Download to read offline


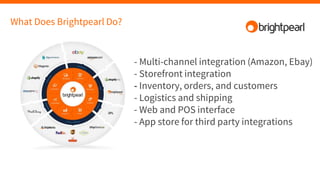
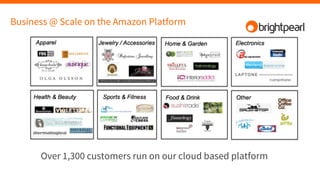







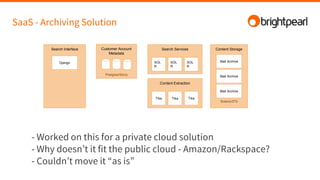
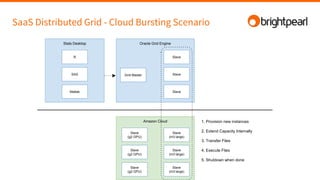



















Brightpearl is a cloud-based business management platform that provides e-commerce, inventory, order, customer, and shipping functionality to over 1,300 customers. It is built on Amazon Web Services (AWS) using various programming languages and services. Some challenges of building and scaling such a platform on AWS include designing for redundancy, performance, concurrency, cost efficiency, and failure tolerance.








































































