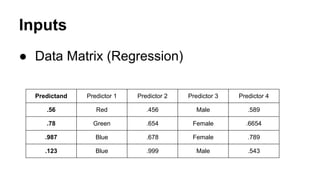
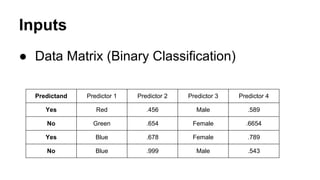
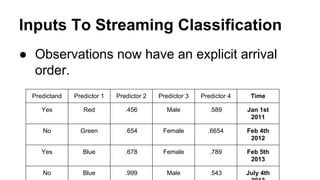
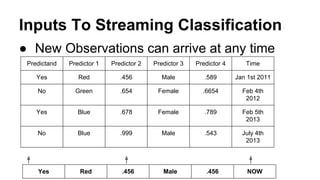
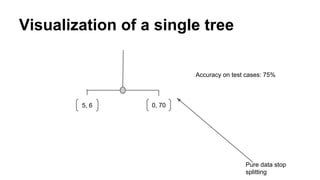
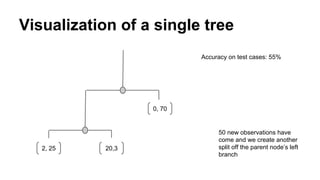
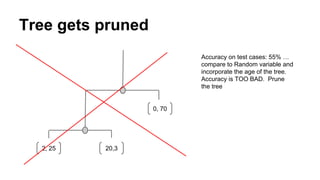
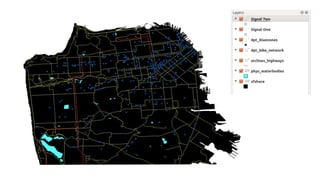
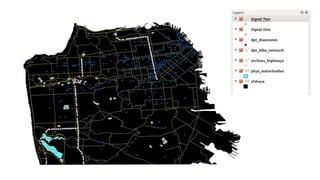
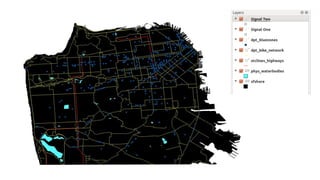
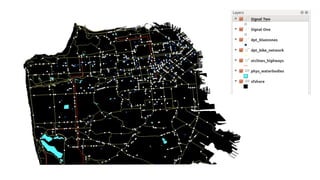
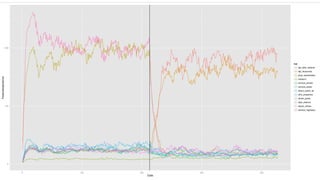
This document provides an overview of online random forest, a machine learning algorithm that can handle streaming data. It discusses how traditional supervised learning algorithms require a static data matrix as input, while streaming data has an explicit time order and new observations can arrive at any time. Online random forest allows trees to learn incrementally from each new observation and drop trees from the forest that perform poorly, enabling it to adapt to changes in important predictors over time. It also scales well by distributing tree computations across actors in a distributed system.