Download to read offline




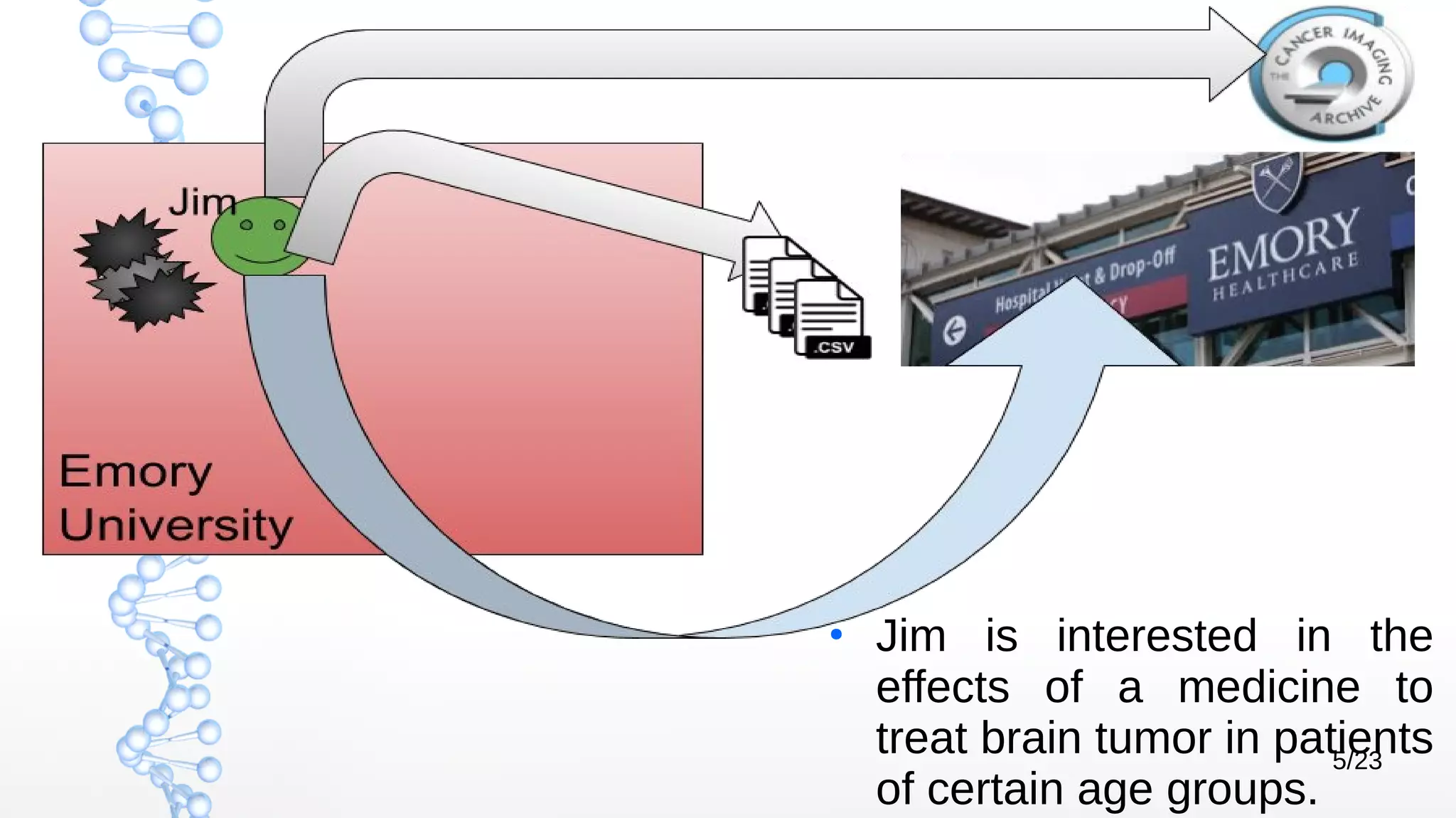

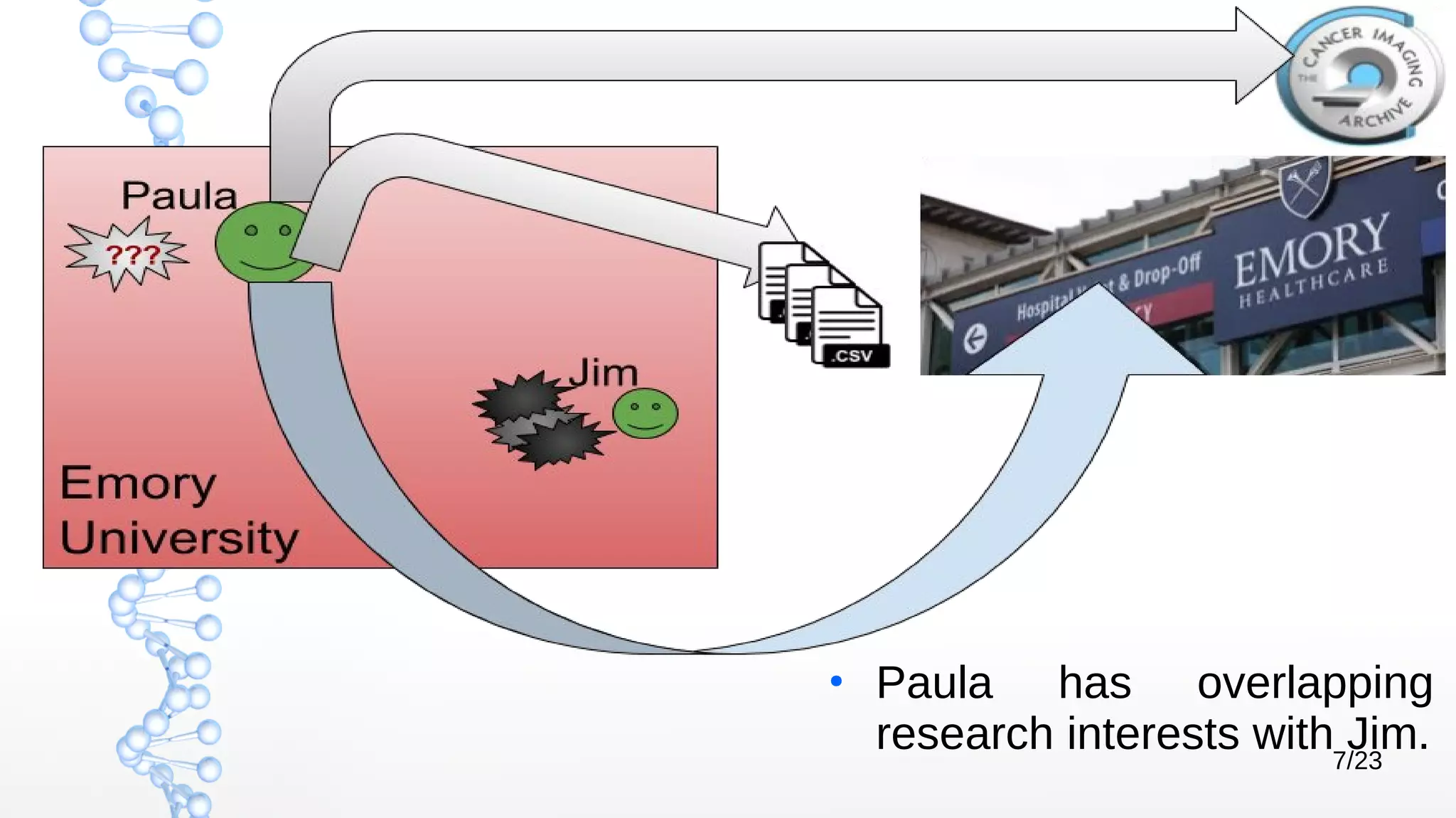

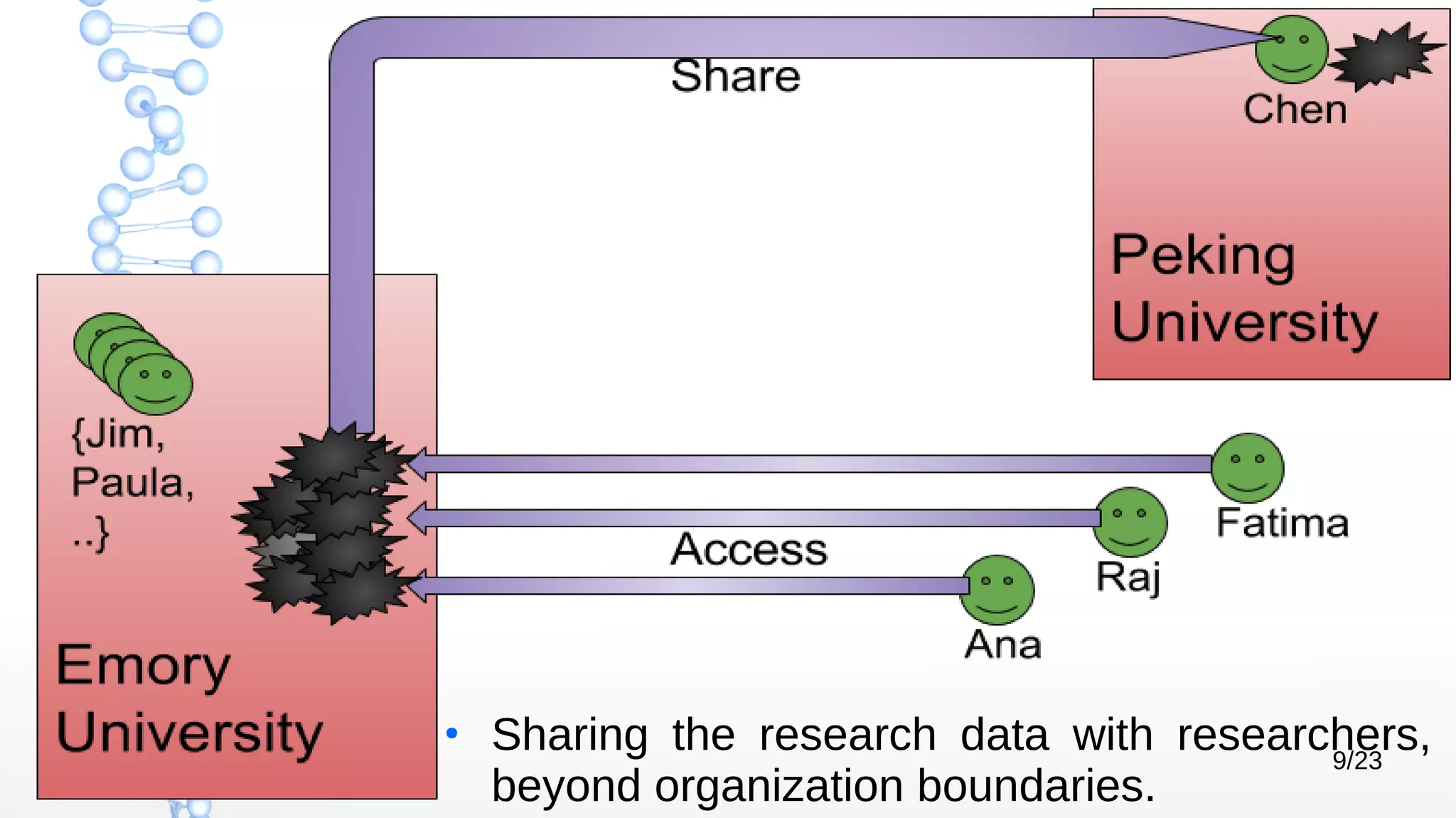




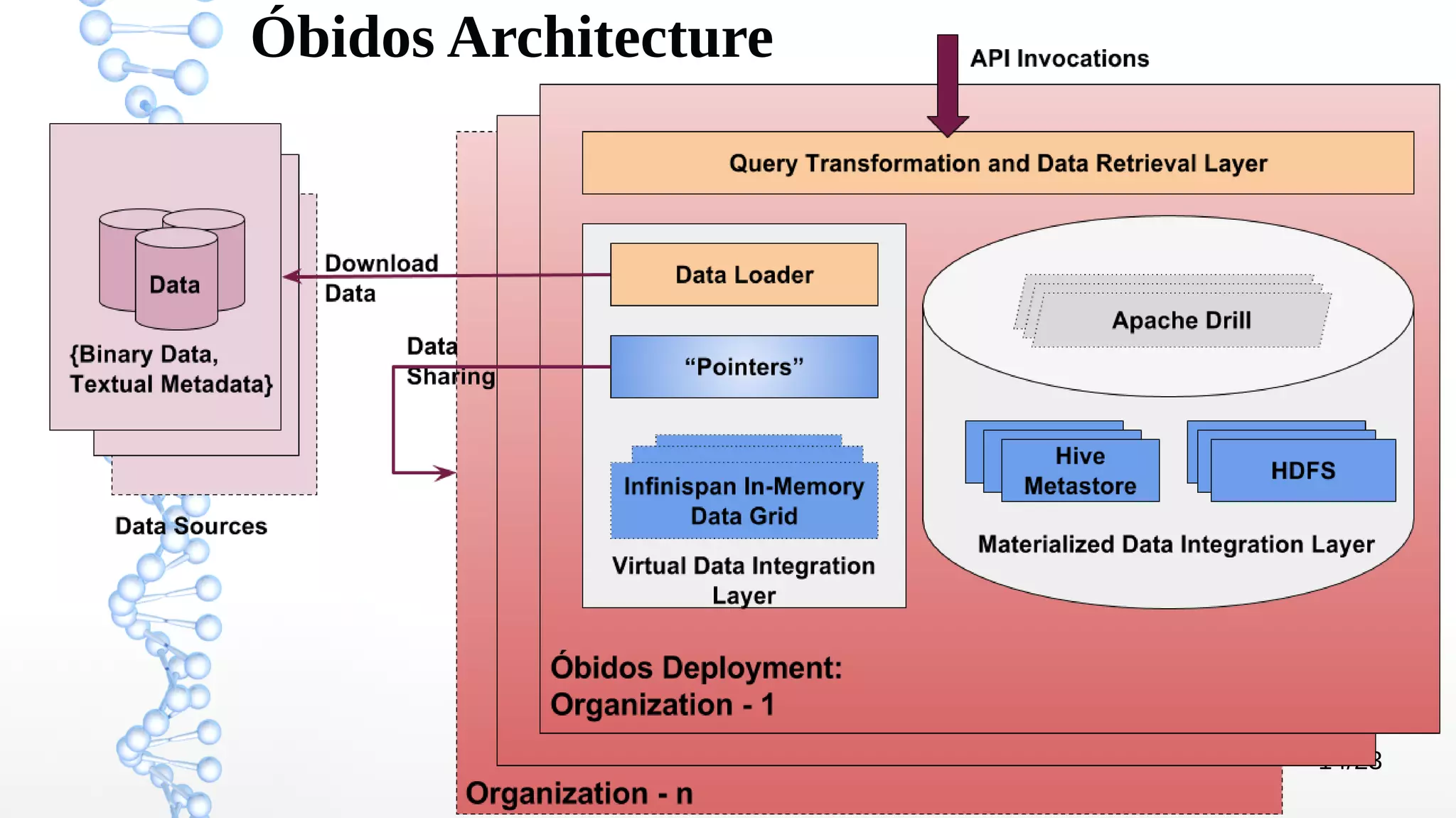
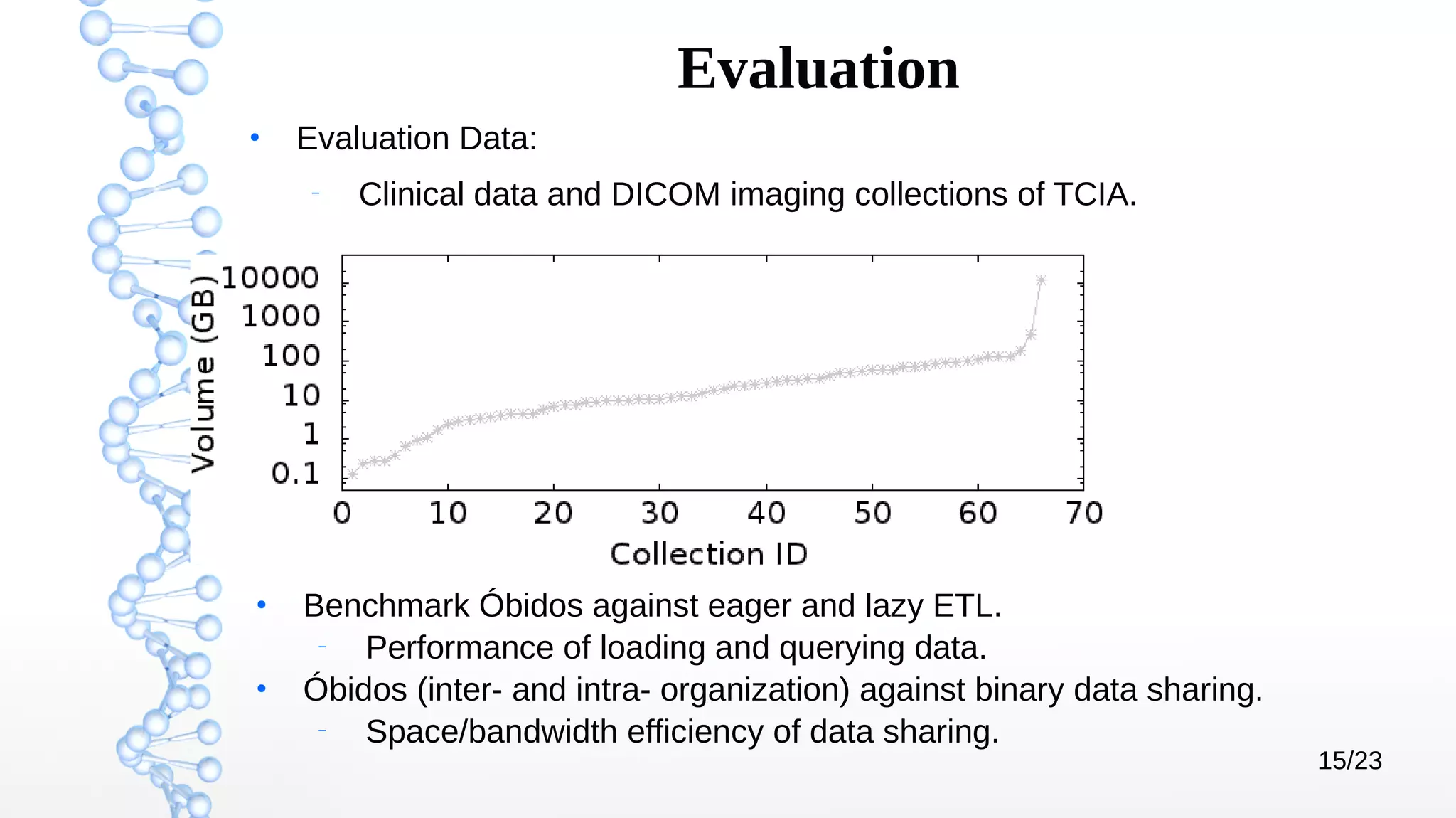
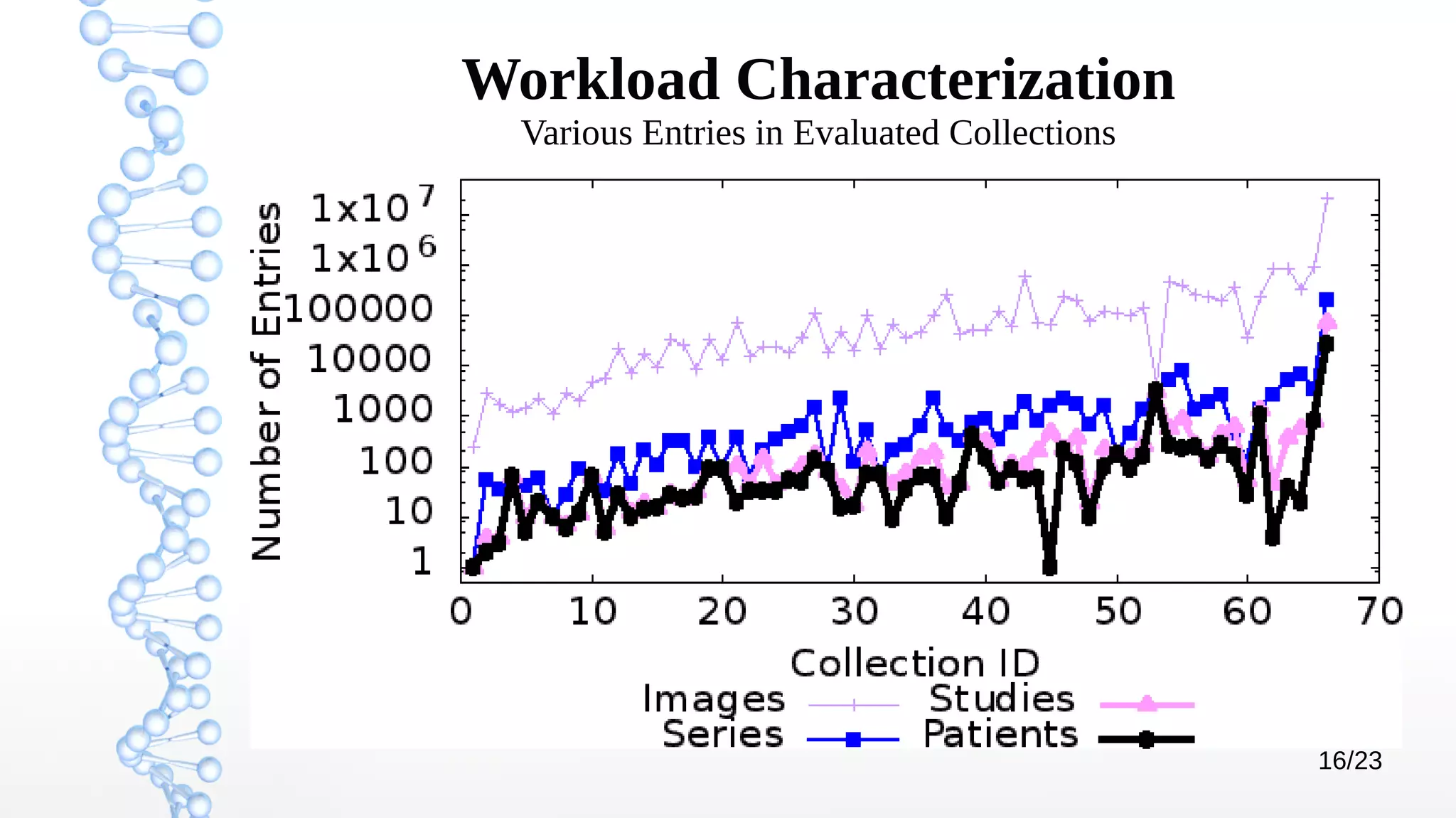
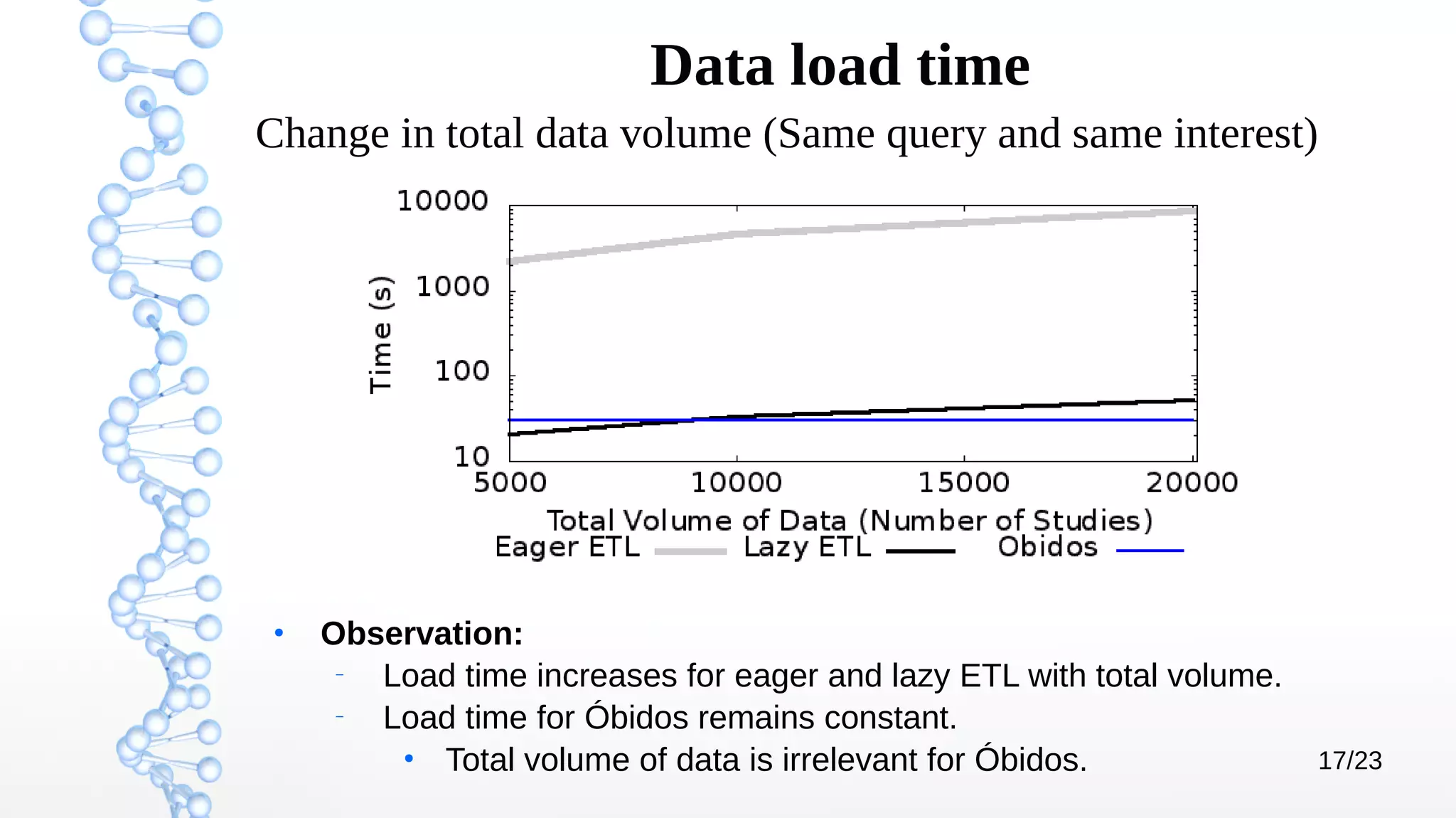
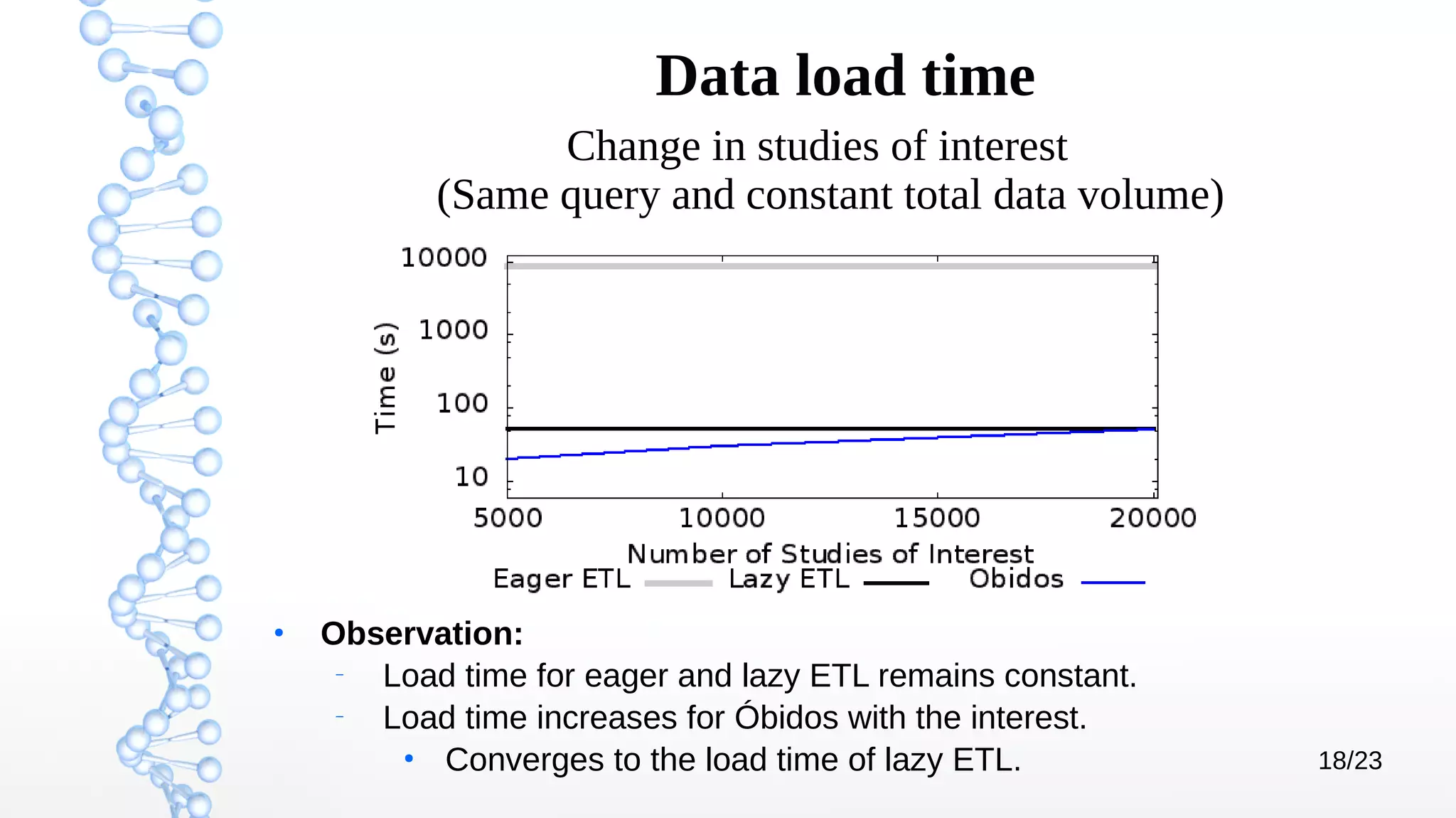
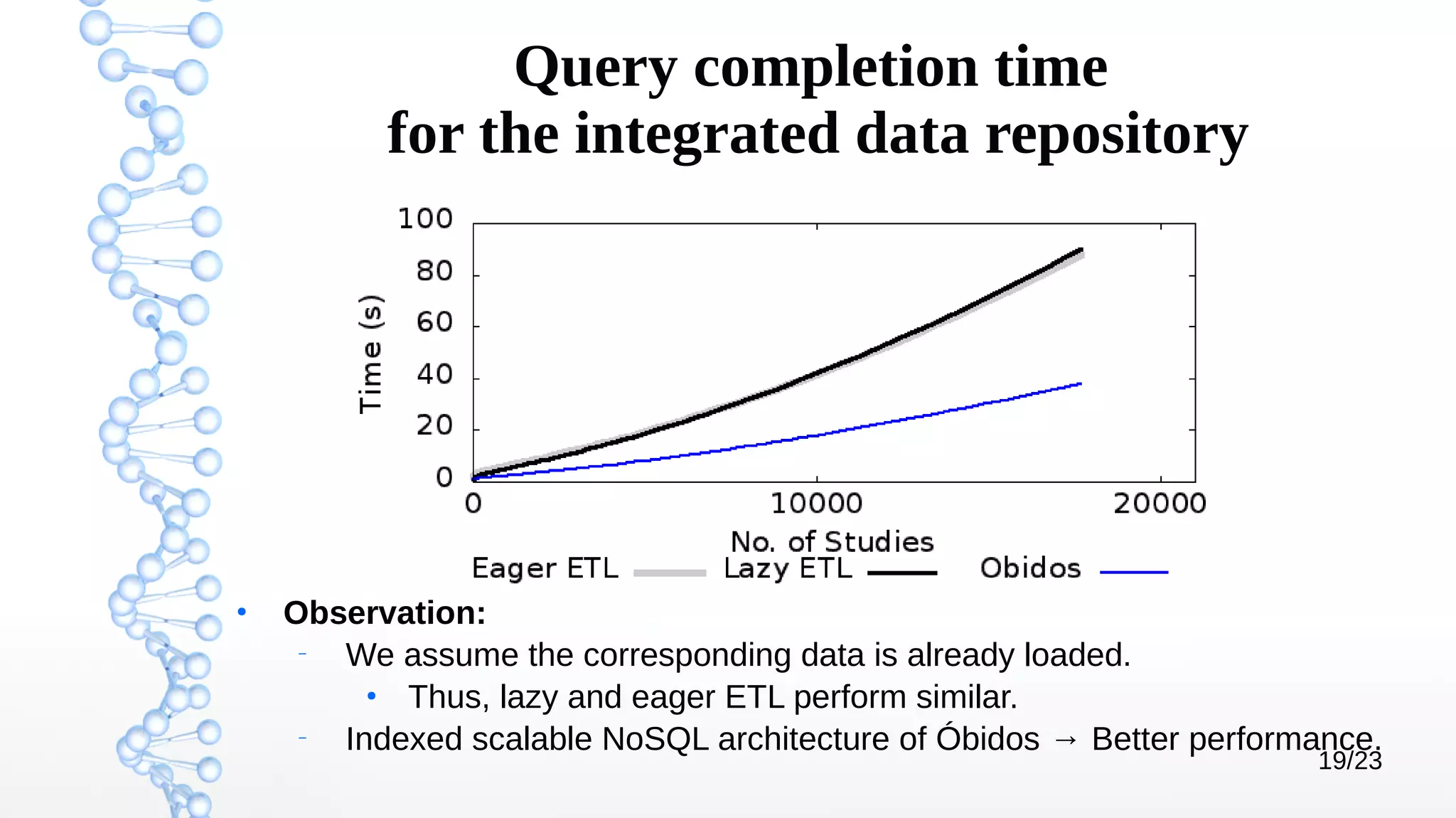
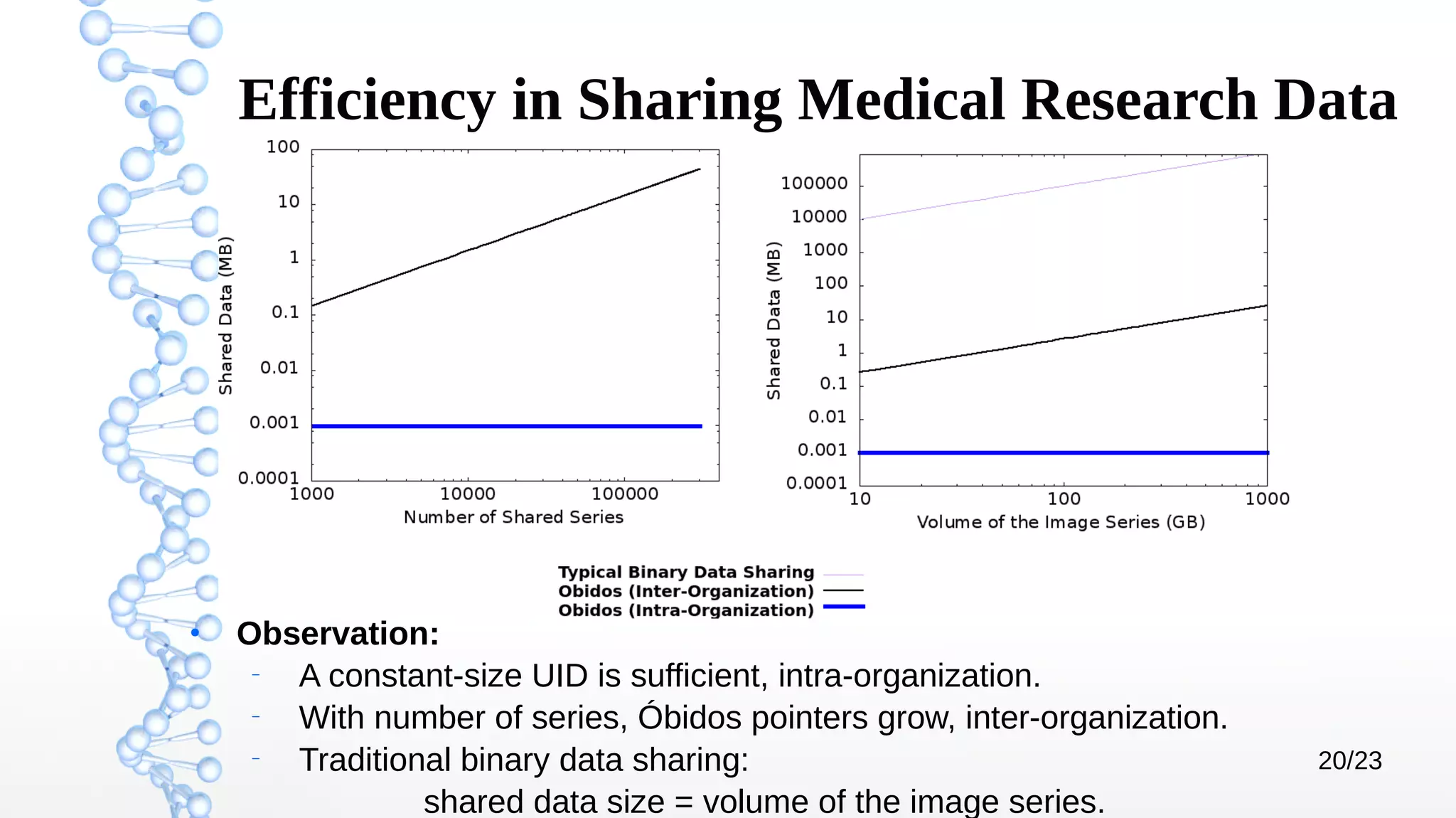




The document presents Óbidos, a system designed for on-demand service-based big data integration specifically optimized for medical research collaboration. It addresses various challenges in integrating diverse data types and sources, aiming to enhance efficiency in data access and sharing while avoiding data duplication. The evaluation indicates that Óbidos provides fast, efficient data analysis and effective sharing mechanisms compared to traditional binary data sharing methods.









































![[IJET-V1I3P10] Authors : Kalaignanam.K, Aishwarya.M, Vasantharaj.K, Kumaresan...](https://cdn.slidesharecdn.com/ss_thumbnails/ijet-v1i3p10-150608055552-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)













































