Downloaded 43 times















![Regular Expressions
Simplest regex: [^s]+
More advanced regex:
w+|[!"#$%&'*+,./:;<=>?@^`~…() {}[|]⟨⟩ ‒–—
«»“”‘’-]―
Even more advanced regex:
[+-]?[0-9](?:[0-9,.]*[0-9])?
|[w@](?:[w'’`@-][w']|[w'][w@'’`-])*[w']?
|["#$%&*+,/:;<=>@^`~…() {}[|] «»“”‘’']⟨⟩ ‒–—―
|[.!?]+
|-+](https://image.slidesharecdn.com/nlp-crash-150814192821-lva1-app6891/85/Crash-course-in-Natural-Language-Processing-16-320.jpg)
![Post-processing
* concatenate abbreviations and decimals
* split contractions with regexes
2-character:
i['‘’`]m|(?:s?he|it)['‘’`]s|(?:i|you|s?he|we|they)
['‘’`]d$
3-character:
(?:i|you|s?he|we|they)['‘’`](?:ll|[vr]e)|n['‘’`]t$](https://image.slidesharecdn.com/nlp-crash-150814192821-lva1-app6891/85/Crash-course-in-Natural-Language-Processing-17-320.jpg)












![ML-based Parsing
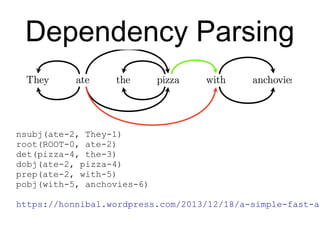
The parser starts with an empty stack, and a buffer index at 0, with no
dependencies recorded. It chooses one of the valid actions, and applies it to
the state. It continues choosing actions and applying them until the stack is
empty and the buffer index is at the end of the input.
SHIFT = 0; RIGHT = 1; LEFT = 2
MOVES = [SHIFT, RIGHT, LEFT]
def parse(words, tags):
n = len(words)
deps = init_deps(n)
idx = 1
stack = [0]
while stack or idx < n:
features = extract_features(words, tags, idx, n, stack, deps)
scores = score(features)
valid_moves = get_valid_moves(i, n, len(stack))
next_move = max(valid_moves, key=lambda move: scores[move])
idx = transition(next_move, idx, stack, parse)
return tags, parse](https://image.slidesharecdn.com/nlp-crash-150814192821-lva1-app6891/85/Crash-course-in-Natural-Language-Processing-35-320.jpg)
![Averaged Perceptron
def train(model, number_iter, examples):
for i in range(number_iter):
for features, true_tag in examples:
guess = model.predict(features)
if guess != true_tag:
for f in features:
model.weights[f][true_tag] += 1
model.weights[f][guess] -= 1
random.shuffle(examples)](https://image.slidesharecdn.com/nlp-crash-150814192821-lva1-app6891/85/Crash-course-in-Natural-Language-Processing-36-320.jpg)











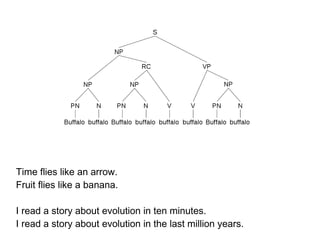
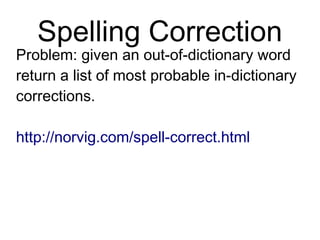
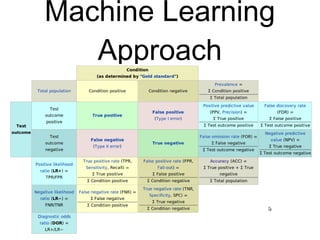
This document provides an overview of natural language processing (NLP) including the linguistic basis of NLP, common NLP problems and approaches, sources of NLP data, and steps to develop an NLP system. It discusses tokenization, part-of-speech tagging, parsing, machine learning approaches like naive Bayes classification and dependency parsing, measuring word similarity, and distributional semantics. The document also provides advice on going from research to production systems and notes areas not covered like machine translation and deep learning methods.






















































































