Download to read offline























![Common Auxiliary Numbers Useful for
Managing Vocabulary Service for NNfD
• e.g. Special Subject Thesauri [025.4.06] and Controlled Vocabularies [025.43]
Case studies [001.87] Photographic Images [084.12]
• All resources, whatever their form, can be connected by their subject content and,
whatever the data subject, content can be described by form](https://image.slidesharecdn.com/barbalet-managing-big-data-in-the-social-sciencespaper-180613150003/75/Managing-Big-Data-in-the-social-sciences-the-contribution-of-an-analytico-synthetic-classification-scheme-Suzzane-Barbalet-29-2048.jpg)


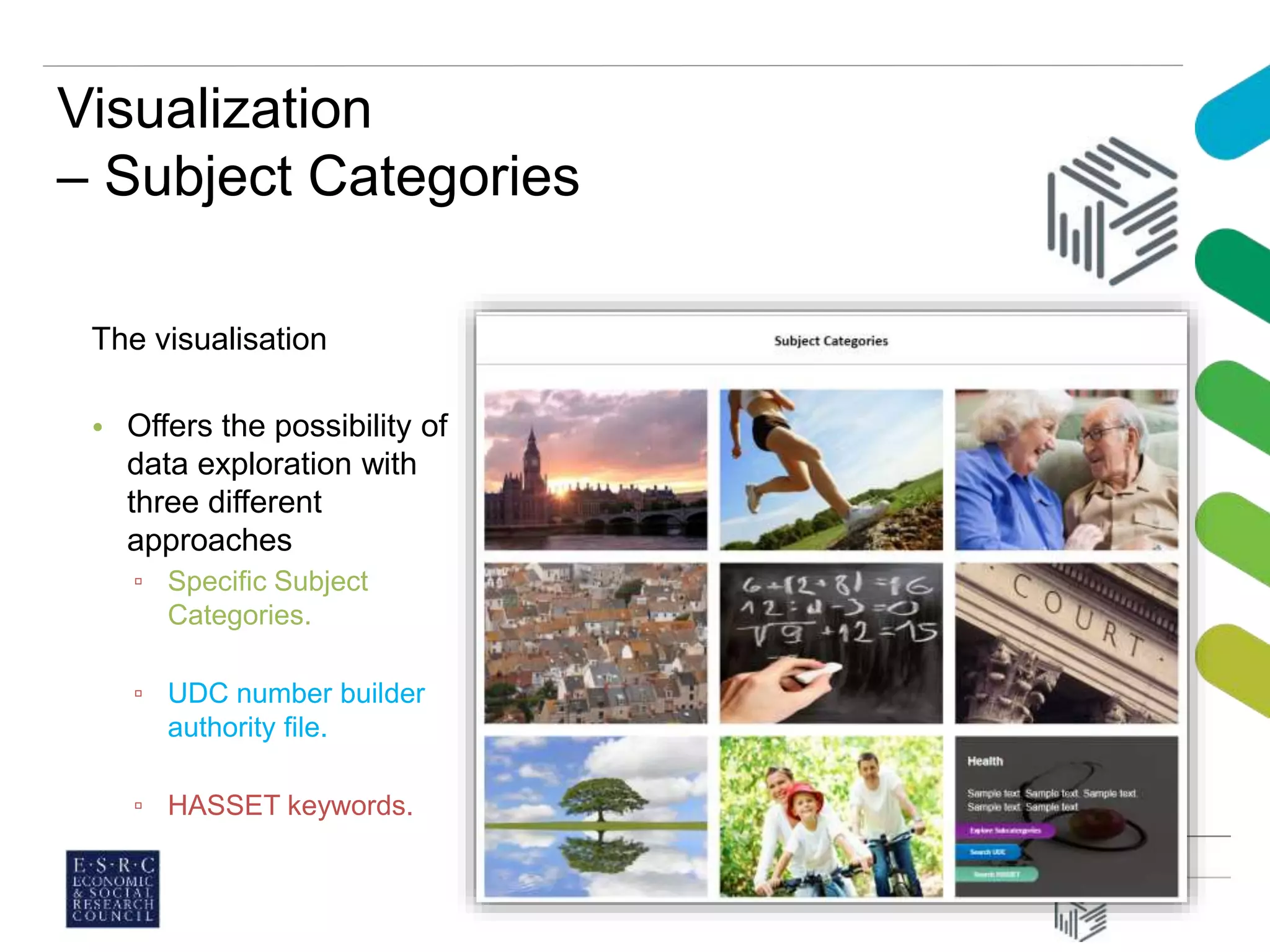
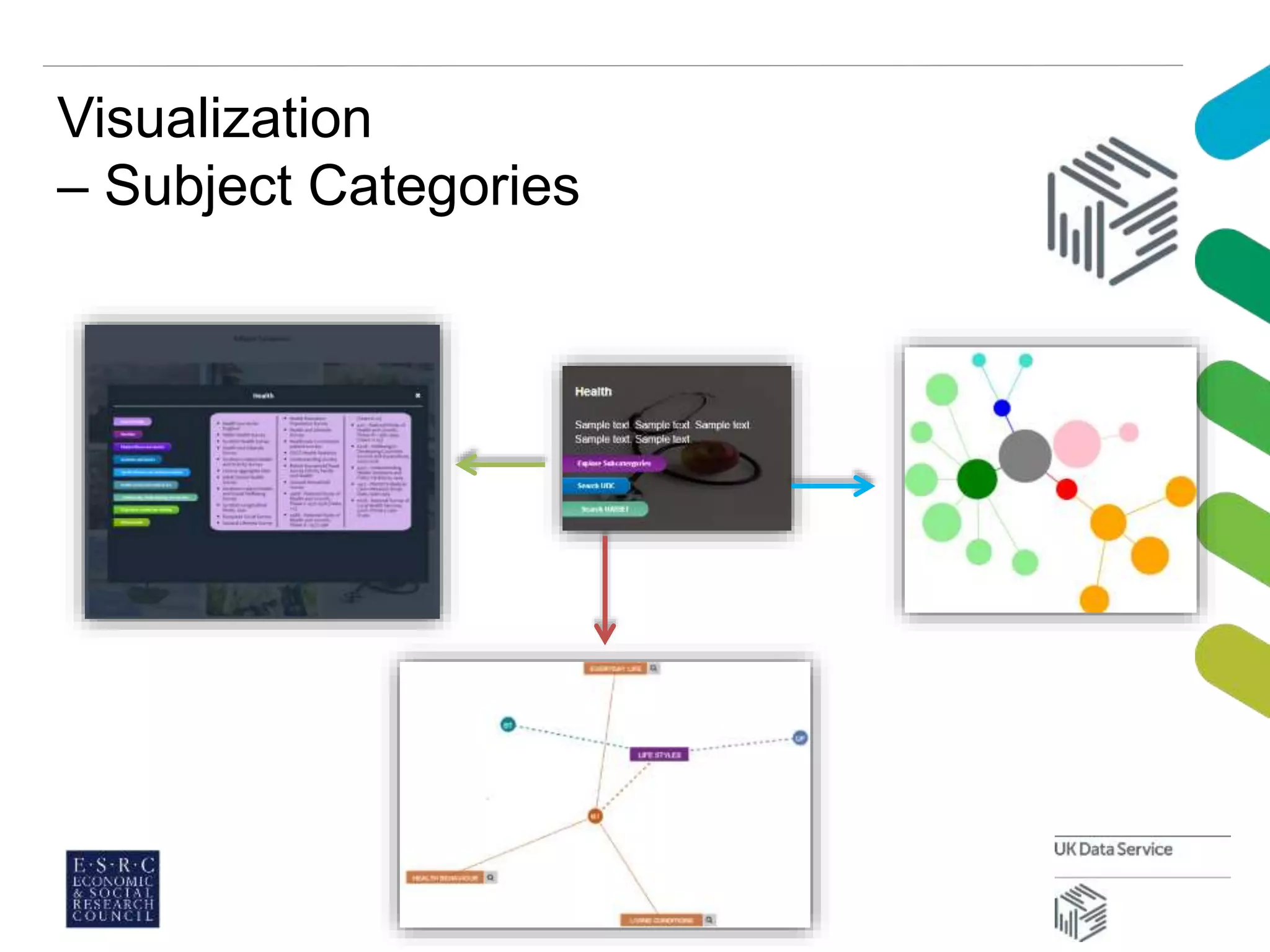





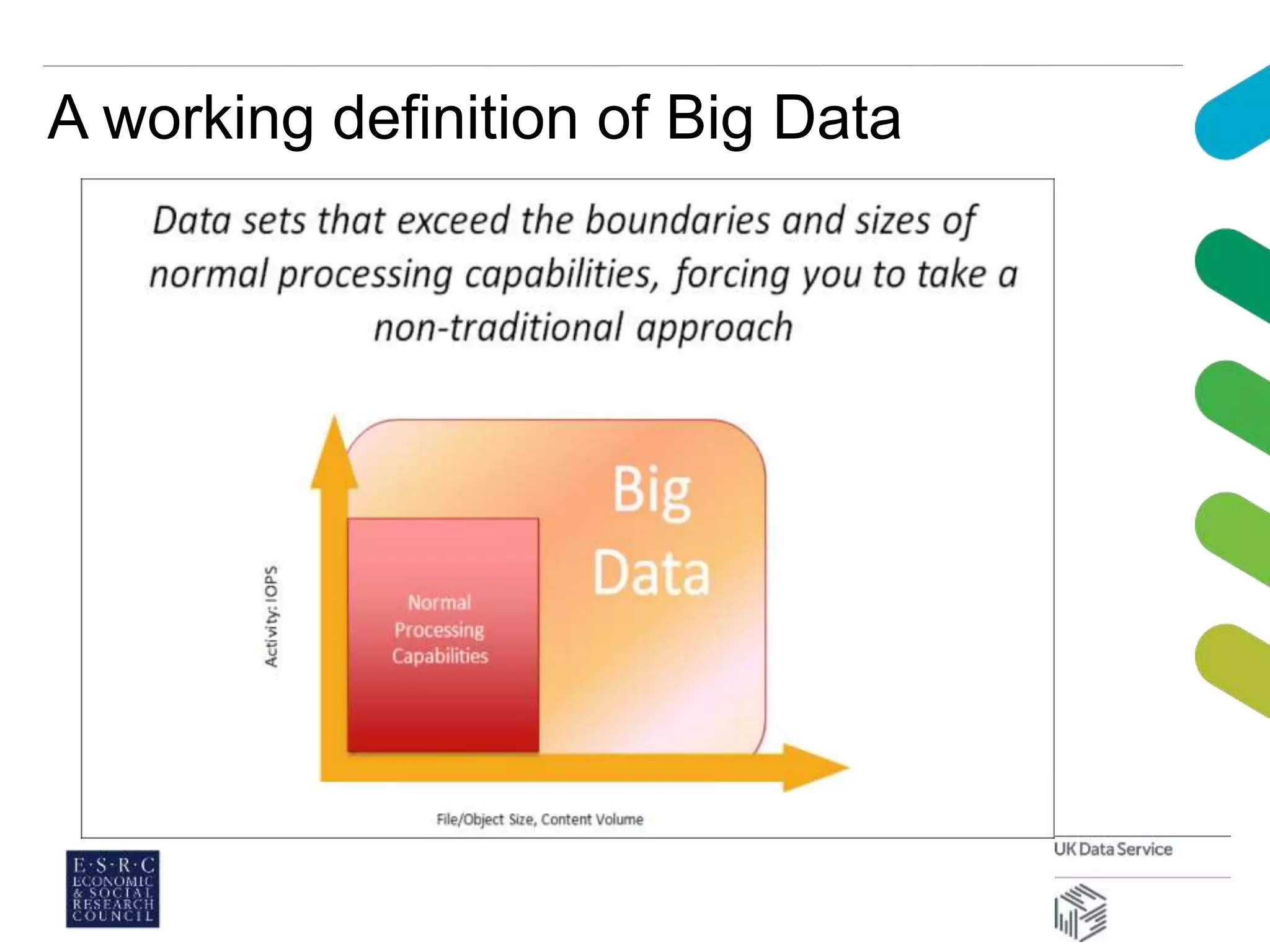
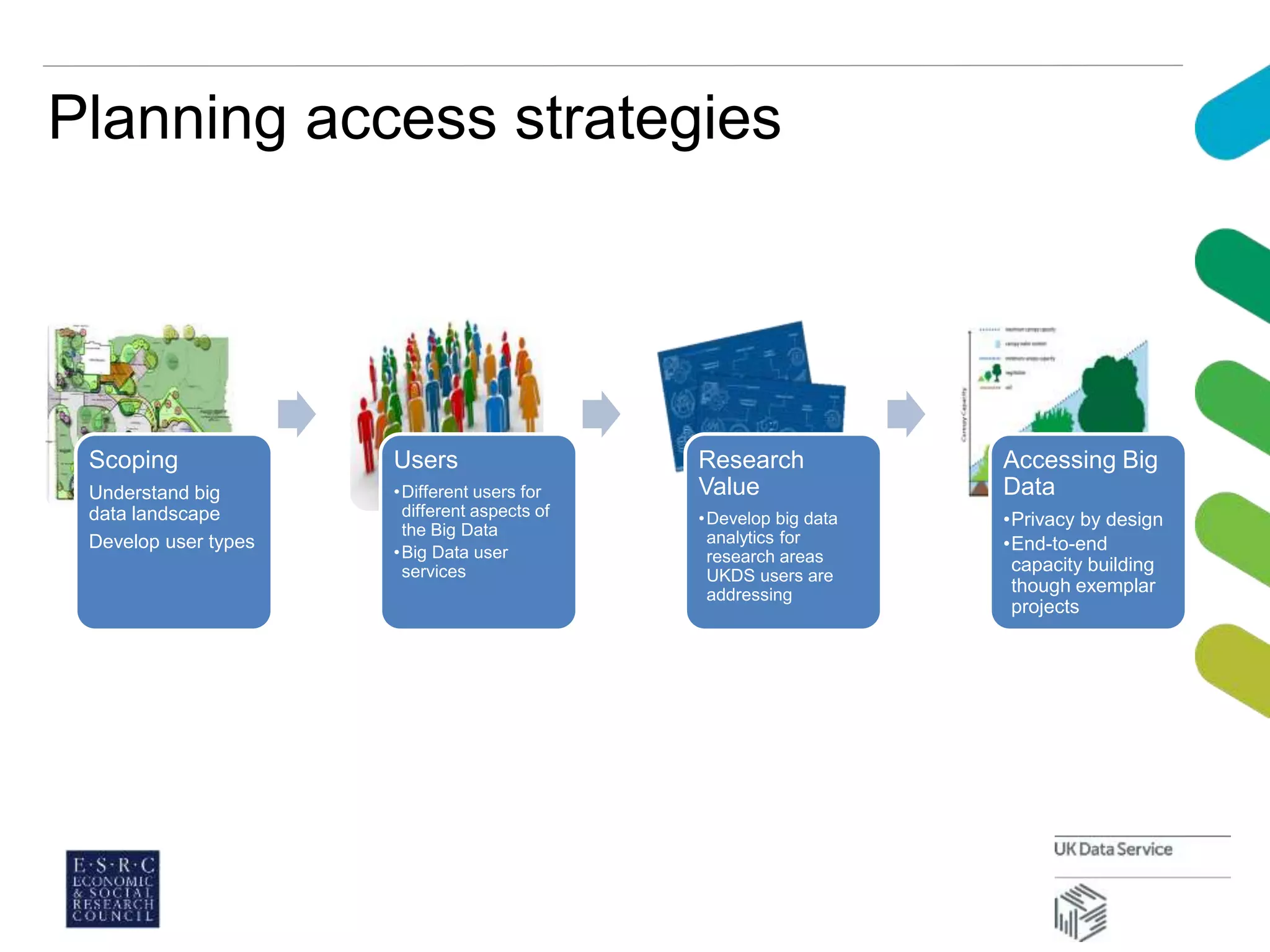
This document discusses managing large datasets in the social sciences. It describes how the UK Data Service curates and provides access to large survey and census data. It explores how classification schemes could help organize and provide subject access to these growing datasets. A pilot project classified datasets using the Universal Decimal Classification scheme and found it efficient and helped visualize subject categories. Overall, carefully chosen knowledge organization tools can help provide multidimensional subject access needed to analyze complex datasets.



















































![Ship[w]right[e]s? : the challenges of cataloguing reports from scientific exp...](https://cdn.slidesharecdn.com/ss_thumbnails/shipwritesthechallengesofcataloguingreportsfromscientificexpeditionsbencornish-230918140216-c31f7a96-thumbnail.jpg?width=640&height=640&fit=bounds)


















![[DSC Europe 25] Kaja Kandare - LLM as a judge.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/arxyccaxsdsd1ba99wjw-7-251212104007-2b4e3f64-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Dunja Adzic Jovanovic - AI and Cybersecurity: Defending Data ...](https://cdn.slidesharecdn.com/ss_thumbnails/o1zylpbhrtwnixxq2xj8-7-251211083048-185086f6-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Tatevik Maytesyan - How to actually use AI in marketing: gett...](https://cdn.slidesharecdn.com/ss_thumbnails/tjo626lsqdgfntbgl2mw-4-251216103155-e36cd239-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DSC Europe 25] Hans Kleinsman - The Compliance Gearbox: How Tax Tech Mediate...](https://cdn.slidesharecdn.com/ss_thumbnails/dxdytie1toel0hr90bjs-2-251212103250-174fdbe7-thumbnail.jpg?width=640&height=640&fit=bounds)
