Download as PDF, PPTX







![Problem
domain
♣
Recommenda;on
systems
(RS)
help
to
match
users
with
items
-‐
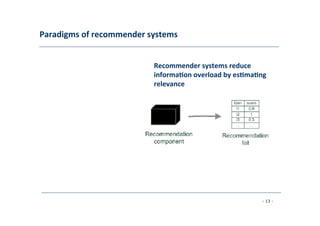
Ease
informa8on
overload
-‐
Sales
assistance
(guidance,
advisory,
persuasion,…)
RS
are
so)ware
agents
that
elicit
the
interests
and
preferences
of
individual
consumers
[…]
and
make
recommenda<ons
accordingly.
They
have
the
poten<al
to
support
and
improve
the
quality
of
the
decisions
consumers
make
while
searching
for
and
selec<ng
products
online.
»
[Xiao
&
Benbasat,
MISQ, 2007]
♣
Different
system
designs
/
paradigms
-‐
Based
on
availability
of
exploitable
data
-‐
Implicit
and
explicit
user
feedback
-‐
Domain
characteris8cs
- 11 -](https://image.slidesharecdn.com/recommndersystem-140529032920-phpapp02/85/Recommender-Systems-Part-1-Introduction-to-approaches-and-algorithms-11-320.jpg)
![Recommender
systems
♣
RS
seen
as
a
func;on
[AT05]
♣
Given:
-‐
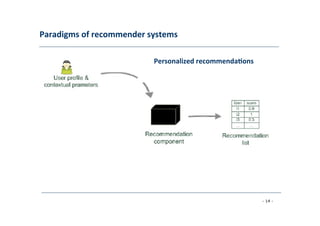
User
model
(e.g.
ra8ngs,
preferences,
demographics,
situa8onal
context)
-‐
Items
(with
or
without
descrip8on
of
item
characteris8cs)
♣
Find:
-‐
Relevance
score.
Used
for
ranking.
♣
Finally:
-‐
Recommend
items
that
are
assumed
to
be
relevant
♣
But:
-‐
Remember
that
relevance
might
be
context-‐dependent
-‐
Characteris8cs
of
the
list
itself
might
be
important
(diversity)
- 12 -](https://image.slidesharecdn.com/recommndersystem-140529032920-phpapp02/85/Recommender-Systems-Part-1-Introduction-to-approaches-and-algorithms-12-320.jpg)
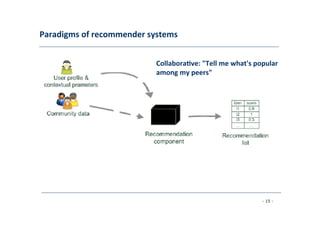
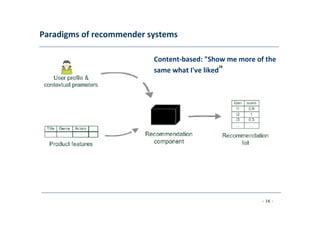









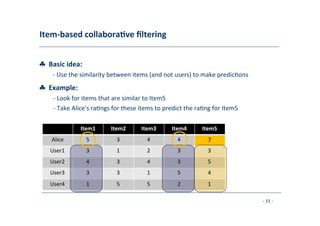




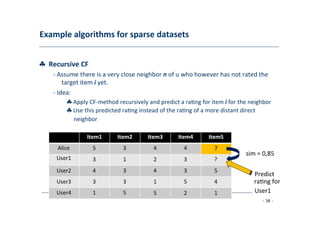
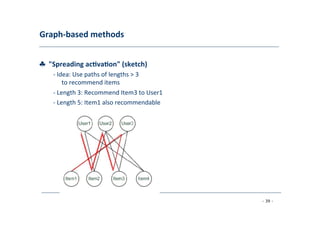












The document discusses recommender systems, emphasizing their application in various areas such as social web and personalized search. It covers techniques like collaborative filtering, content-based filtering, and hybrid models, highlighting their importance in helping users discover products and in improving sales for providers. The document also addresses challenges like data sparsity and offers insights into measurement and evaluation techniques for system success.



































































