Downloaded 29 times






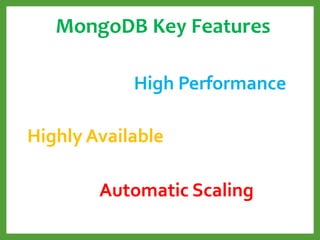
![Format for storing documents
JSON-document
{
"firstName“ : “Steve",
"lastName“ : “Brain",
"address“ :
{
"streetAddress“ : “St.Stefan, 101/101",
"city“ : “London",
"postalCode“ : 101101
},
"phoneNumbers“ : [ "123-1234", "123-4567" ]
}
field: value
field: value
field: value
field: value
field: value
field: value
field: value
Documents correspond to native data types in programming languages
Embedded documents and arrays reduce need for expensive joins](https://image.slidesharecdn.com/mongodb3-151222203708/85/MongoDB-3-0-9-320.jpg)
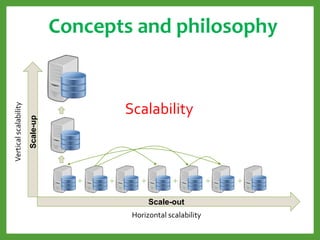
![JSON-format No Normalization
{
_id : “Key123”,
name: “Jane”,
phones: [123, 456],
…
}
Id name
Key123 Jane
Id Phone
1 123
2 456
PersonId PhoneId
Key123 1
Key123 2
Document-oriented data Model](https://image.slidesharecdn.com/mongodb3-151222203708/85/MongoDB-3-0-10-320.jpg)
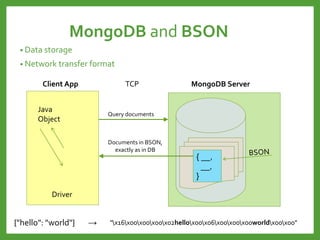

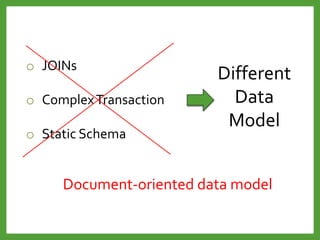
![INSERT
db.users.insert
(
{
name: “John A",
age: 55,
status: "A"
}
)
INSERT INTO [users]
(name, age, status)
VALUES
(“John A”, 55, “A”)](https://image.slidesharecdn.com/mongodb3-151222203708/85/MongoDB-3-0-14-320.jpg)
![db.users.find
(
{
name: “Johan A”
}
)
SELECT *
FROM
[users]
WHERE
name = “JohanA”
SELECT](https://image.slidesharecdn.com/mongodb3-151222203708/85/MongoDB-3-0-15-320.jpg)
![UPDATE
db.users.update
(
{ age: { $gt: 25 } },
{ $set: { status: “D" } }
)
UPDATE [users]
SET
status = “D”
WHERE
age > 25](https://image.slidesharecdn.com/mongodb3-151222203708/85/MongoDB-3-0-16-320.jpg)
![db.users.remove
(
{
status: "D"
}
)
DELETE FROM
[users]
WHERE
status = “D”
DELETE](https://image.slidesharecdn.com/mongodb3-151222203708/85/MongoDB-3-0-17-320.jpg)

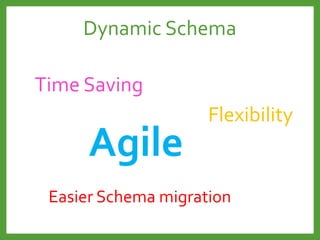

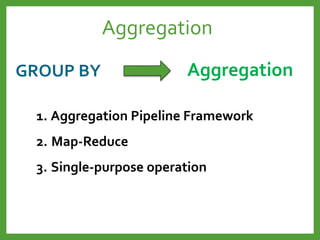
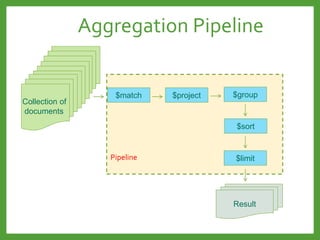
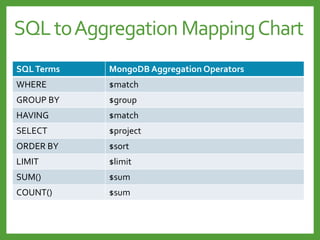
![Map-Reduce
Input
, 1
, 1
, 1
, 1
, 1
, 1
, 1
, 1
, 1
Map
(emit (k,v))
, [1,1]
, [1,2]
, [1,3]
Reduce
$sum(keys)
Final Result
, 2
, 3
, 4
Count process](https://image.slidesharecdn.com/mongodb3-151222203708/85/MongoDB-3-0-24-320.jpg)
![var map = function() {
var key = { shape : this.shape };
var value = { count : 1 };
emit(key, value);
}
var reduce = function( key, values ) {
var sum = 0;
values.forEach(function(value) {
sum += value[‘count’];
});
return { count: sum };
}
this.shapes.mapReduce(map, reduce, {out: {inline:1}})
1st Step 2nd Step
Map-Reduce](https://image.slidesharecdn.com/mongodb3-151222203708/85/MongoDB-3-0-25-320.jpg)
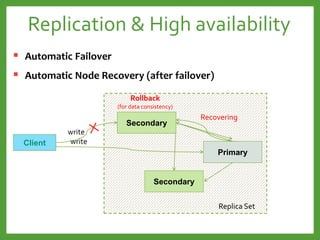
![Replication: Automatic Failover
Client
Driver
Secondary
rsServer3: 27017
Primary
rsServer1: 27017
Secondary
rsServer2: 27017
Replica Set
rsServer1:27017
Connection: host[:port]
Primary
rsServer1: 27017
Replica Set Config
rsServer1:27017
rsServer2:27017
rsServer3:27017
Replica Set Config
rsServer1:27017
rsServer2:27017
rsServer3:27017
Secondary
rsServer2: 27017
Secondary
rsServer3: 27017
Primary
rsServer2: 27017
isMaster?
NOYES
rsServer2:27017](https://image.slidesharecdn.com/mongodb3-151222203708/85/MongoDB-3-0-29-320.jpg)
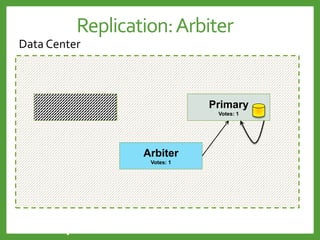
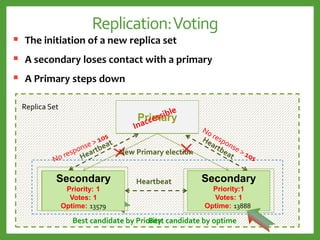
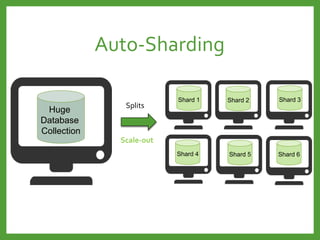
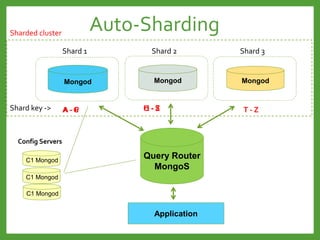
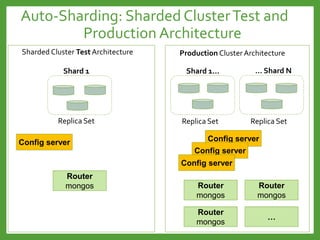
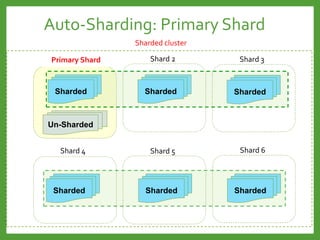
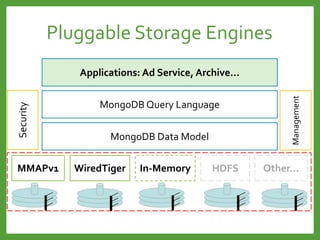
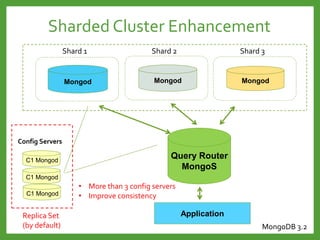
![Auto-Sharding : Shard key
Avoid monotonically Increasing Shard Keys
Avoid immutable Shard Keys
Use a hashed shard key or select a field that does not increase
or decrease monotonically
You cannot change a shard key after sharding the collection.
Mongod
Shard 2
Mongod
Shard 1
Mongod
Shard 3
[1 … 100] [101… 200] [201…*]
Write load for
the last shard
Write load evenly](https://image.slidesharecdn.com/mongodb3-151222203708/85/MongoDB-3-0-36-320.jpg)

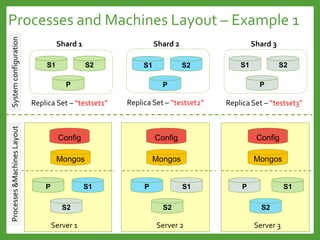
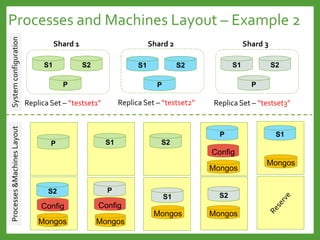

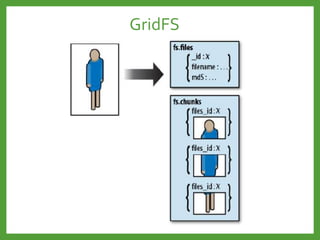
![Full Index Support
• Default index. Field: _id.
• Index on sub-documents. Field: name.lastName.
• Compound indexes. Fields: age and sex.
• Index on array. Field: characterization.
• TTL indexes. Field: visitDate.
• Geospatial indexes. Field: location.
• Text indexes. Field: description.
{
_id: …,
name: {
lastName: “Smith”,
firstName: “John”},
age: 65,
sex: male,
characterization:
[ “smart”, “kind”, …],
visitDate: 06 Jan 2013,
location: {x:…, y: …},
description: “The text for
indexes.”
….
}](https://image.slidesharecdn.com/mongodb3-151222203708/85/MongoDB-3-0-43-320.jpg)







The document provides an overview of MongoDB, a document-oriented database, covering its concepts, features, and operational functionalities such as CRUD operations, aggregation, and data replication techniques. It discusses the advantages of using MongoDB, including flexibility and dynamic schema, while also addressing its disadvantages, such as lack of transactions and high memory usage for indexes. Additionally, it outlines components of the MongoDB architecture, including sharding and replica sets for scalability and availability.



















































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)



