Download as PDF, PPTX





























































![References
Teplitzky, S. (2017). Open Data, [Open] Access: Linking Data Sharing and Article Sharing in the Earth
Sciences. Journal of Librarianship and Scholarly Communication, 5(General Issue), eP2150.
https://doi.org/10.7710/2162-3309.2150
Lee DJ, Stvilia B (2017) Practices of research data curation in institutional repositories: A qualitative view from repository staff. PLoS ONE 12(3):
e0173987. https://doi.org/10.1371/journal.pone.0173987
Drachen, T.M. et al. , (2016). Sharing data increases citations . LIBER Quarterly . 26 ( 2 ) , pp . 67–82 . DOI: http://doi.org/10.18352/lq.10149
Open Access and the Future of Scholarly Communication: Policy and Infrastructure
By Kevin L. Smith, Katherine A. Dickson](https://image.slidesharecdn.com/2018-05-09-managing-sharing-and-curating-your-research-data-in-a-digital-environment-180511110431/85/Managing-Sharing-and-Curating-Your-Research-Data-in-a-Digital-Environment-88-320.jpg)



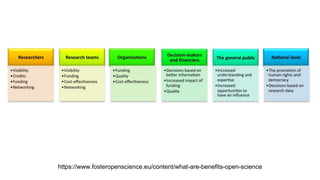
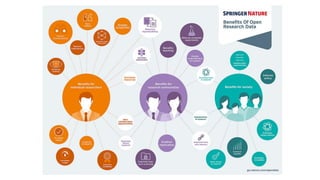
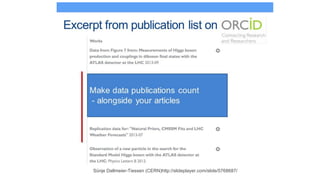
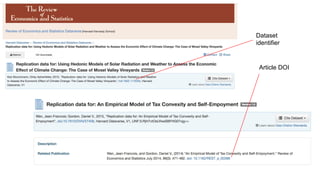
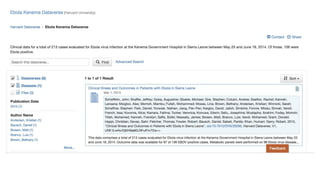
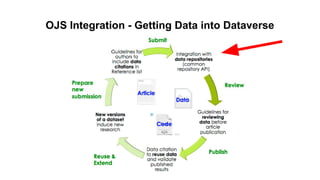
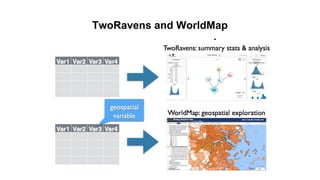
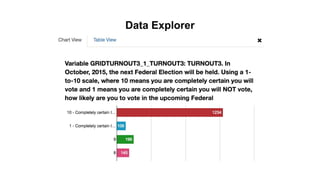
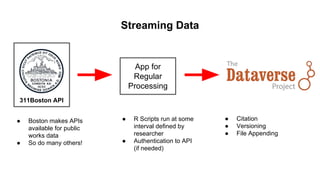
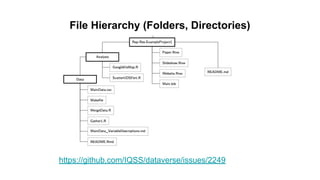
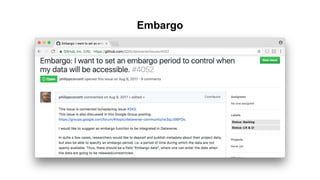
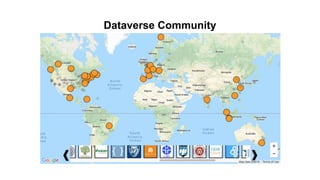
This document discusses research data management and curation. It describes how data sharing has increased as open science mandates have promoted data availability. Research data is now often shared alongside research articles through bi-directional linking. Self-curation repositories are being developed to help researchers publish and share their data. The benefits of open access include increased visibility, new discoveries through wider collaboration, and compliance with funder mandates. Key requirements for open data include availability, access, redistribution and reuse. Dataverse is presented as a solution for research data management that facilitates data sharing, preservation, citation, exploration and analysis. It issues persistent identifiers and supports various data formats and protocols. Challenges of data management include meaningful aggregation, privacy concerns



































































