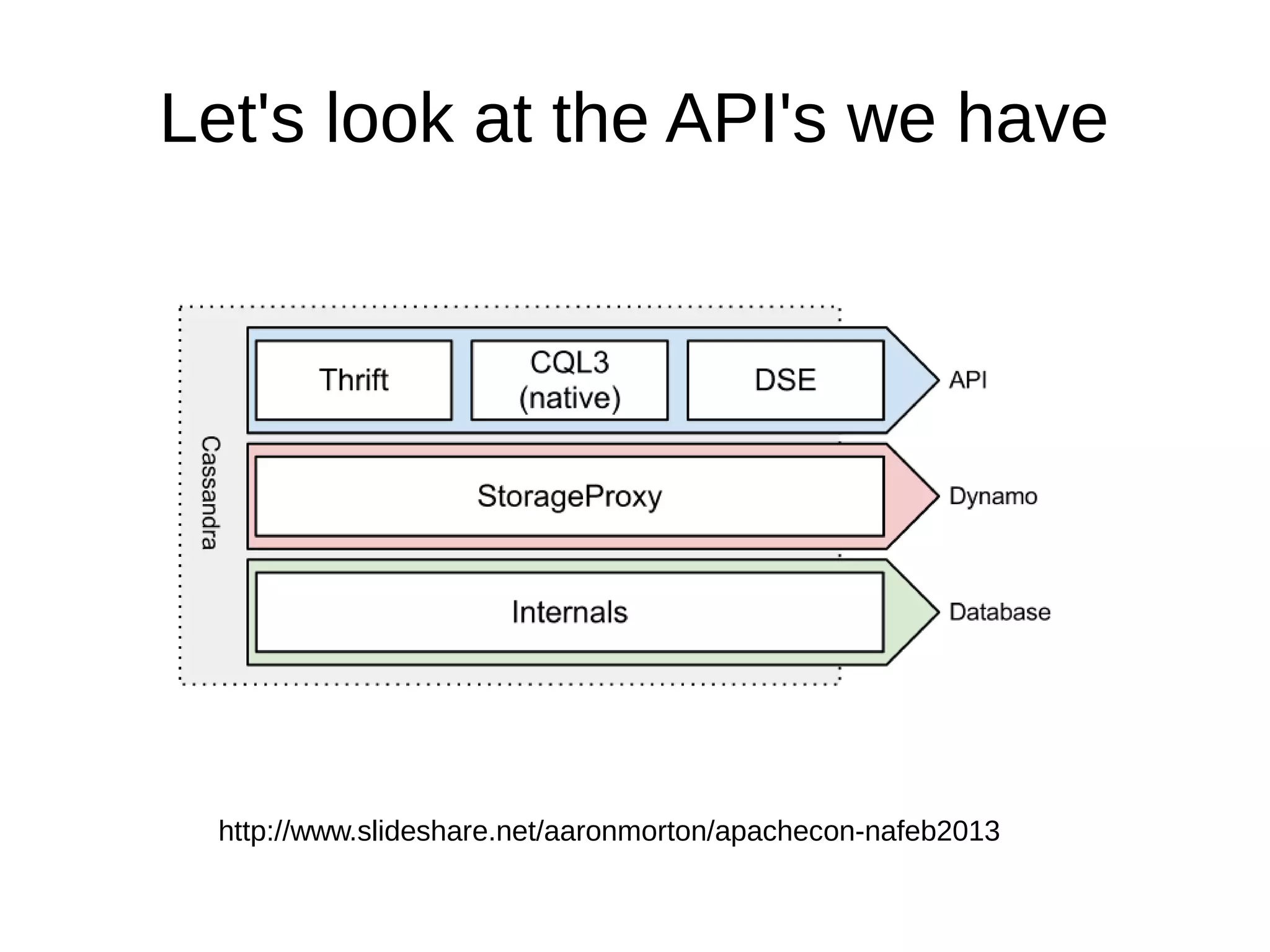
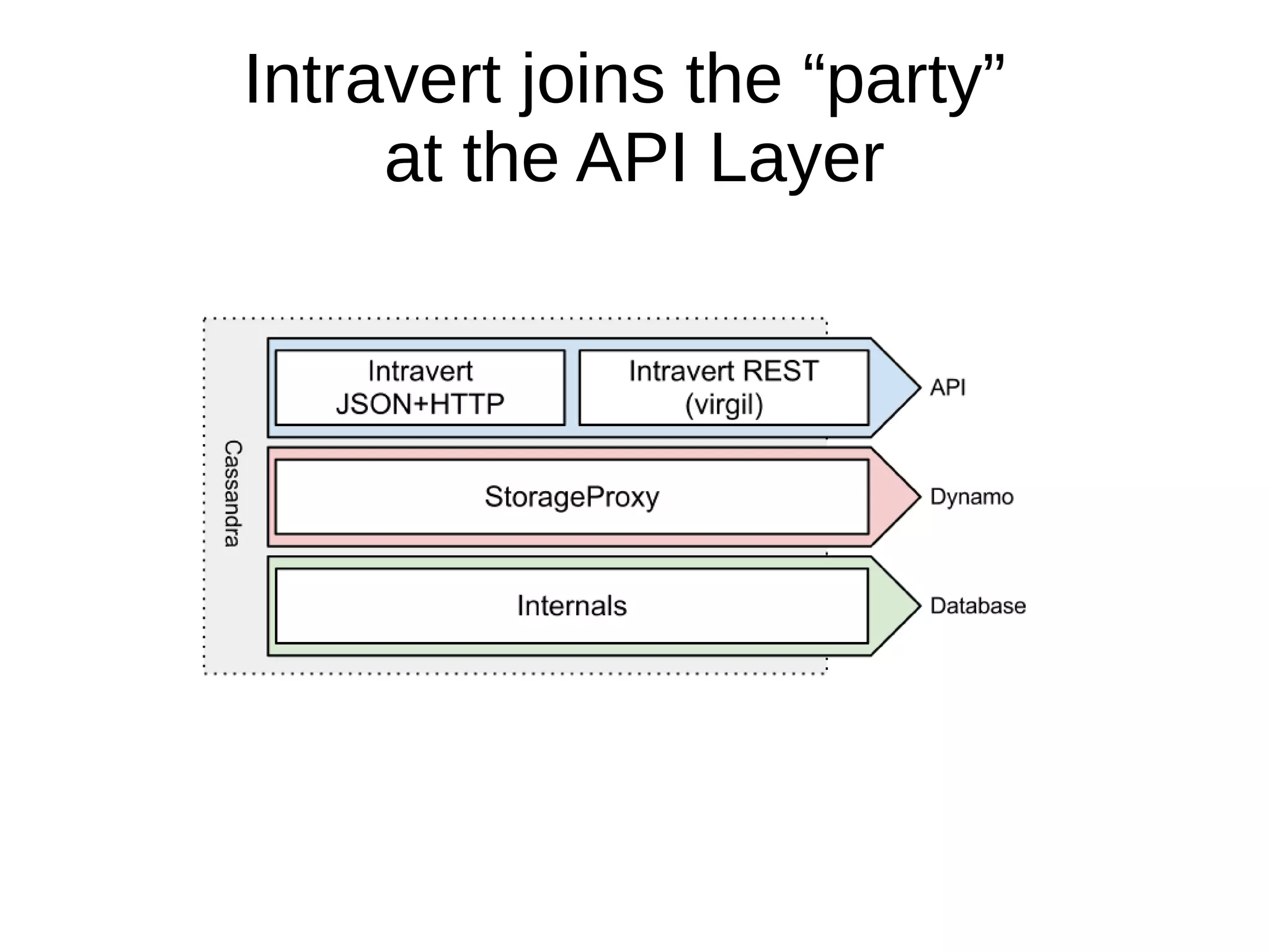
The document discusses database operations and functionalities for a large video website, focusing on user and video data management using a structured query language (CQL). It highlights the integration of intravert with Cassandra for efficient data processing, emphasizing server-side filters and multi-processor capabilities to minimize network I/O. Additionally, the text outlines practical filter creation methods in JavaScript and Groovy, showcasing the potential to streamline operations through server-side computations instead of client-side data processing.






















































































