




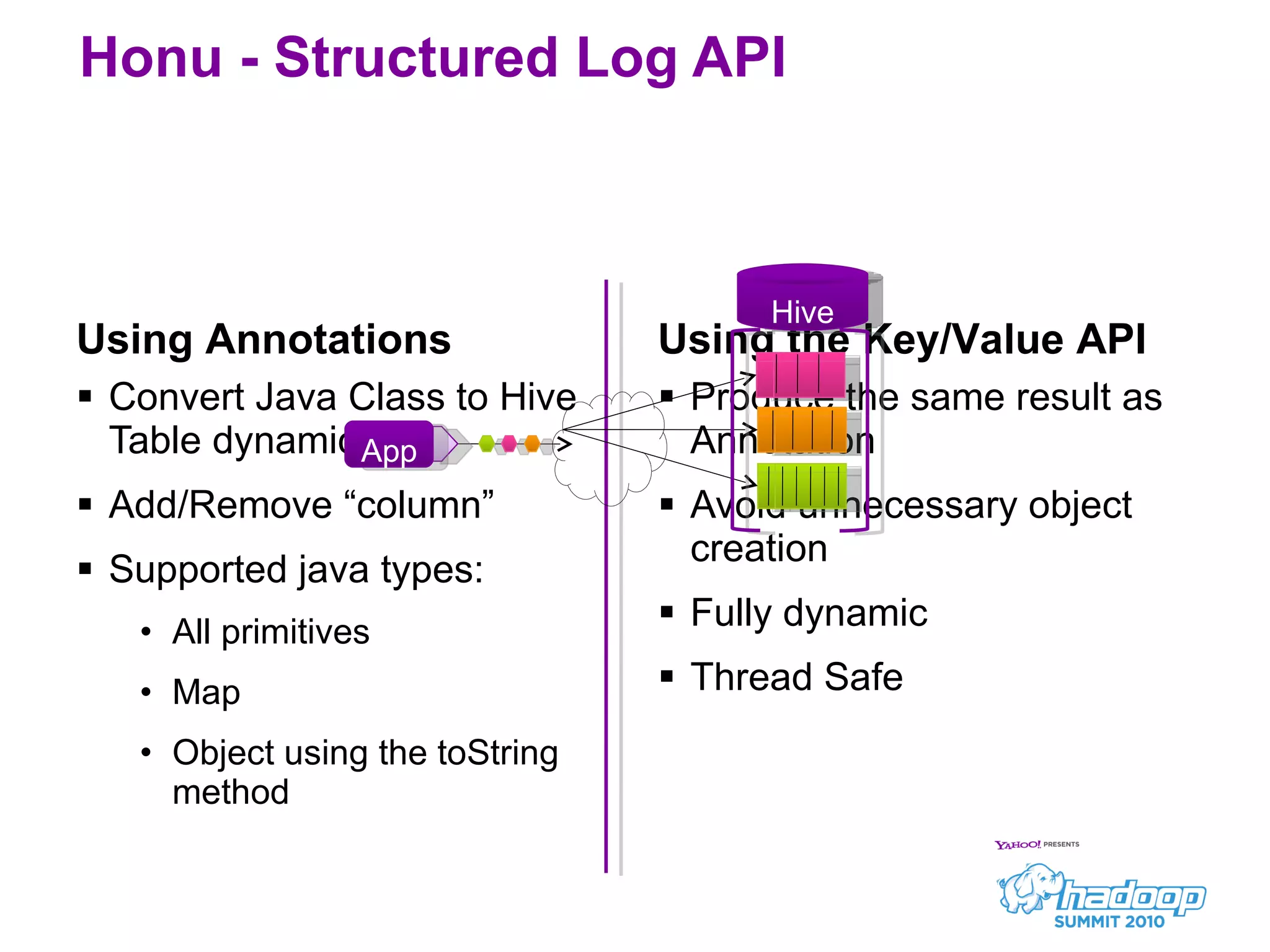
![Structured Log API – Using Annotation @ Resource (table=”MyTable") public class MyClass implements Annotatable { @ Column ("movieId") public String getMovieId() { […] } @Column("clickIndex") public int getClickIndex() { […] } @Column("requestInfo") public Map getRequestInfo() { […] } } DB=MyTable Movied=XXXX clieckIndex=3 requestInfo.returnCode=200 requestInfo.duration_ms=300 requestInfo.yyy=zzz log.info(myAnnotatableObj);](https://image.slidesharecdn.com/7honuhadoopsummit2010-100630134425-phpapp02/75/Honu-A-Large-Scale-Streaming-Data-Collection-and-Processing-Pipeline__HadoopSummit2010-14-2048.jpg)
![Structured Log API - Key/Value API KeyValueSerialization kv ; kv = new KeyValueSerialization(); […] kv.startMessage("MyTable"); kv.addKeyValue("movieid", ”XXX"); kv.addKeyValue("clickIndex", 3); kv.addKeyValue(”requestInfo", requestInfoMap); DB=MyTable Movied=XXXX clickIndex=3 requestInfo.returnCode=200 requestInfo.duration_ms=300 requestInfo.yyy=zzz log.info(kv.generateMessage());](https://image.slidesharecdn.com/7honuhadoopsummit2010-100630134425-phpapp02/75/Honu-A-Large-Scale-Streaming-Data-Collection-and-Processing-Pipeline__HadoopSummit2010-15-2048.jpg)



![Questions? Jerome Boulon [email_address] http://wiki.github.com/jboulon/Honu/](https://image.slidesharecdn.com/7honuhadoopsummit2010-100630134425-phpapp02/75/Honu-A-Large-Scale-Streaming-Data-Collection-and-Processing-Pipeline__HadoopSummit2010-22-2048.jpg)

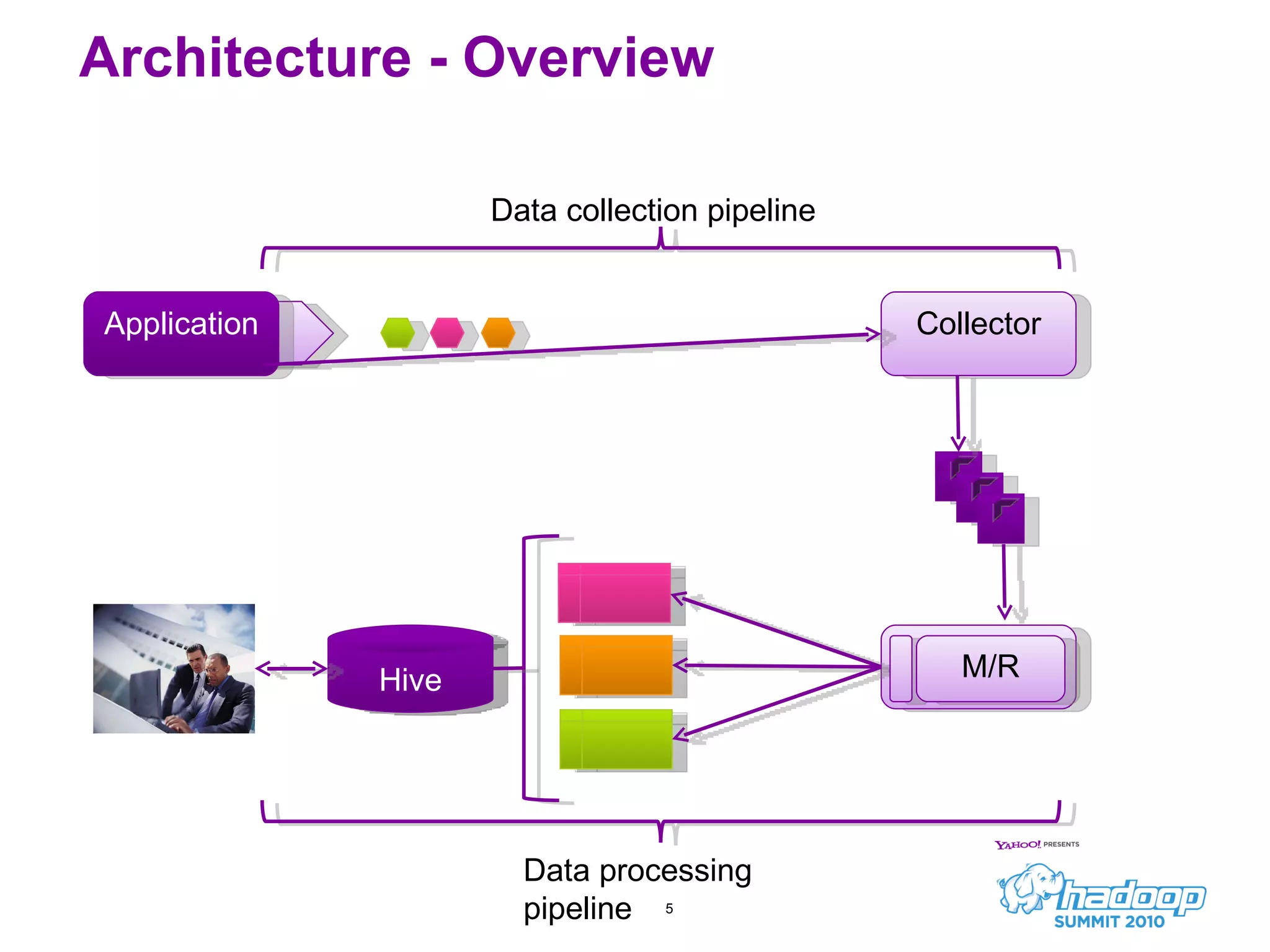
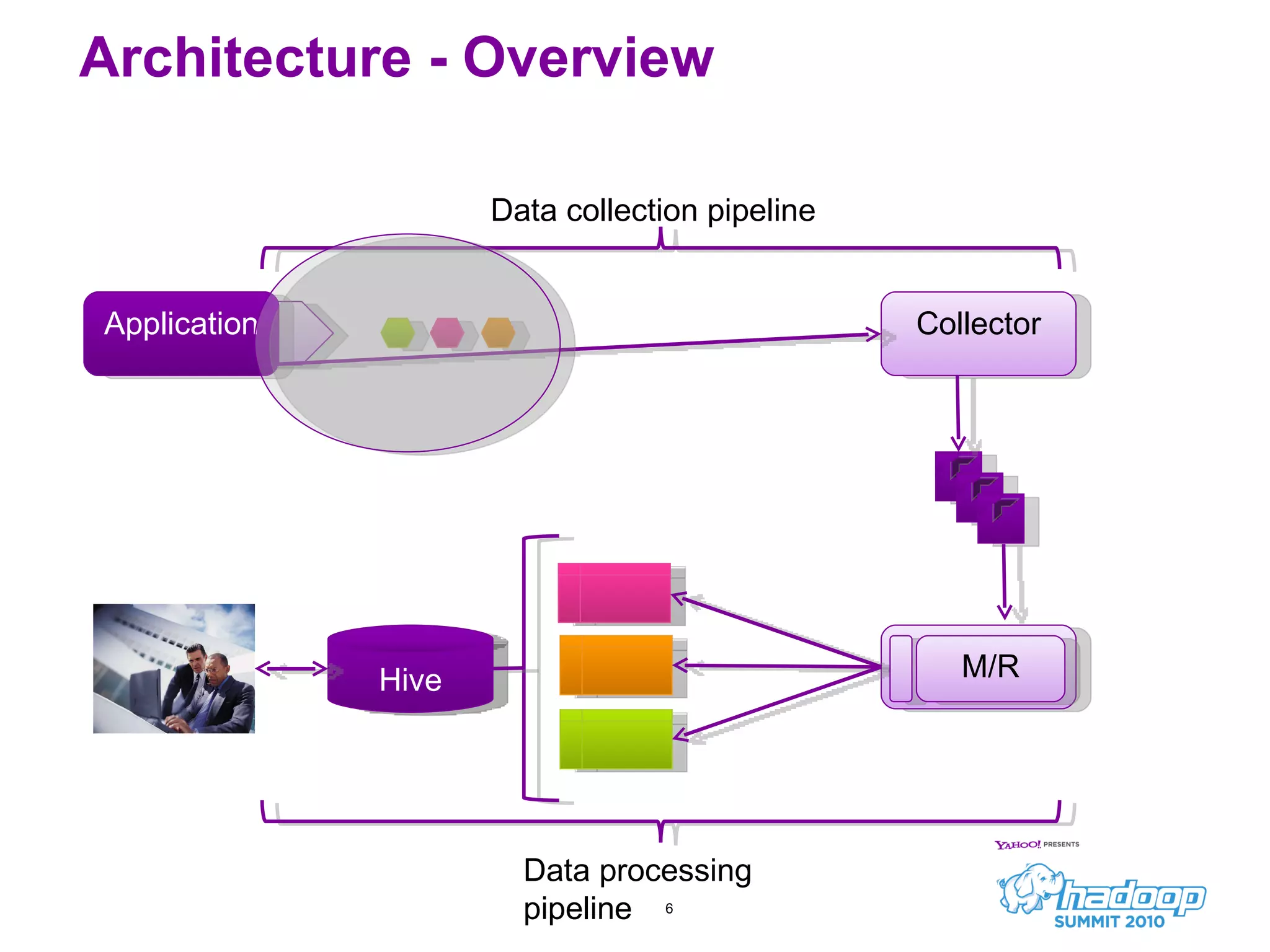
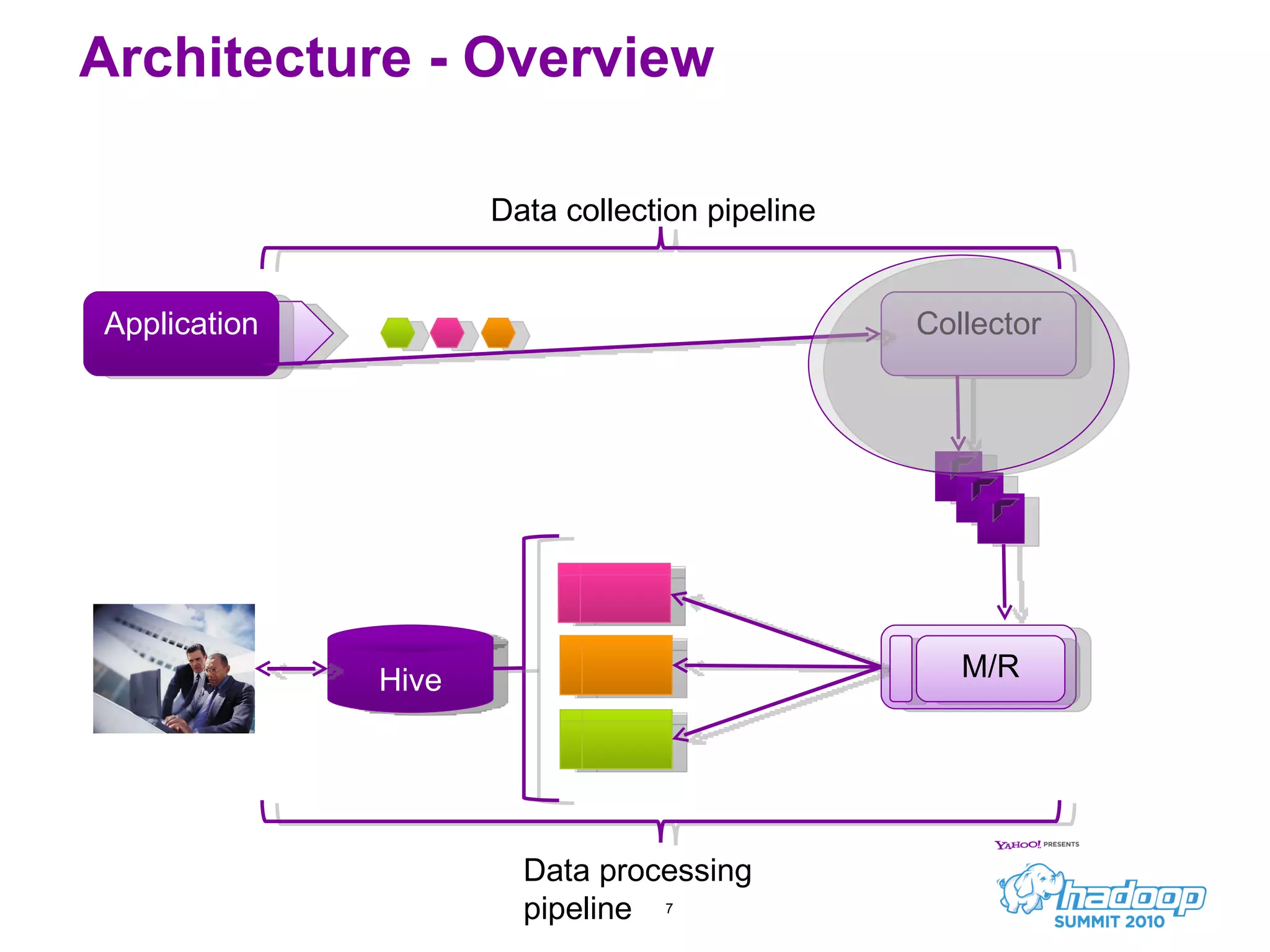
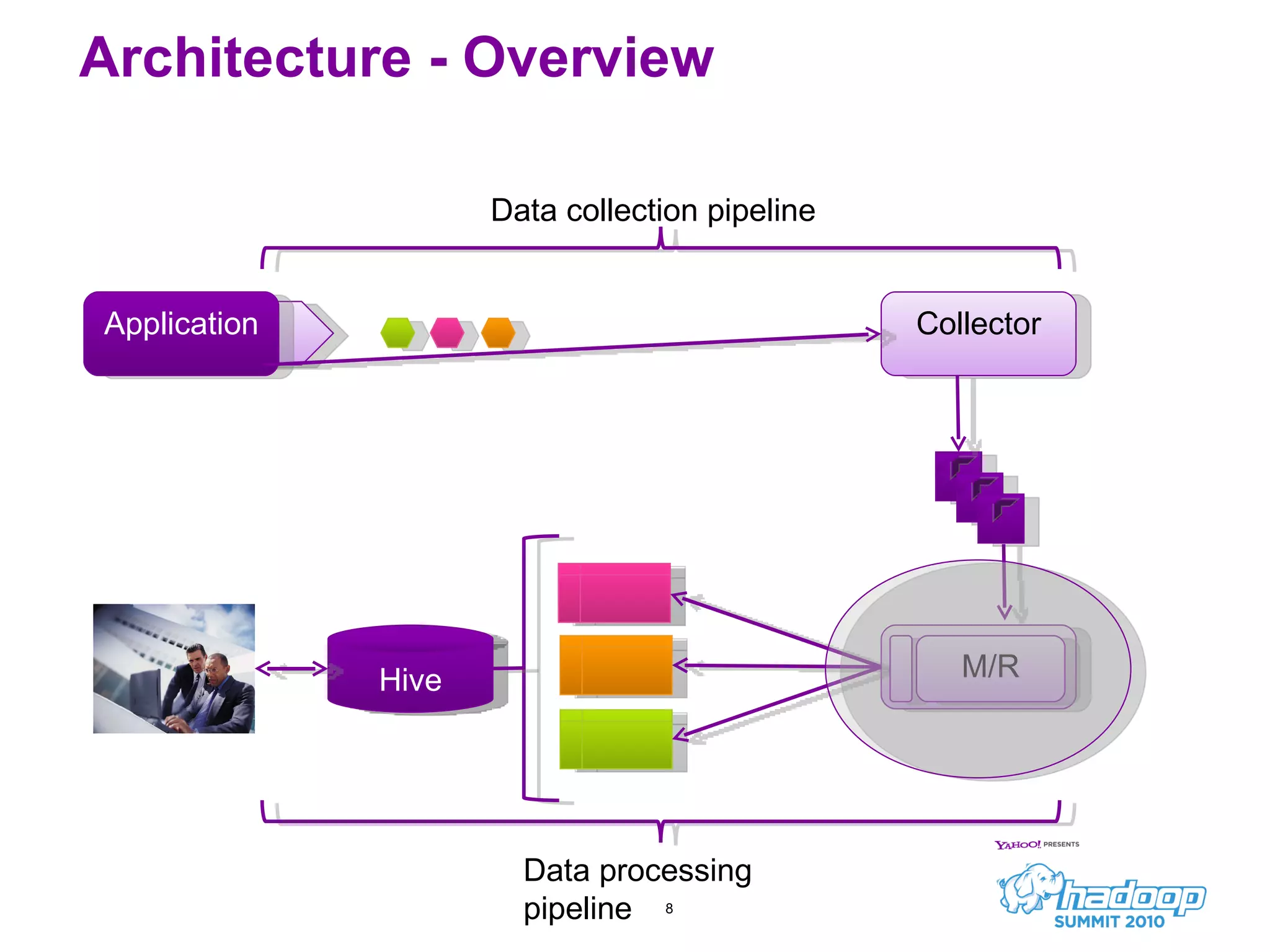
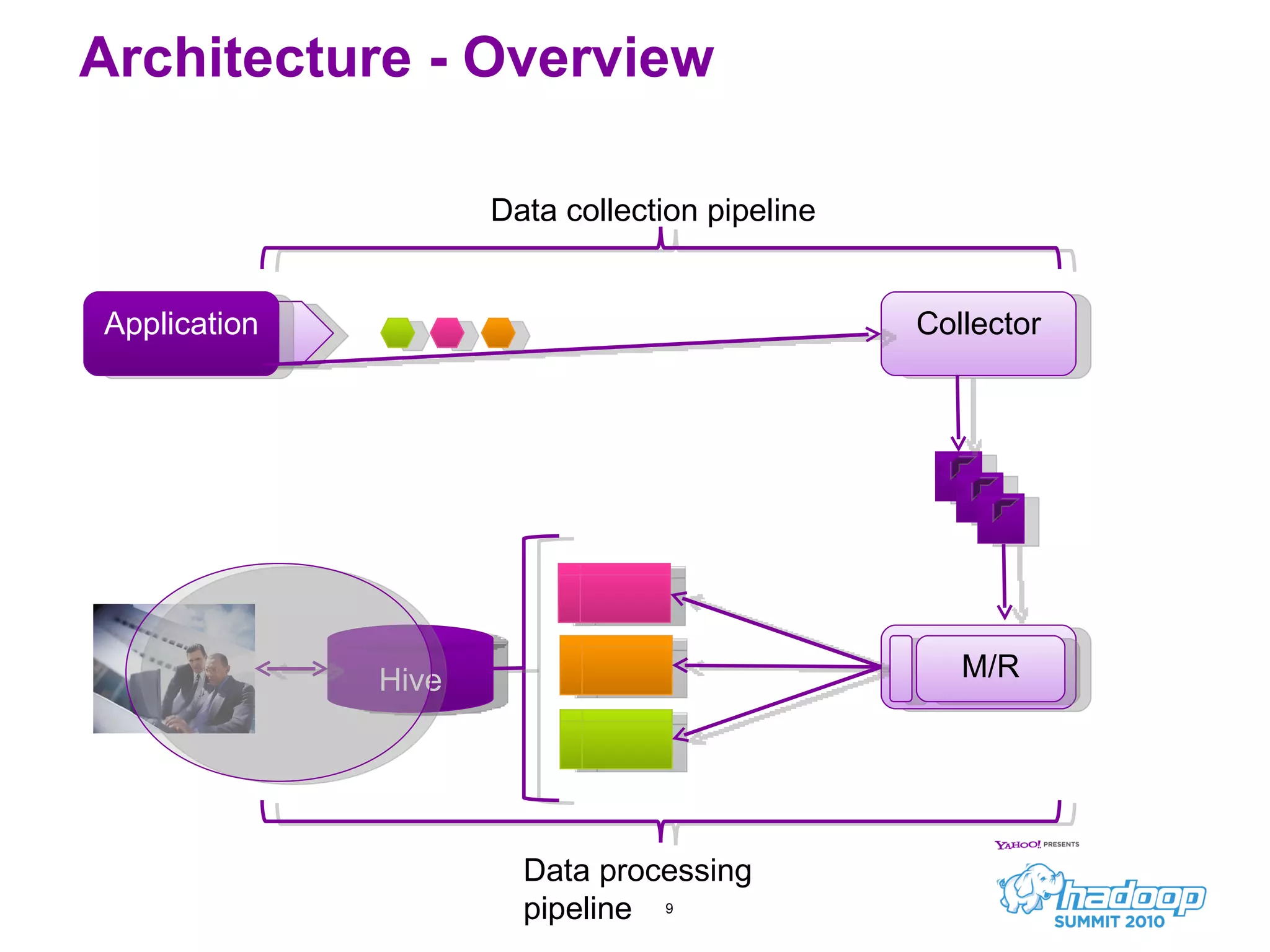
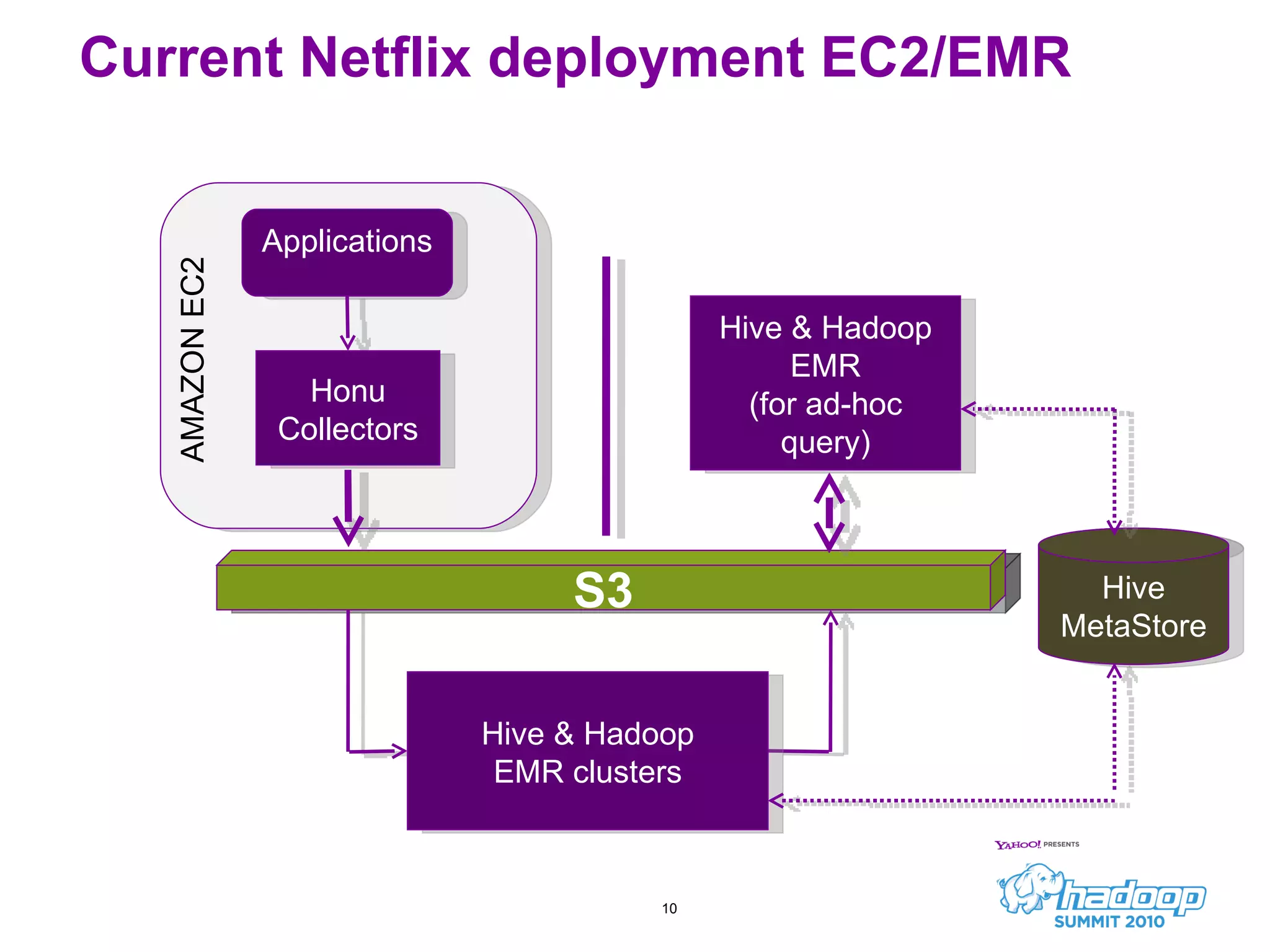
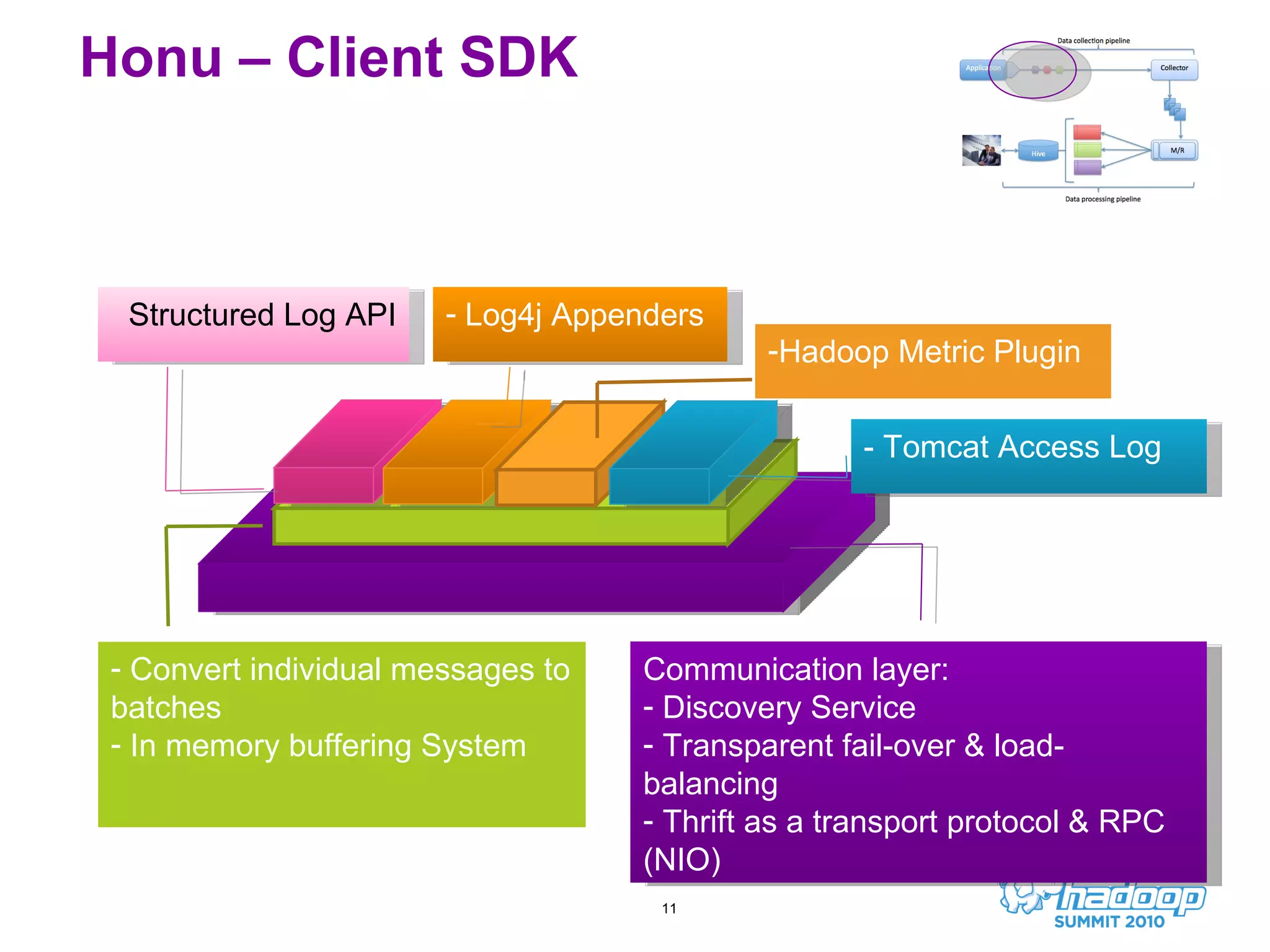
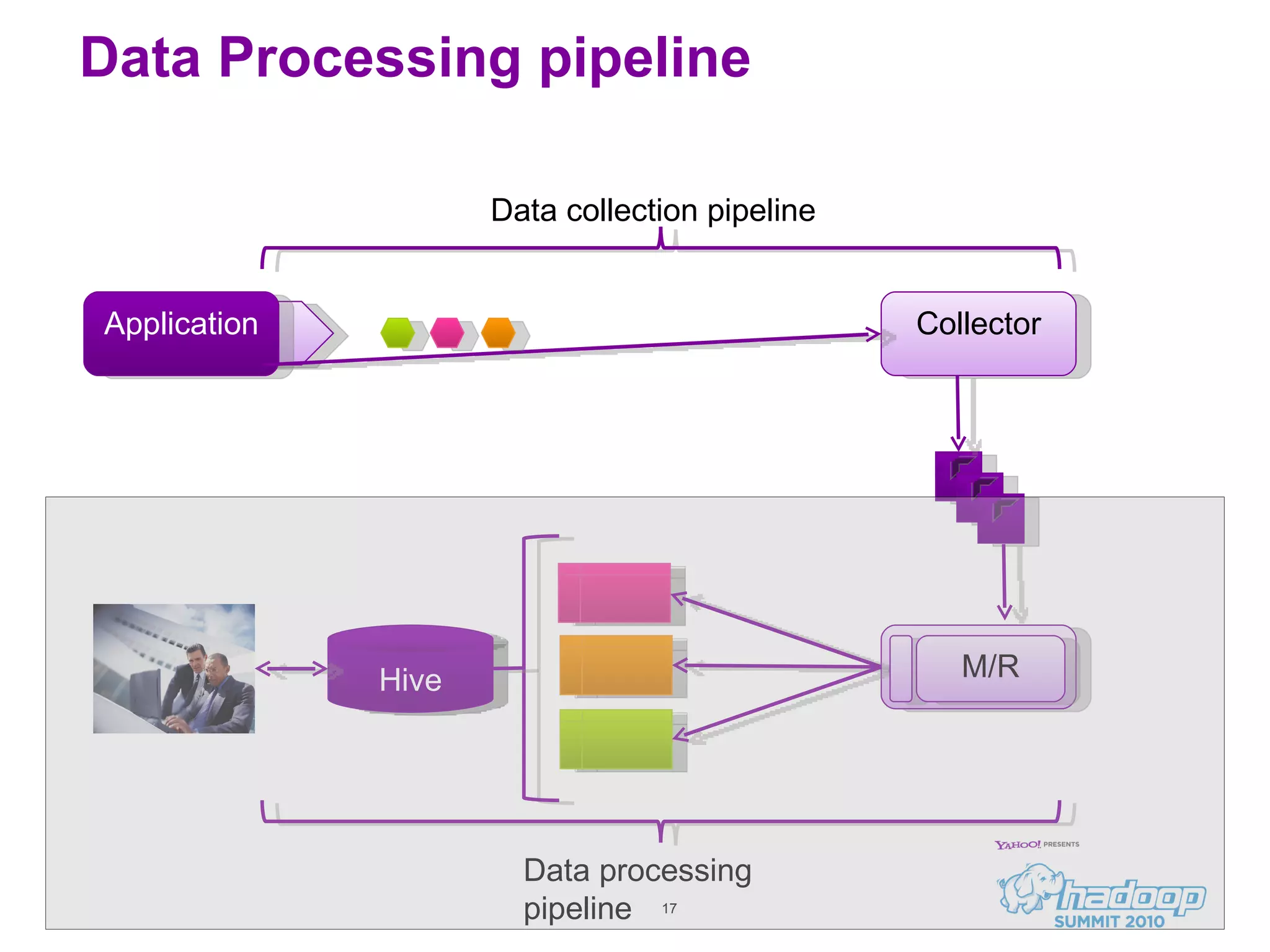
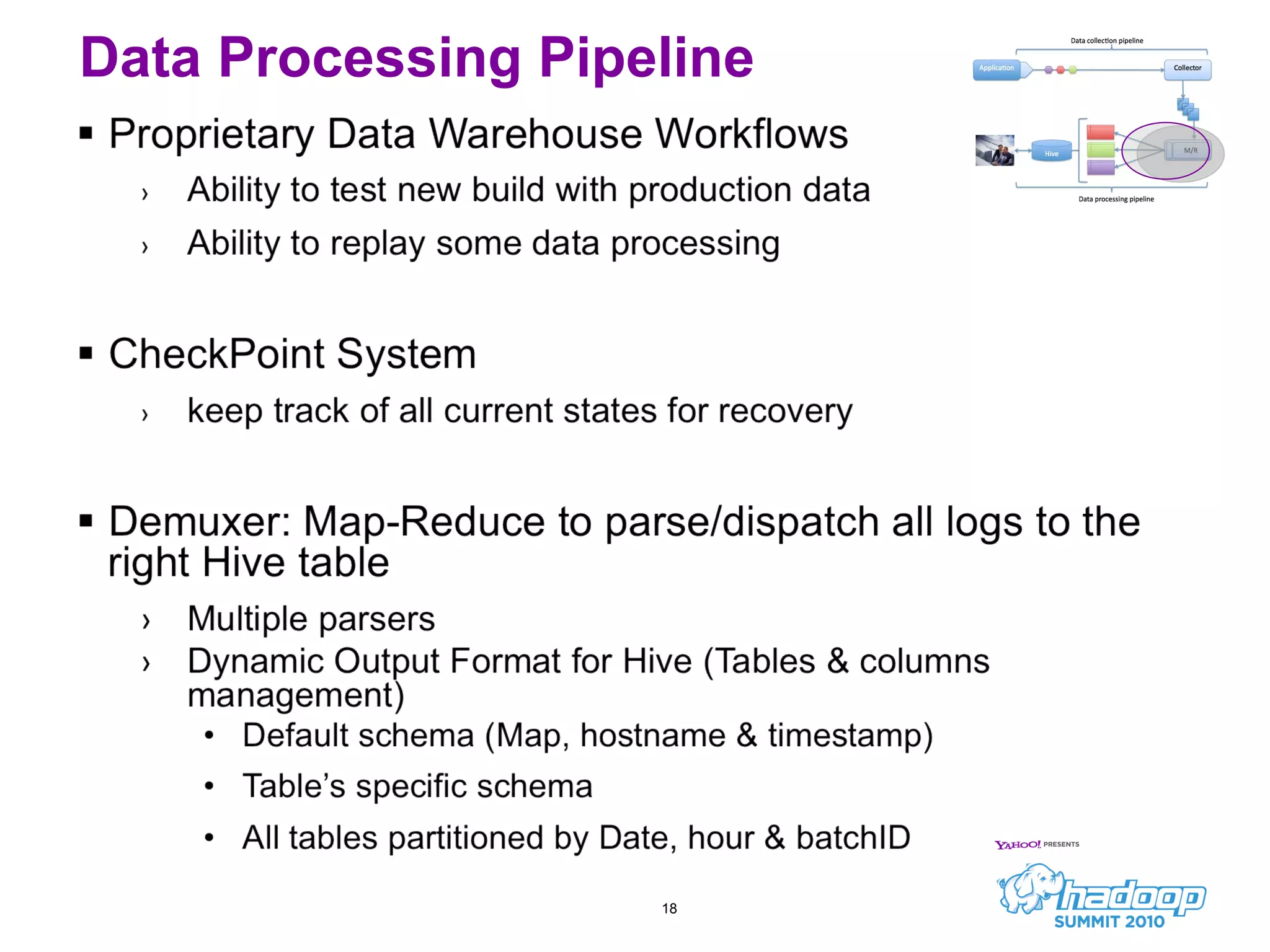
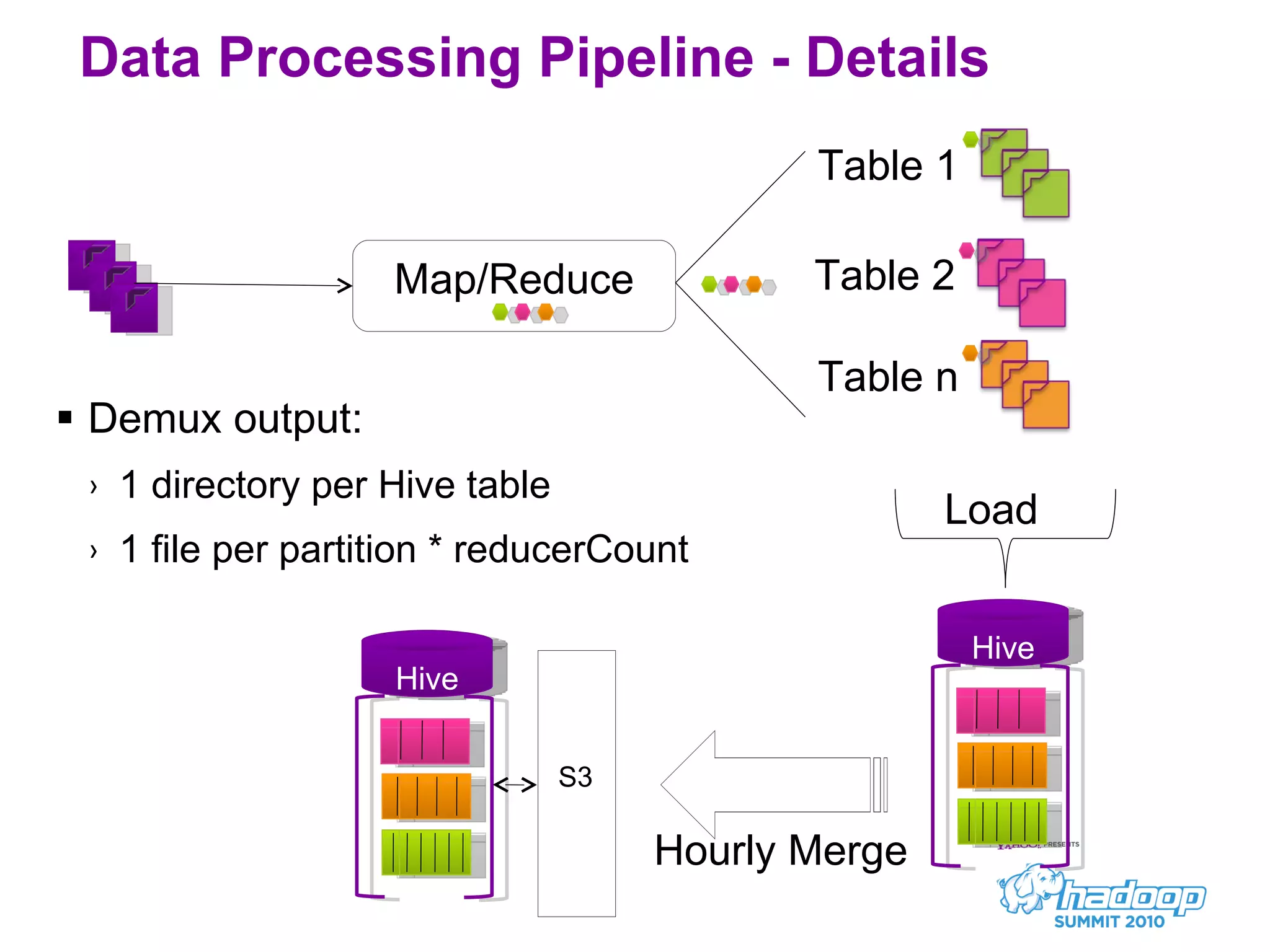
Honu is a large-scale data collection and processing pipeline developed by Netflix, utilizing technologies such as Hadoop and Hive to analyze over a billion log events per day. Its primary goals include scalable log analysis for gaining business insights from various log types, and it enables ad-hoc querying and report generation for engineers and BI access. The project is in production for six months with a roadmap that includes open-sourcing components and real-time integrations.






































![[Pulsar summit na 21] Change Data Capture To Data Lakes Using Apache Pulsar/Hudi](https://cdn.slidesharecdn.com/ss_thumbnails/pulsarsummitna21cdcusinghudipulsardeck-210628151056-thumbnail.jpg?width=640&height=640&fit=bounds)













































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)
