Downloaded 90 times


![Today’s Lecture
• Use probability axioms to model word prediction
• N-grams
• Smoothing
• Reading:
– Sections 4.1, 4.2, 4.3, 4.5.1 in Speech and Language
Processing [Jurafsky & Martin]](https://image.slidesharecdn.com/ngrams-smoothing-120312163148-phpapp02/85/Ngrams-smoothing-3-320.jpg)








![Terminology
• Sentence: unit of written language
• Utterance: unit of spoken language
• Word Form: the inflected form as it actually
appears in the corpus
• Lemma: an abstract form, shared by word forms
having the same stem, part of speech, word
sense – stands for the class of words with same
stem
– chairs [chair] , reflected [reflect], ate [eat],
• Types: number of distinct words in a corpus
(vocabulary size)
• Tokens: total number of words](https://image.slidesharecdn.com/ngrams-smoothing-120312163148-phpapp02/85/Ngrams-smoothing-12-320.jpg)







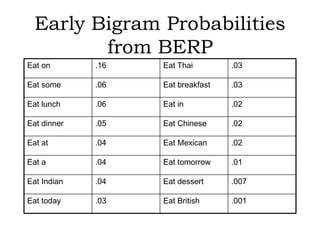
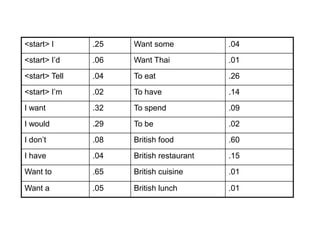

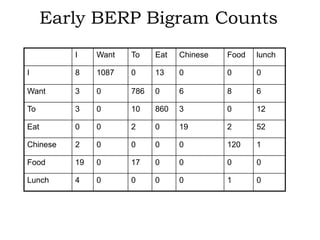











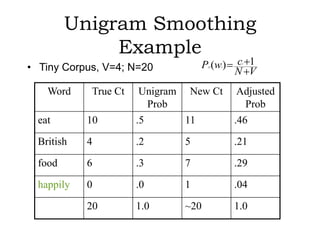





N-gram models are statistical language models that can be used for word prediction. They calculate the probability of a word based on the previous N-1 words. Higher N-gram models require more data but capture context better. N-gram probabilities are estimated by counting word sequences in a large training corpus and calculating conditional probabilities. These probabilities provide information about syntactic patterns and semantic relationships in language.




































































































