Downloaded 38 times












![Application model
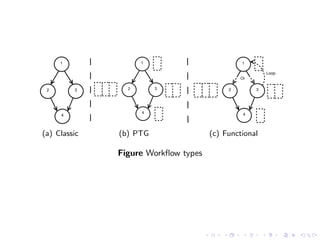
Non-deterministic (functional) workflows
An application is a graph G = (V, E), where
V = {vi |i = 1, . . . , |V |} is a set of vertices
E = {ei,j |(i, j) ∈ {1, . . . , |V |} × {1, . . . , |V |}} is a set of edges
representing precedence and flow constraints
Vertices
a computational task [parallel, moldable]
an OR-split [transitions described by random variables]
an OR-join](https://image.slidesharecdn.com/wf-121203101922-phpapp02/85/Workflow-Allocations-and-Scheduling-on-IaaS-Platforms-from-Theory-to-Practice-14-320.jpg)
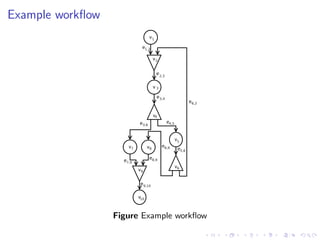



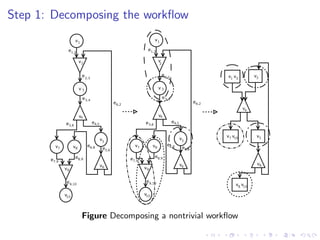






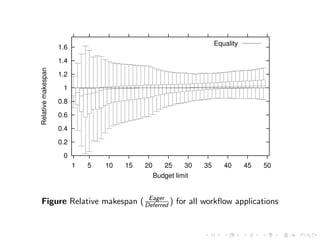
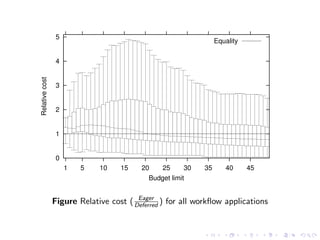


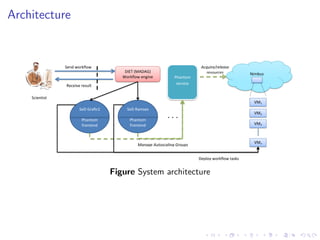




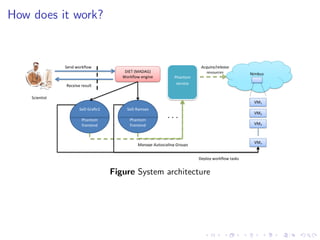




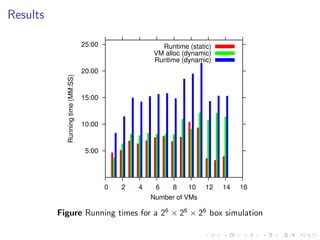
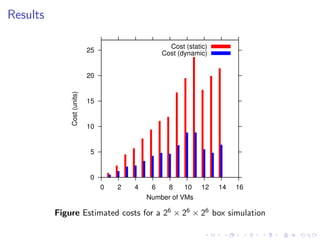








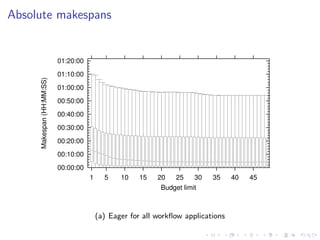
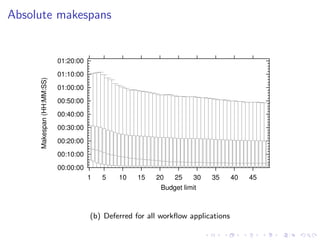
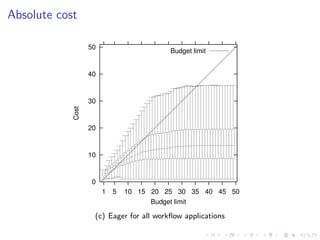
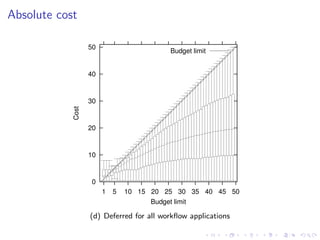

This document summarizes a joint workshop on workflow allocations and scheduling on Infrastructure as a Service (IaaS) platforms. It discusses using on-demand resources to more efficiently allocate workflows compared to static allocations. It proposes two algorithms, Eager and Deferred, to determine allocations within a given budget limit. Simulations using synthetic workflows showed Deferred guarantees budget constraints while Eager is faster. For small applications and budgets, Deferred is preferred. For larger applications and budgets approaching task parallelism saturation, Eager performs better. The document also discusses a prototype system using Nimbus, Phantom and DIET to deploy workflows on IaaS resources.





























































