Download as PDF, PPTX














![Experiment
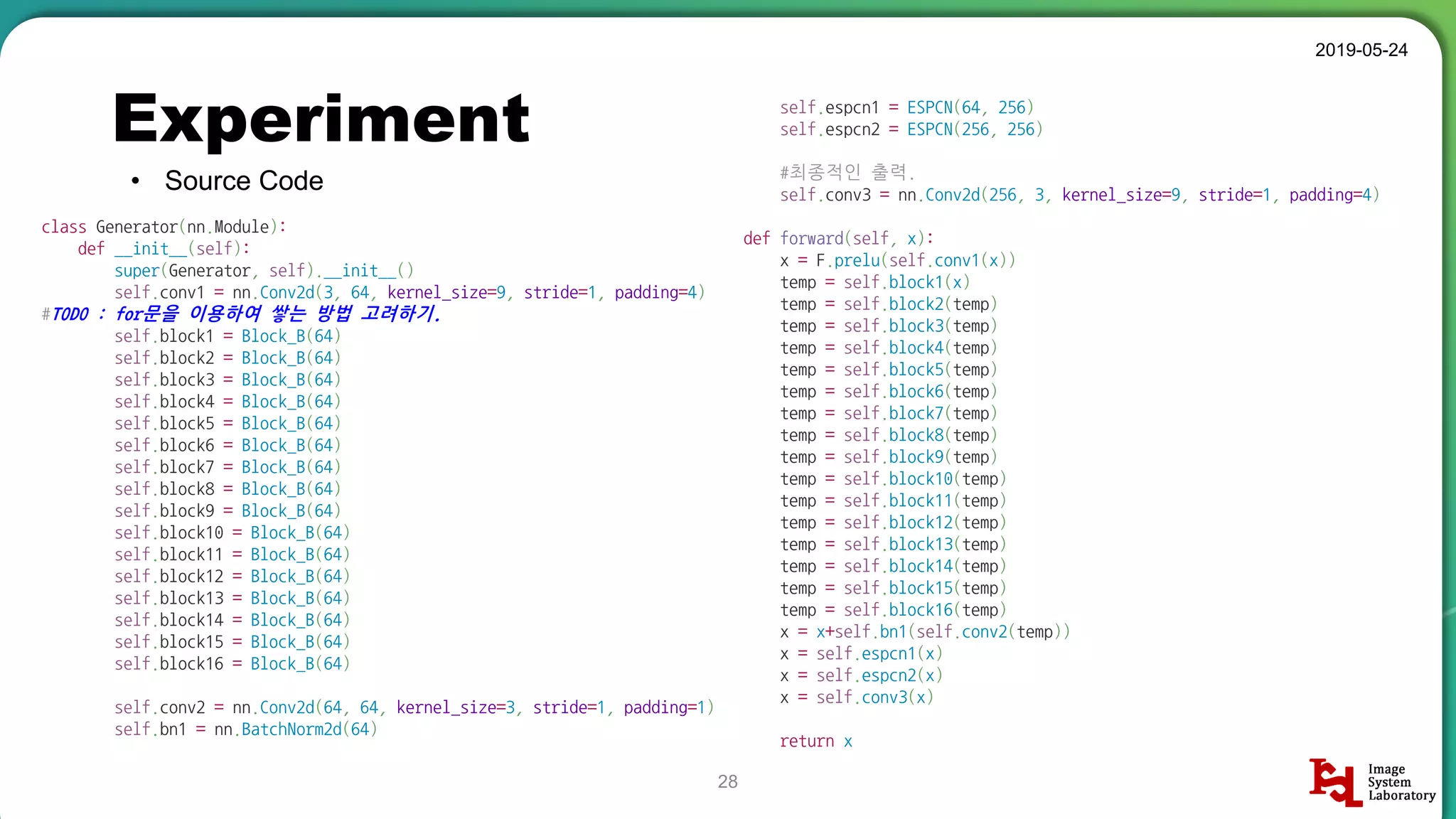
• Source Code
2019-05-24
30
class GeneratorLoss(nn.Module):
def __init__(self):
super(GeneratorLoss, self).__init__()
vgg = vgg16(pretrained=True)
loss_network = nn.Sequential(*list(vgg.features)[:31]).eval()
for param in loss_network.parameters():
param.requires_grad = False
self.loss_network = loss_network
self.mse_loss = nn.MSELoss()
def forward(self, out_labels, out_images, target_images):
# Adversarial Loss
adversarial_loss = torch.mean(1 - out_labels)
# Perception Loss
perception_loss = self.mse_loss(self.loss_network(out_images), self.loss_network(target_images))
# Image Loss
image_loss = self.mse_loss(out_images, target_images)
loss_network = nn.Sequential(*list(vgg.features)[:31]).eval()
파이썬 Asterisk(*) 의 역할
1. Positional arg
2. Keword arg
3. Unpacking
# (0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (1): ReLU(inplace)
# (2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (3): ReLU(inplace)
# (4): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), dilation=(1, 1), ceil_mode=False)
# (5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# ... # ...
# (30): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), dilation=(1, 1), ceil_mode=False) # )
Python Intermediate Seminar 예정](https://image.slidesharecdn.com/srgan-190910075433/75/Photo-realistic-Single-Image-Super-resolution-using-a-Generative-Adversarial-Network-SRGAN-30-2048.jpg)













The document discusses the methodology and results of using Generative Adversarial Networks (GANs) for photo-realistic single image super-resolution (SRGAN). It covers the architecture, perceptual loss functions, and experimental results using various datasets, demonstrating the effectiveness of adversarial loss in improving image quality. Additionally, it includes source code examples for the generator and discriminator components of the SRGAN framework.
Introduction to the seminar on SRGAN by Hansol Kang, focusing on photo-realistic single image super-resolution.
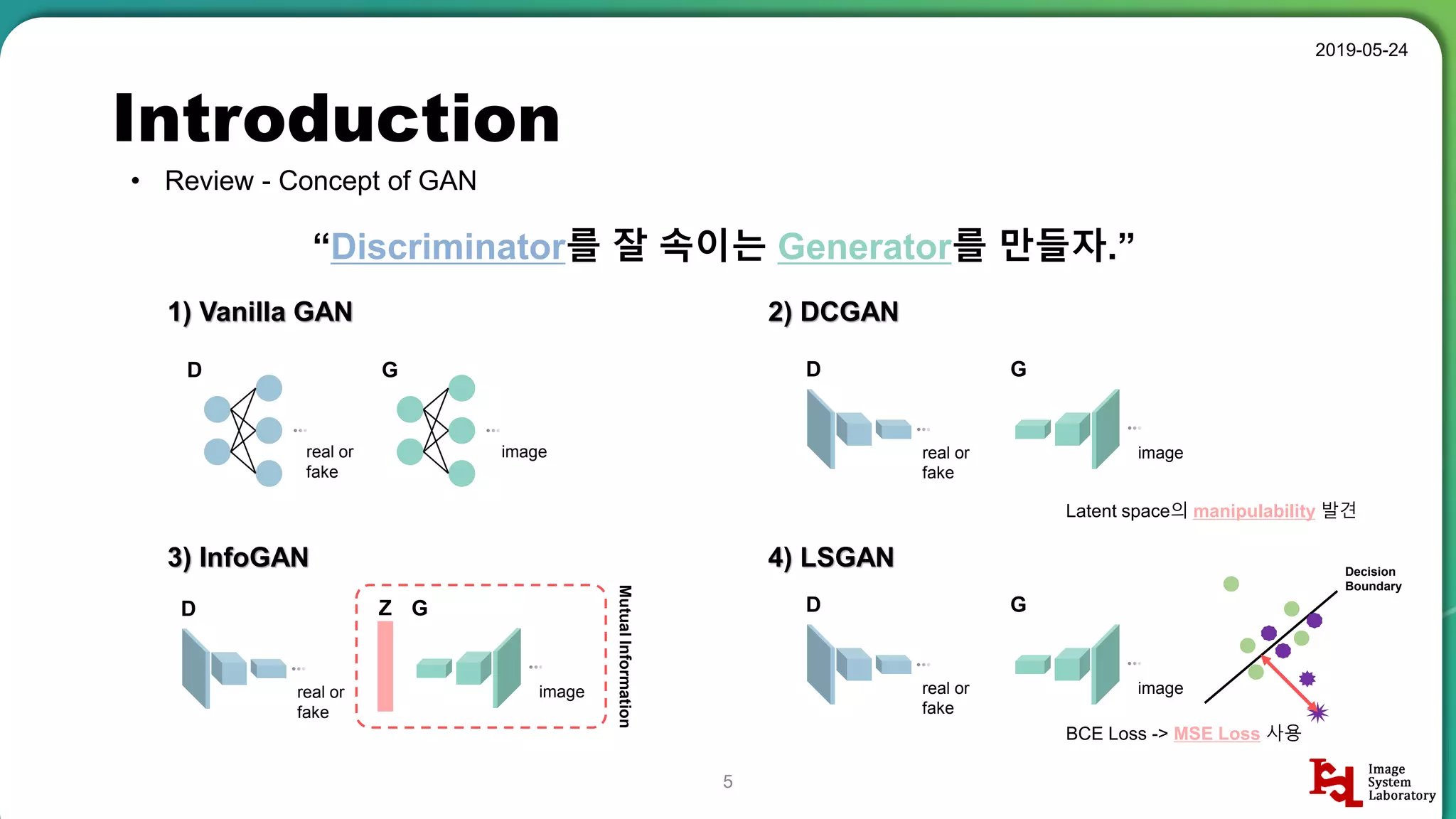
Detailed review of GAN concepts, including various types like Vanilla GAN, DCGAN, and their applications in style transfer, inpainting, and super-resolution.
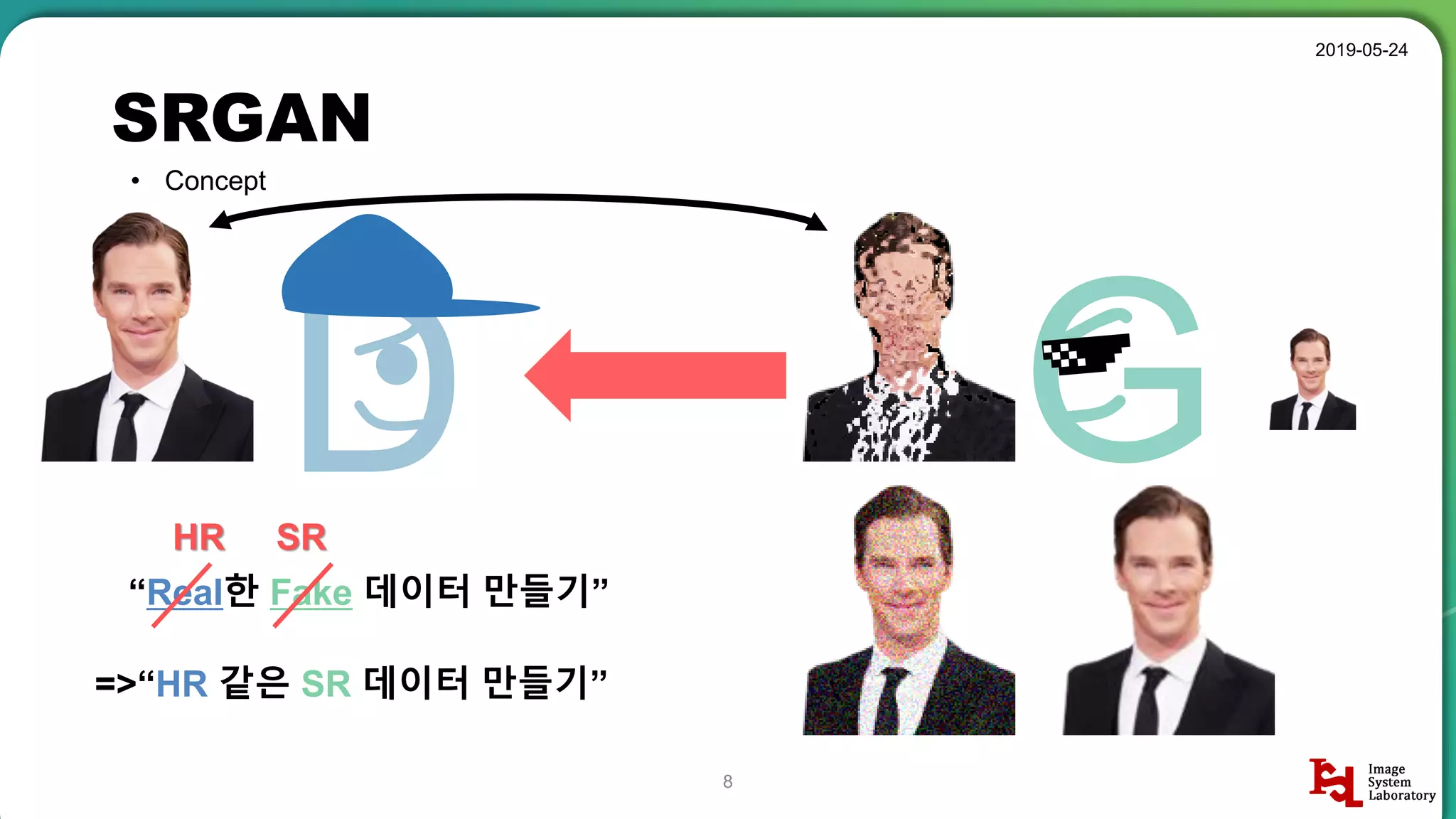
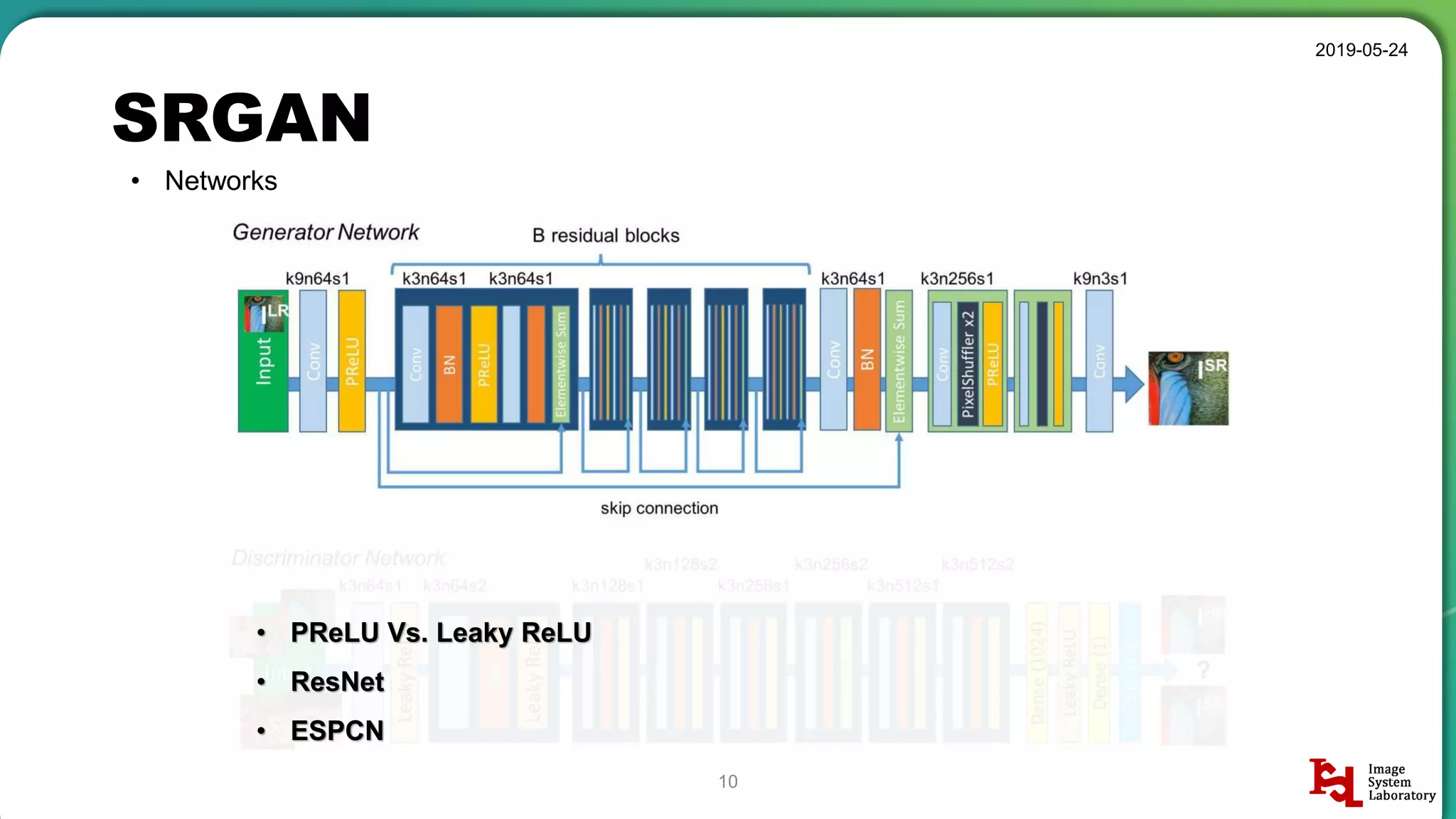
Overview of SRGAN, emphasizing its goal to create realistic super-resolution images.
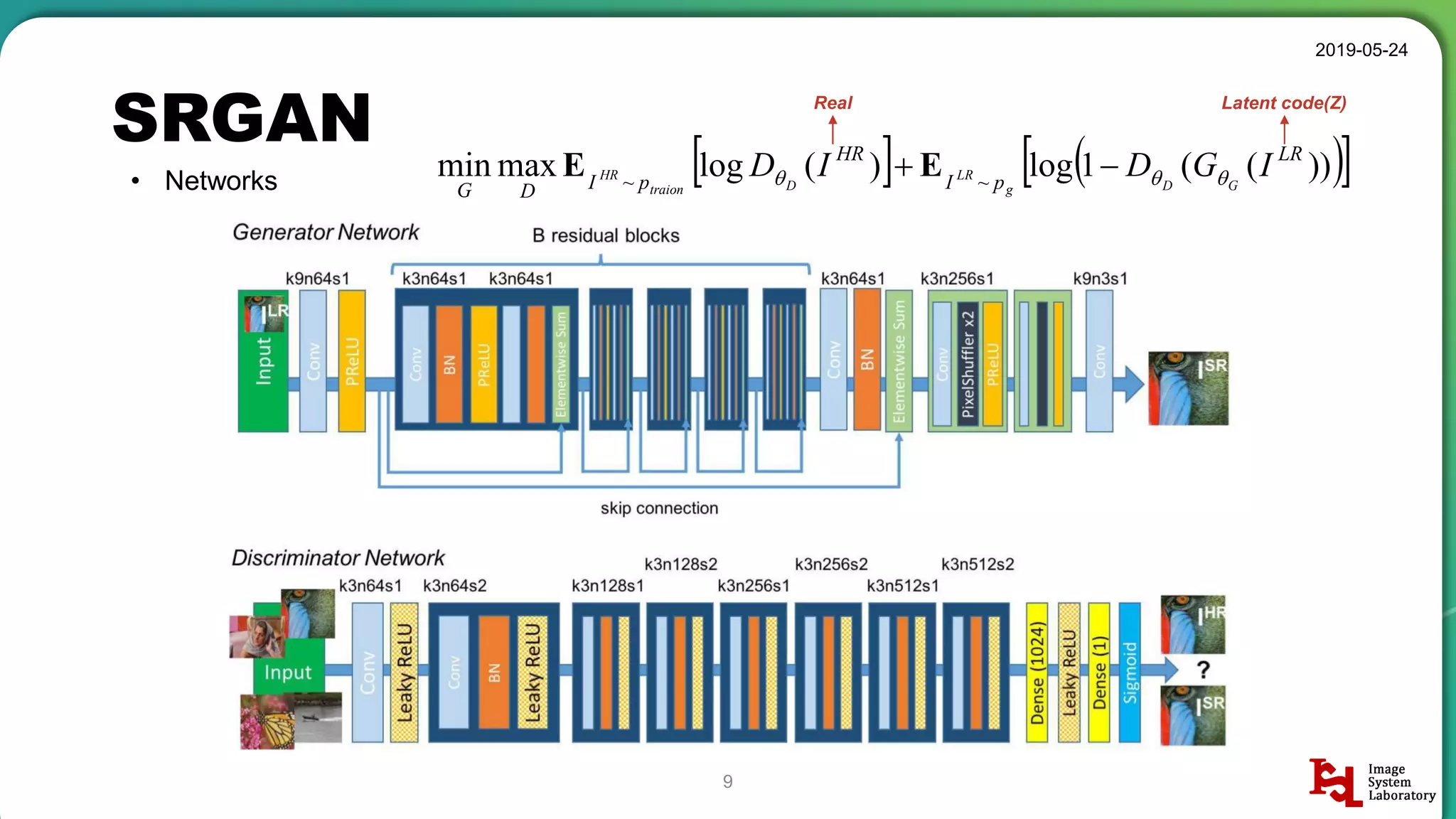
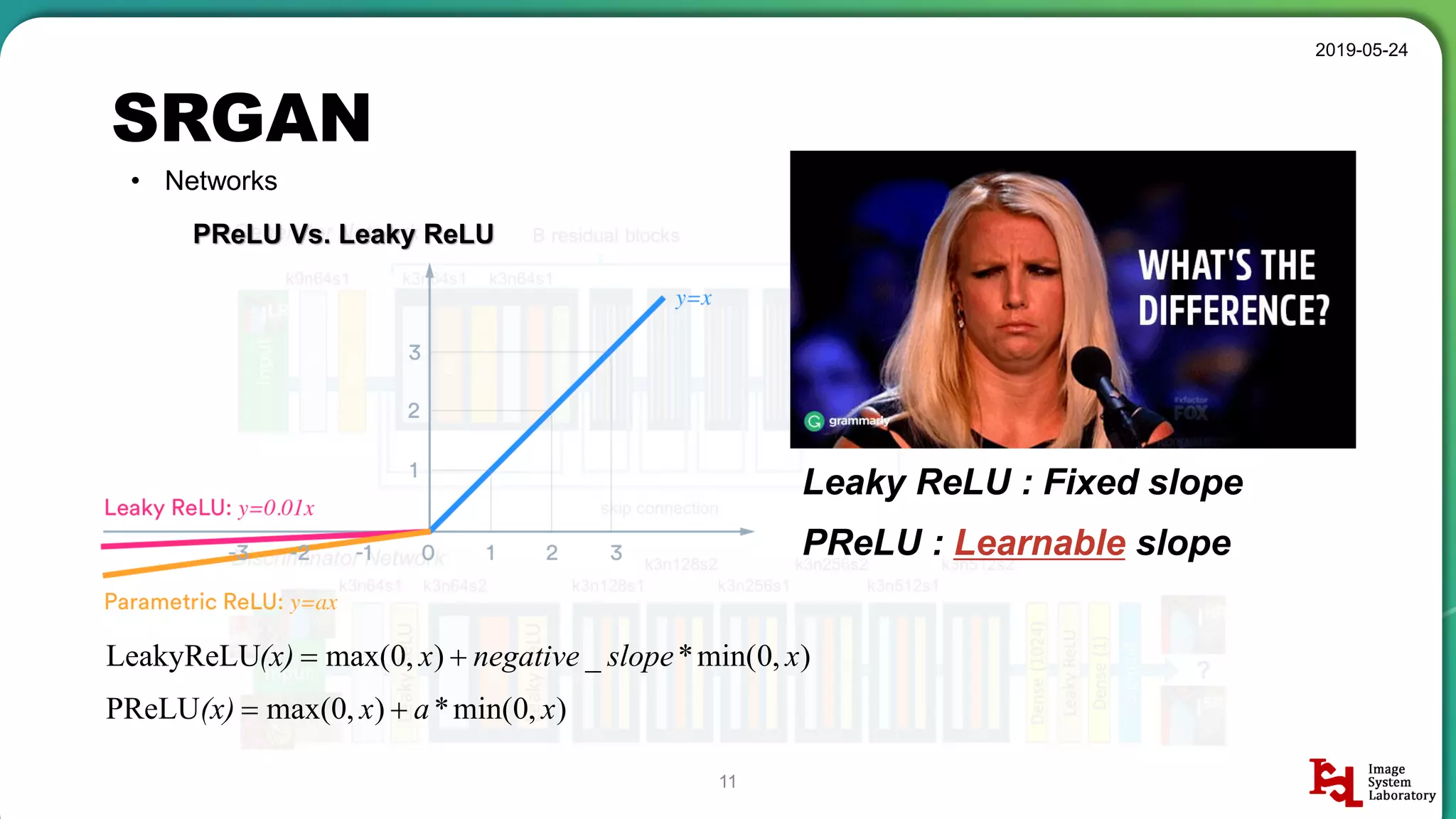
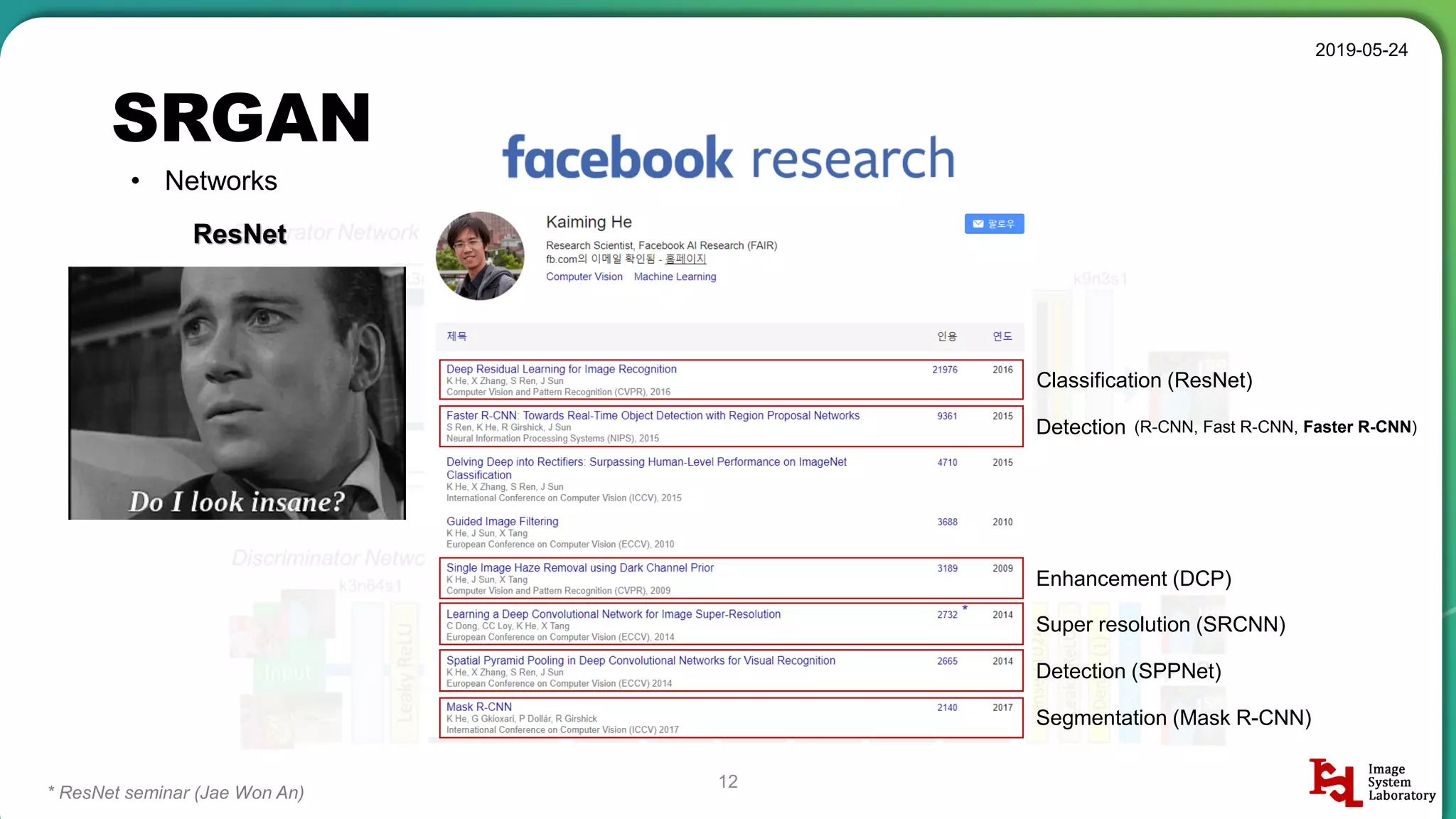
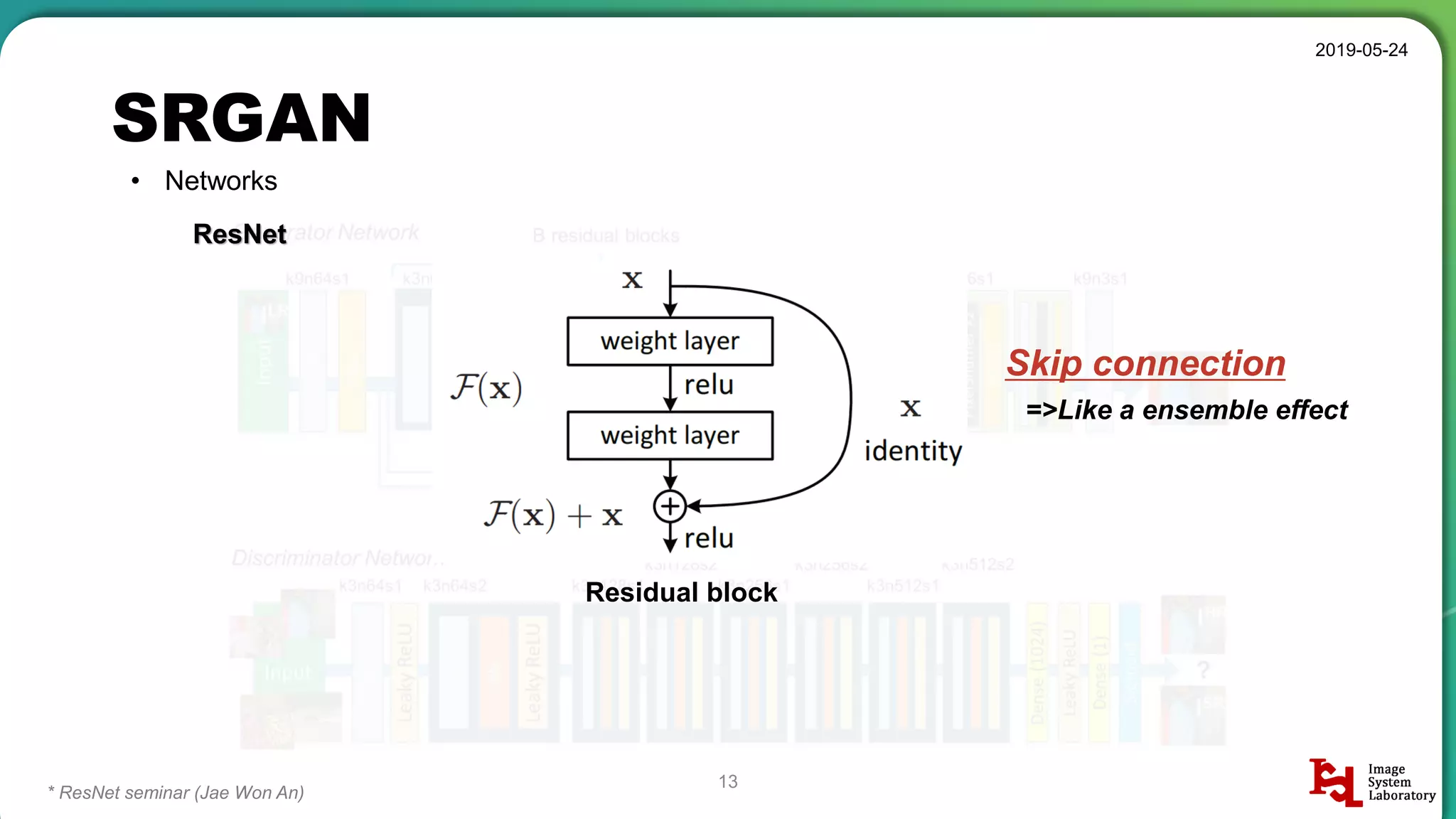
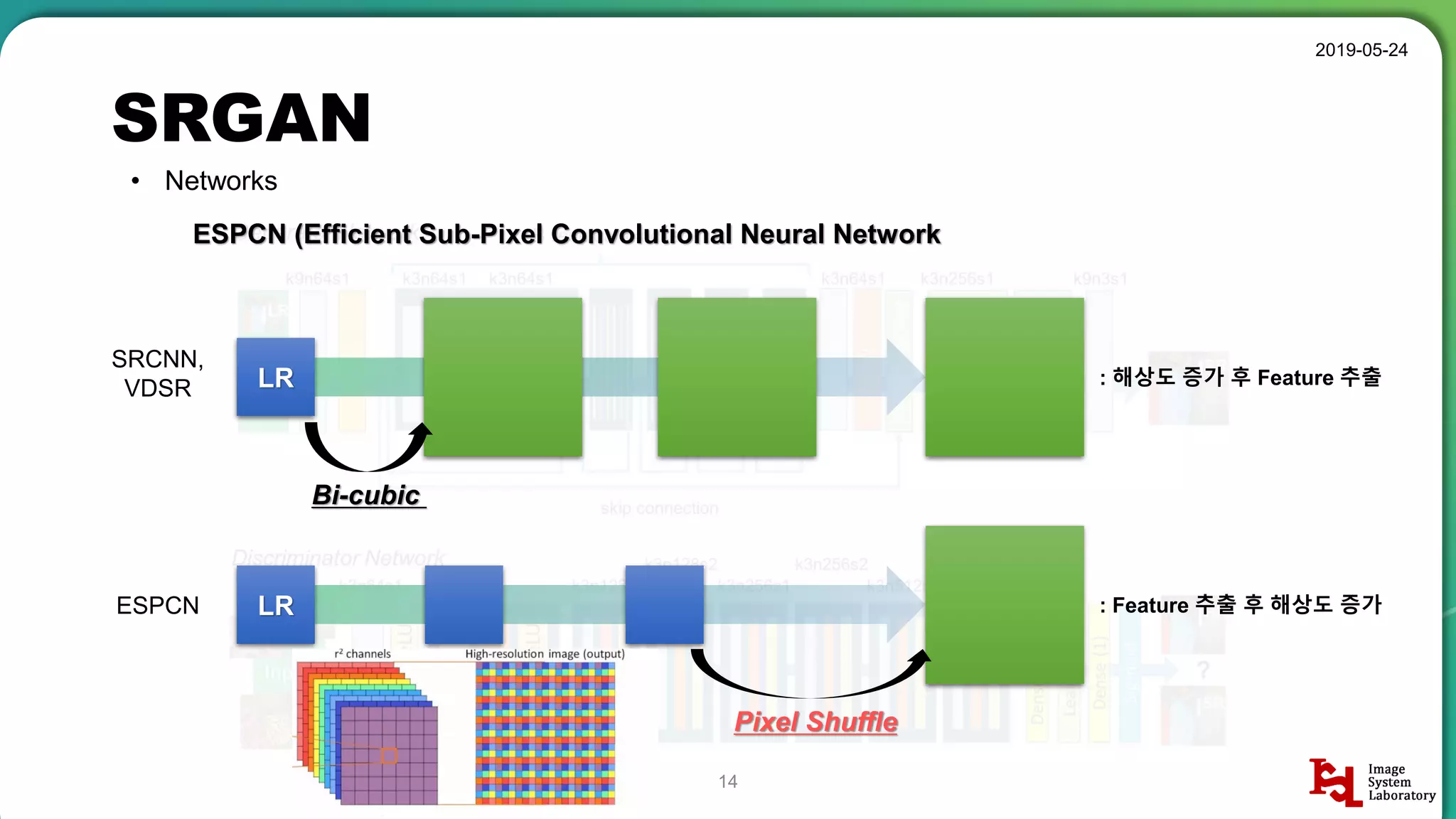
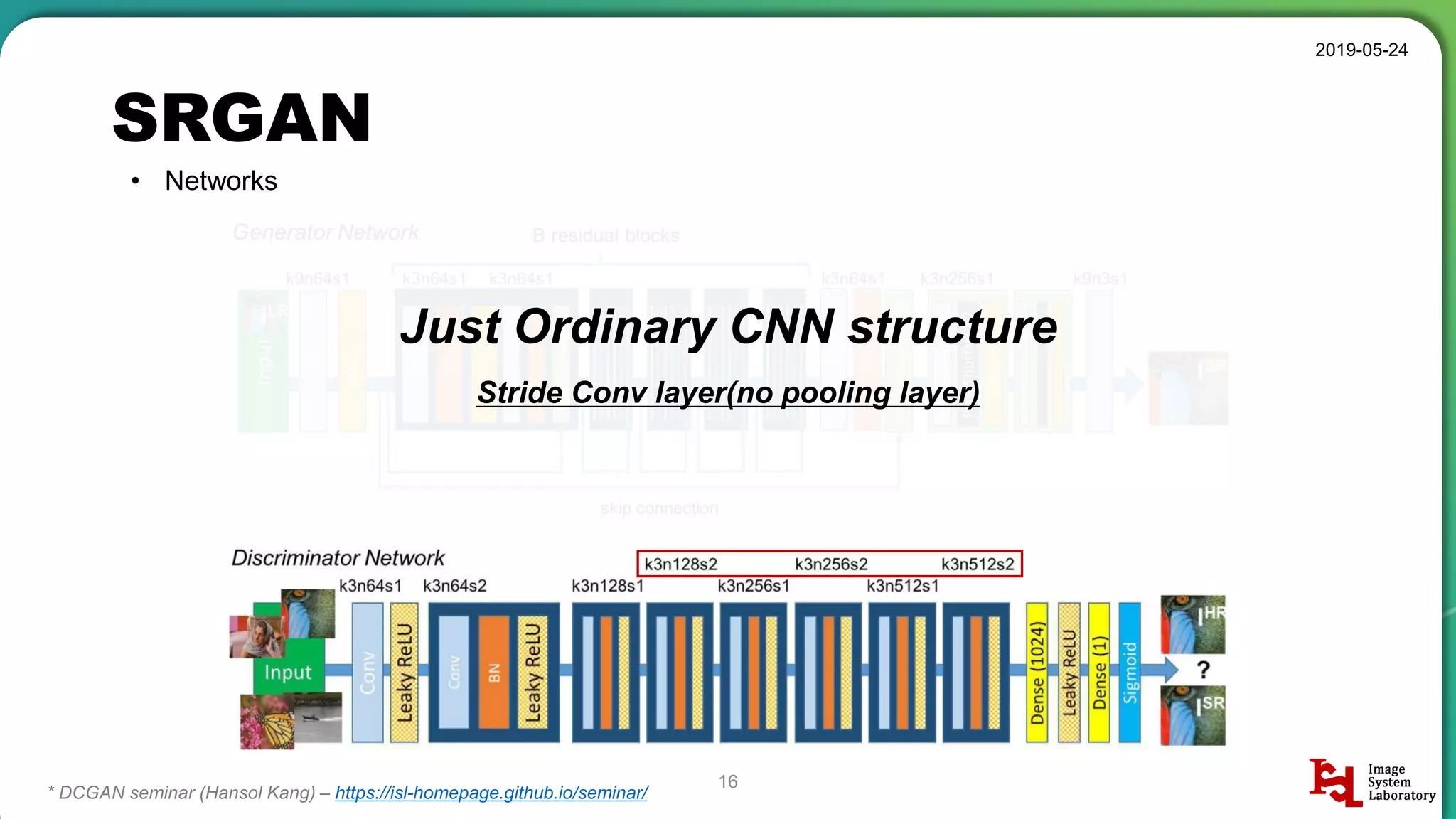
Discussion of different neural network structures used in SRGAN, including ResNet and ESPCN architectures.
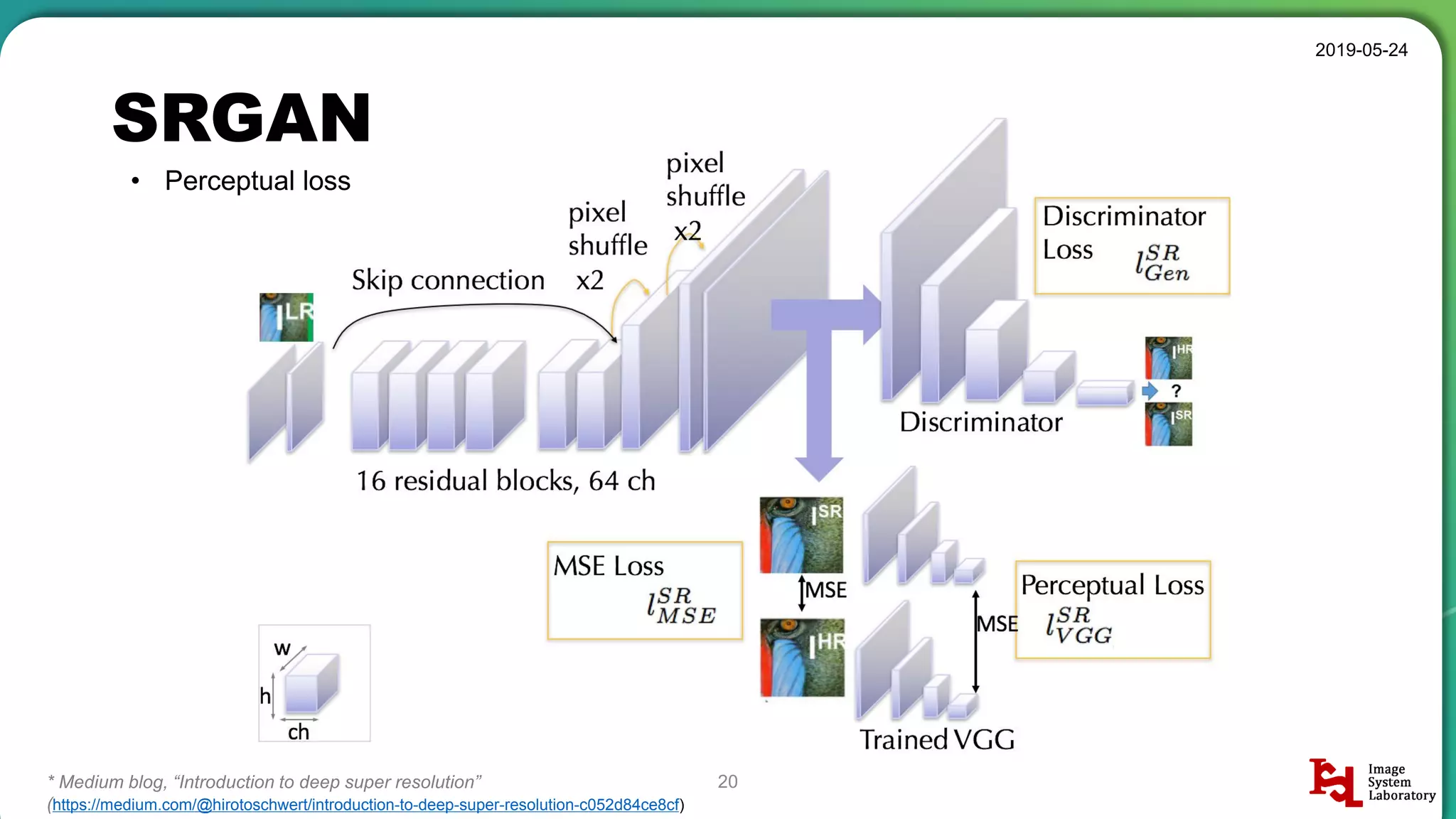
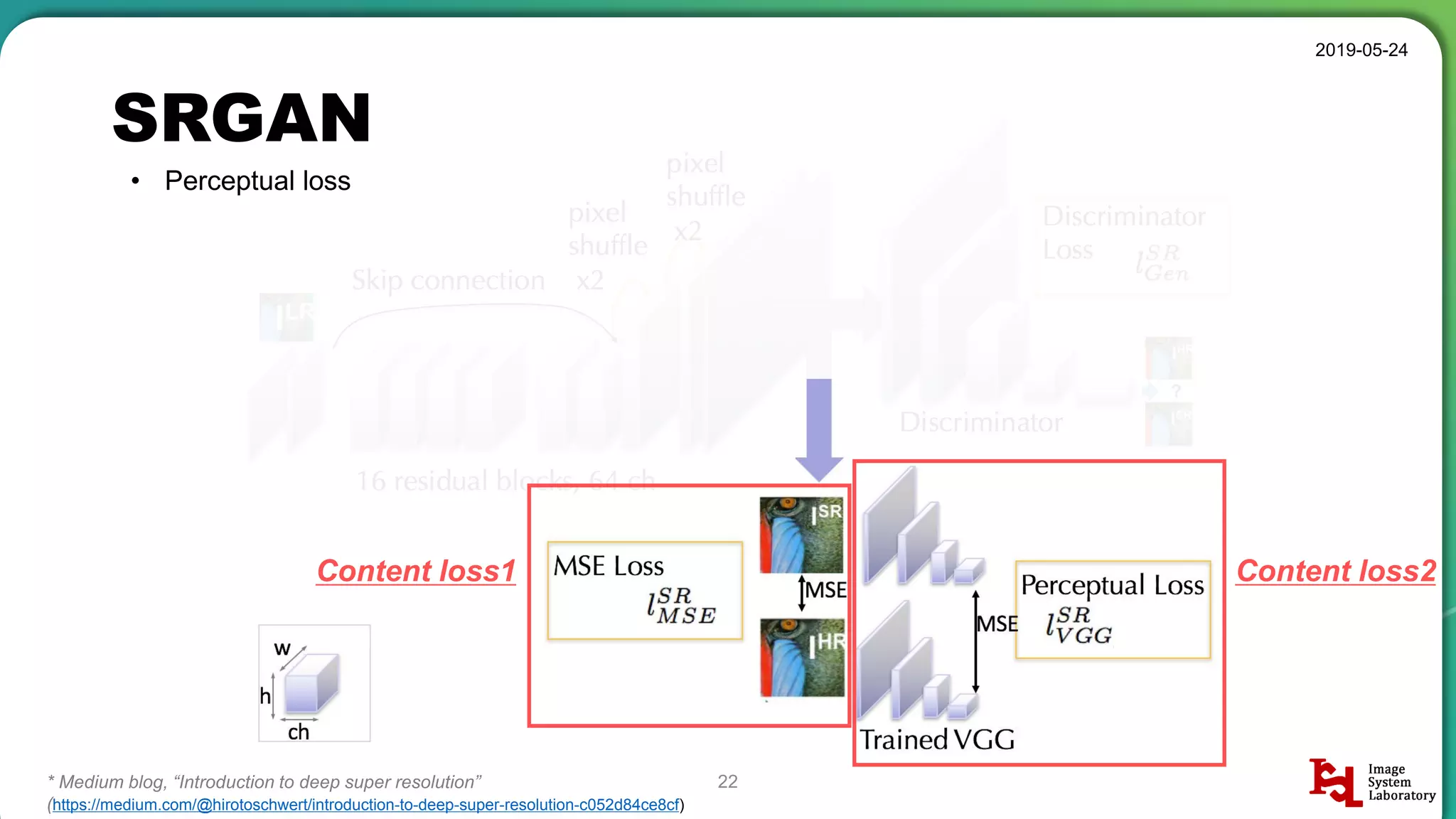
Explanation of perceptual loss in SRGAN. Details on content loss and adversarial loss, emphasizing their importance in generating high-quality images.
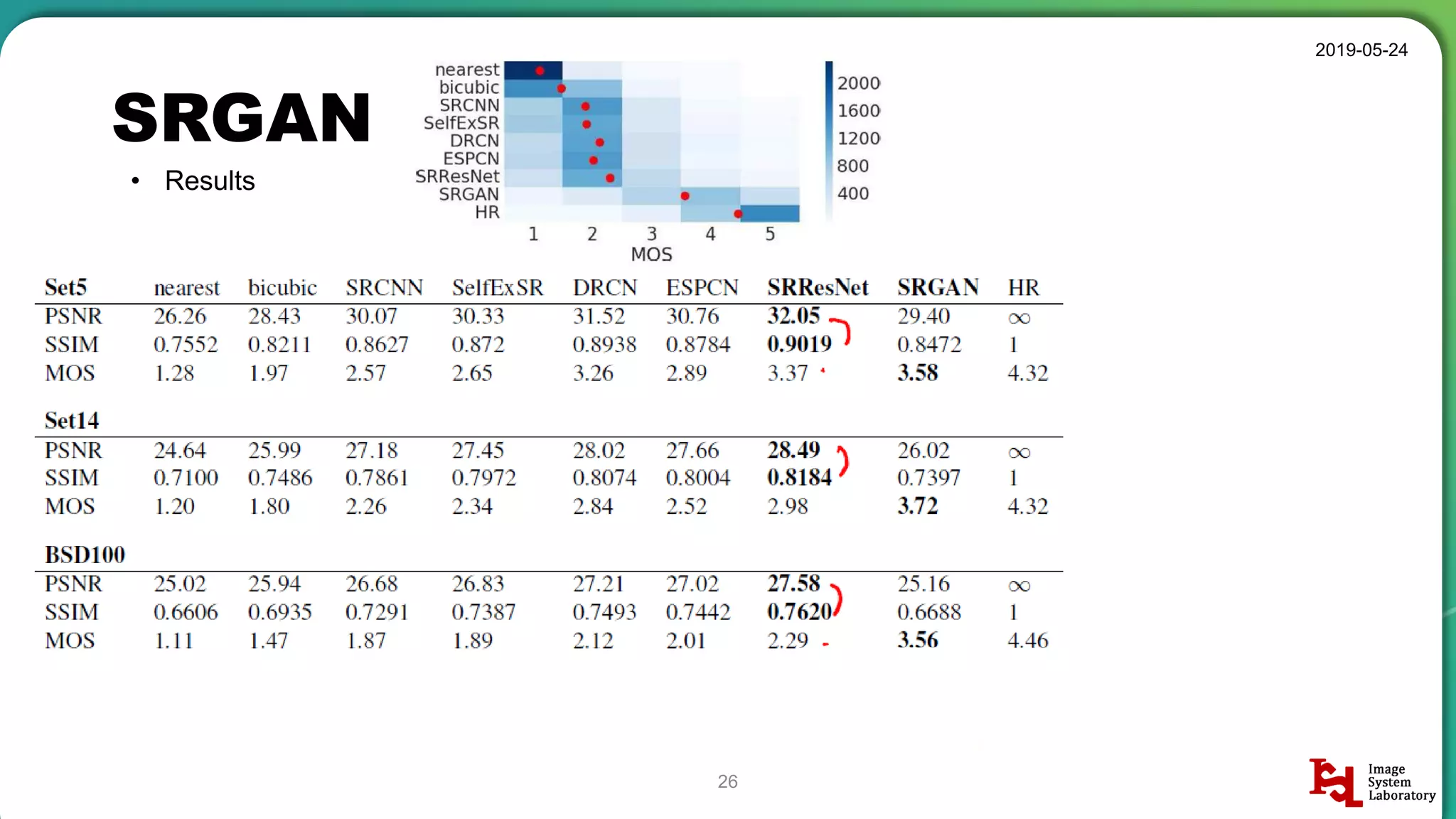
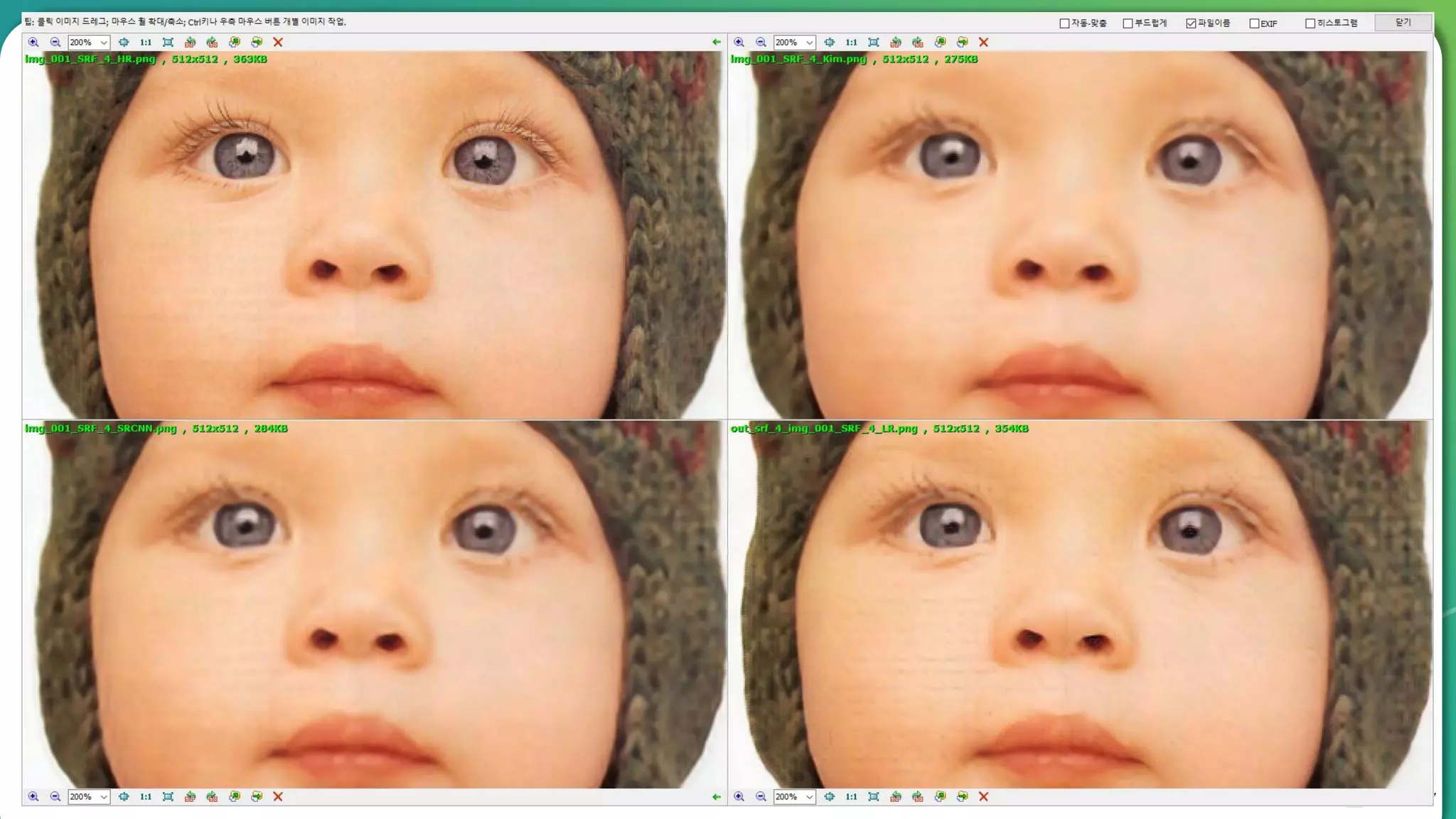
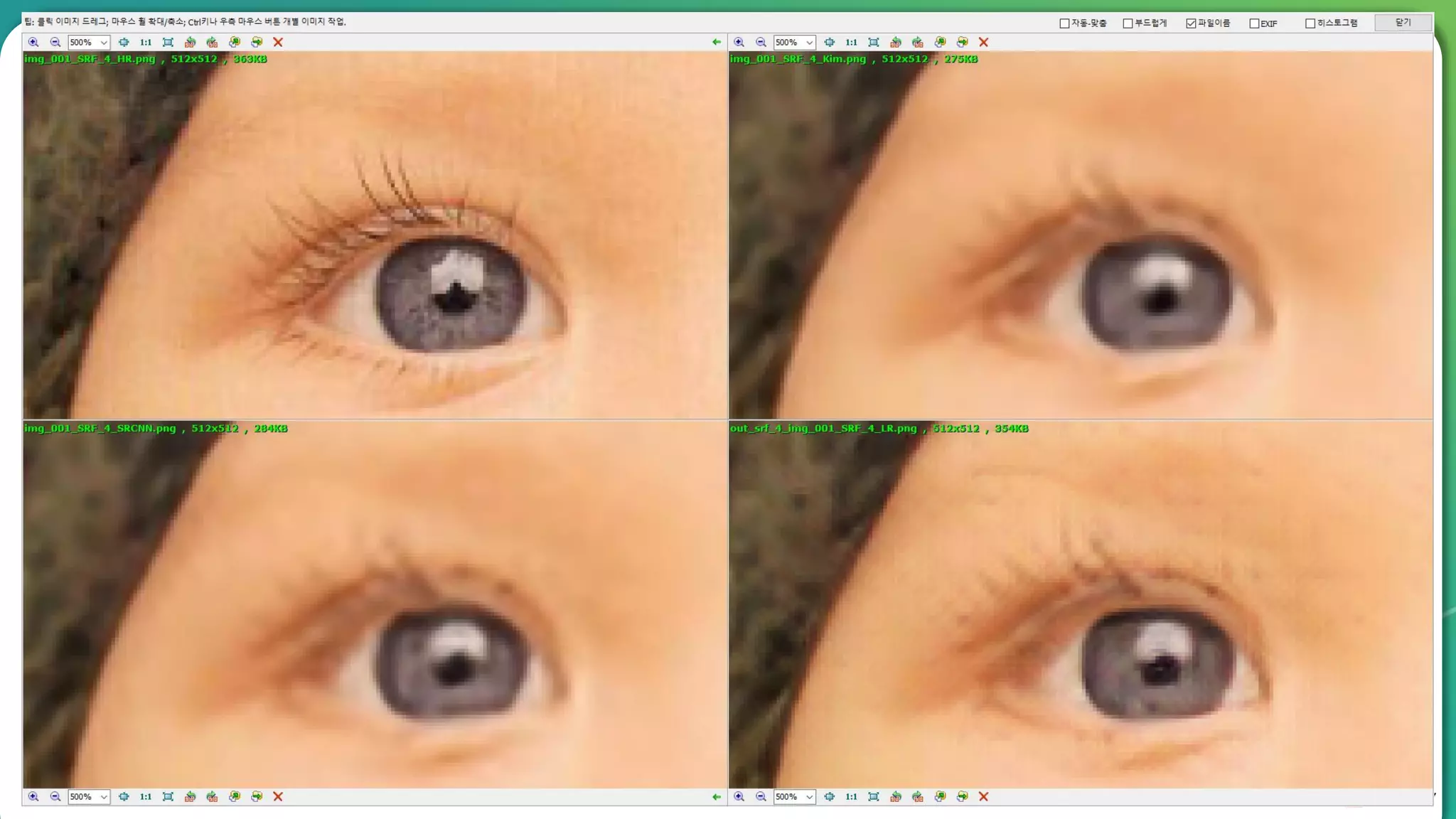
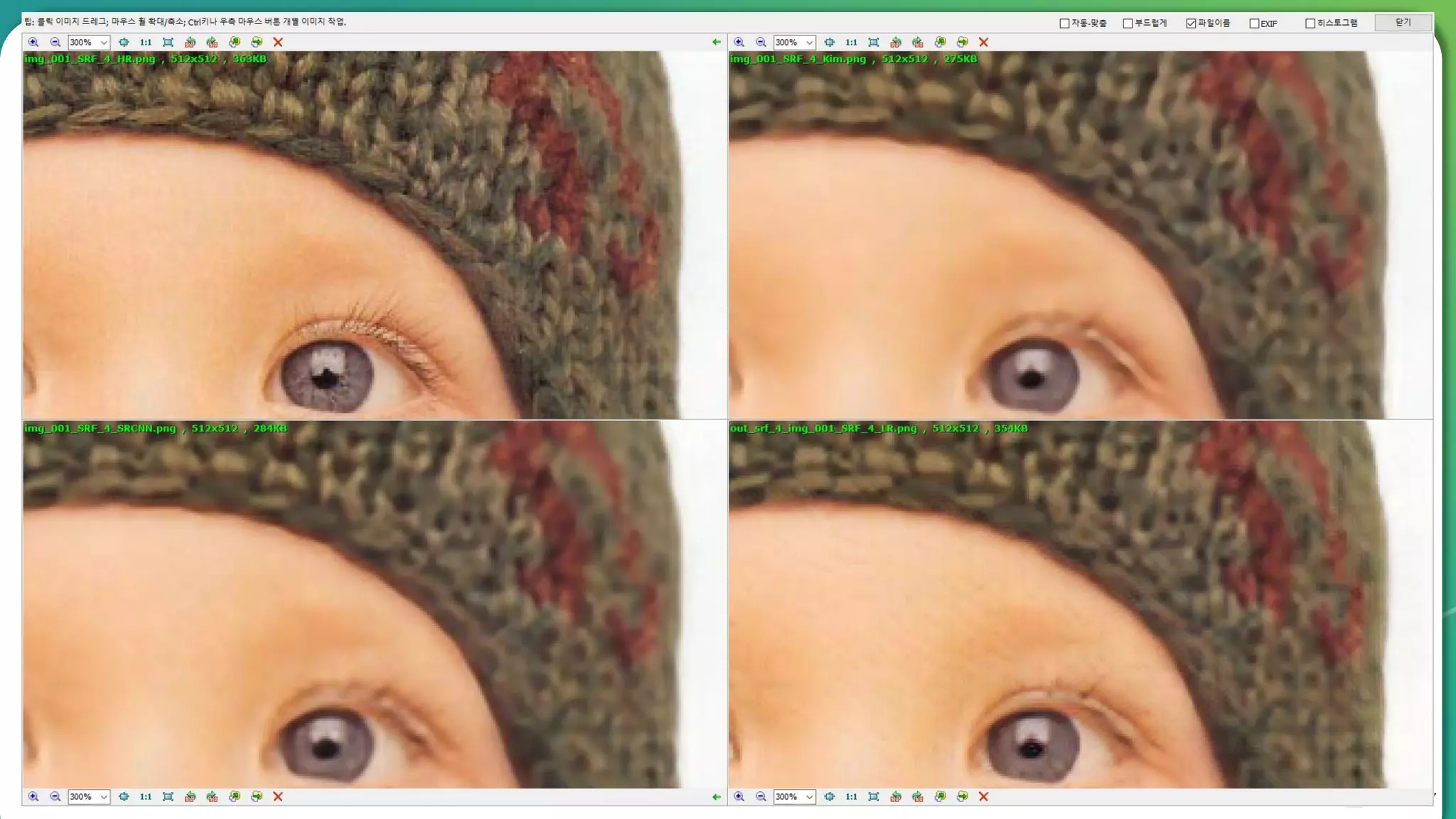
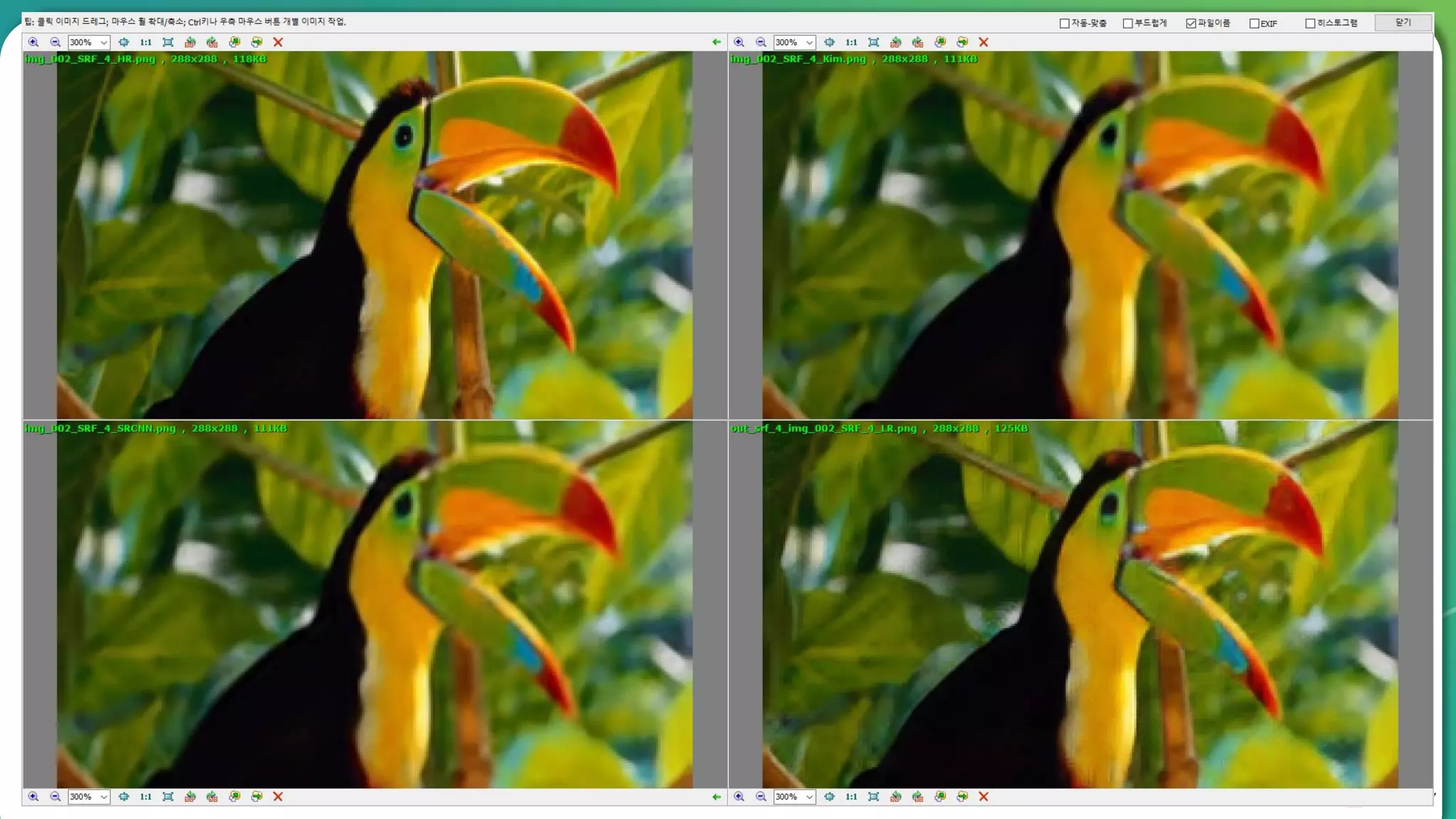
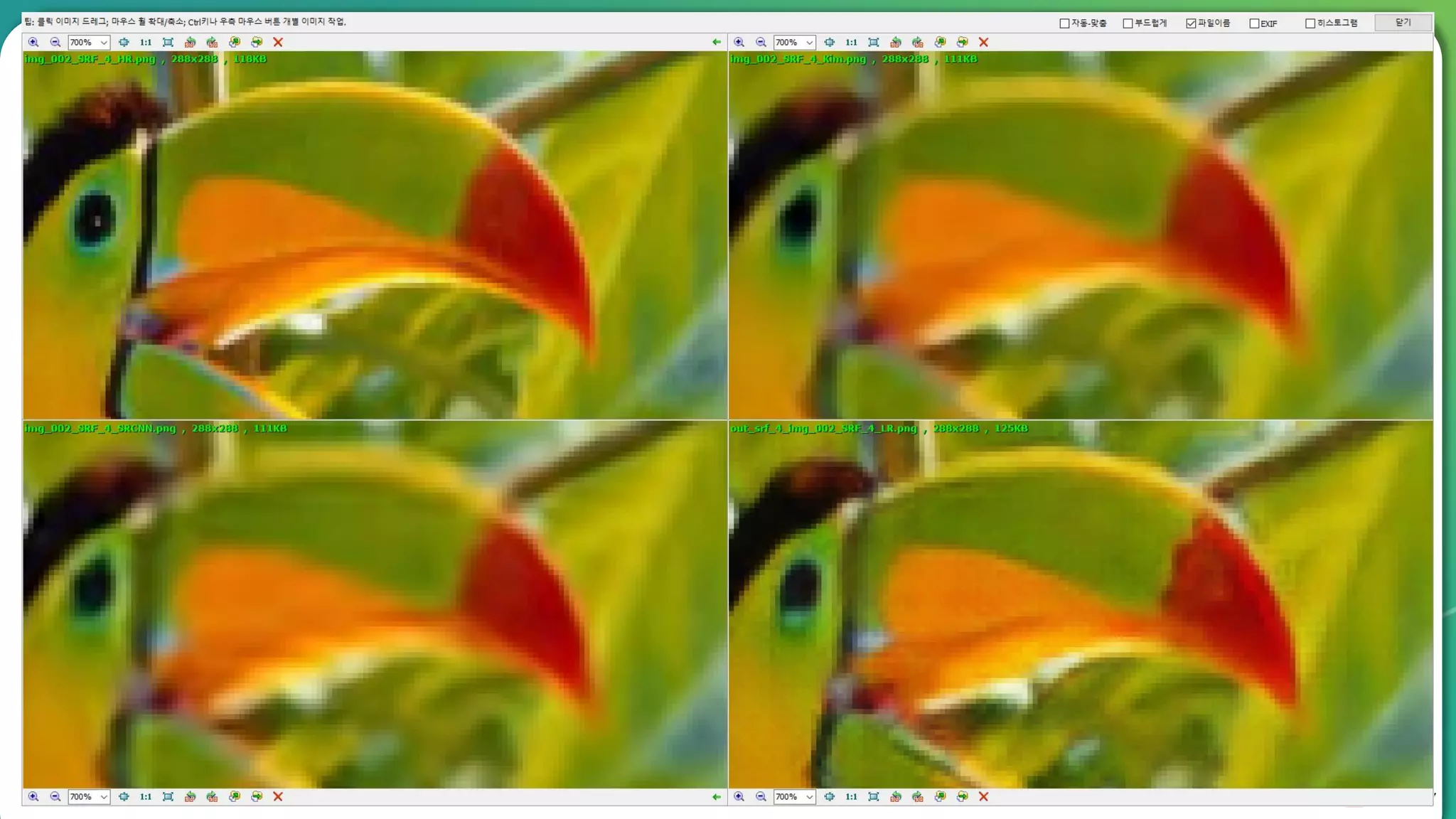
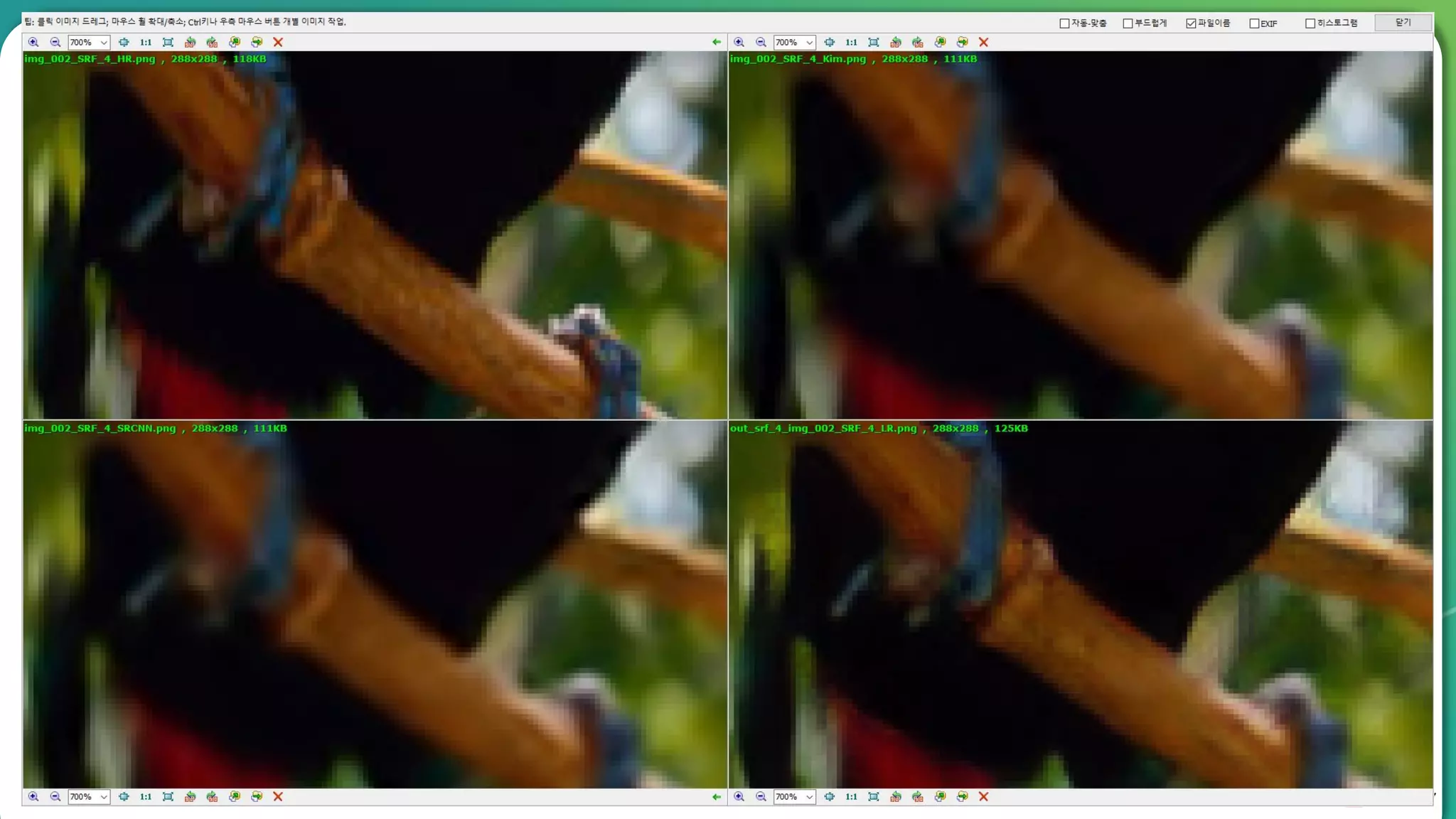
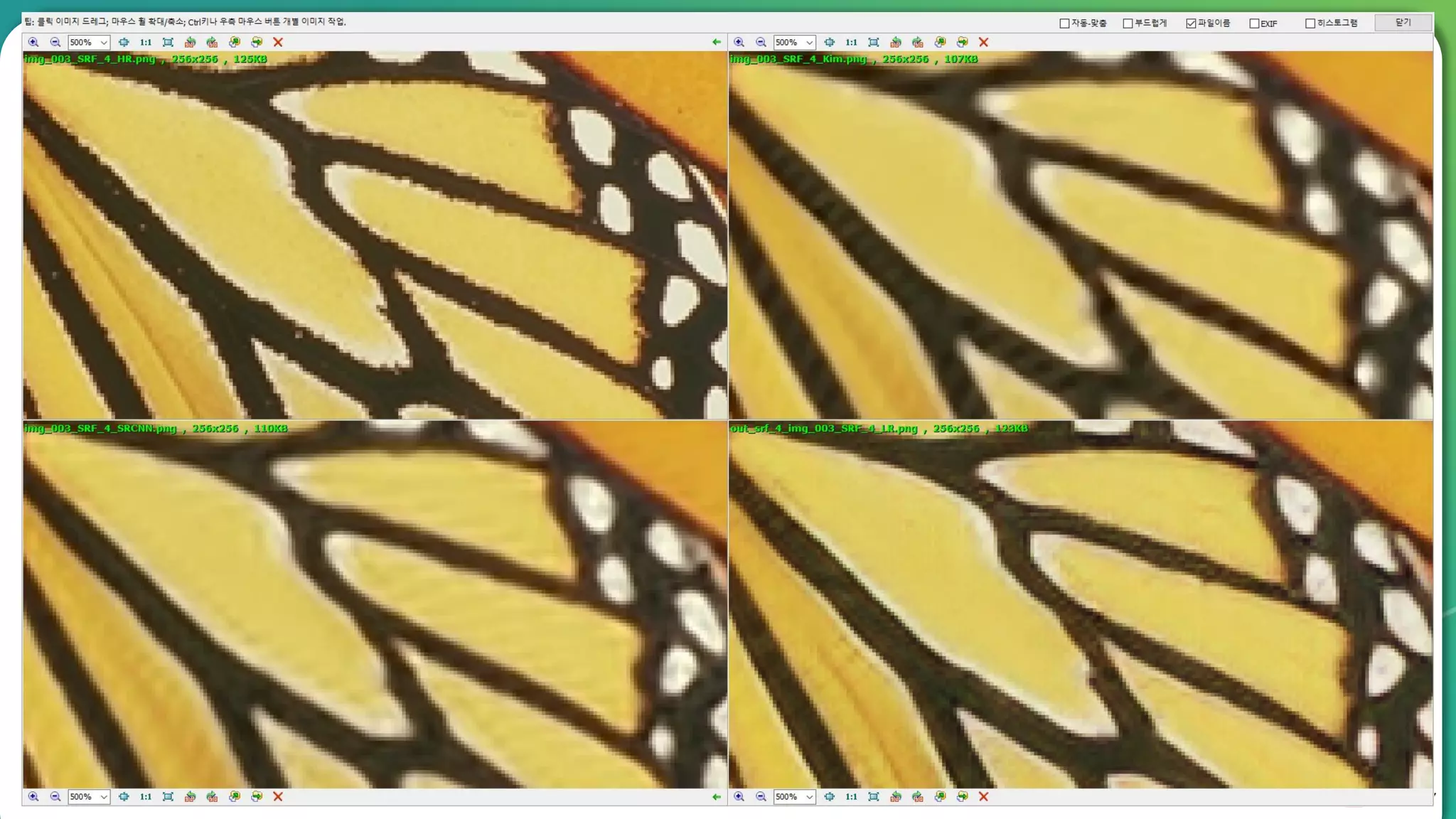
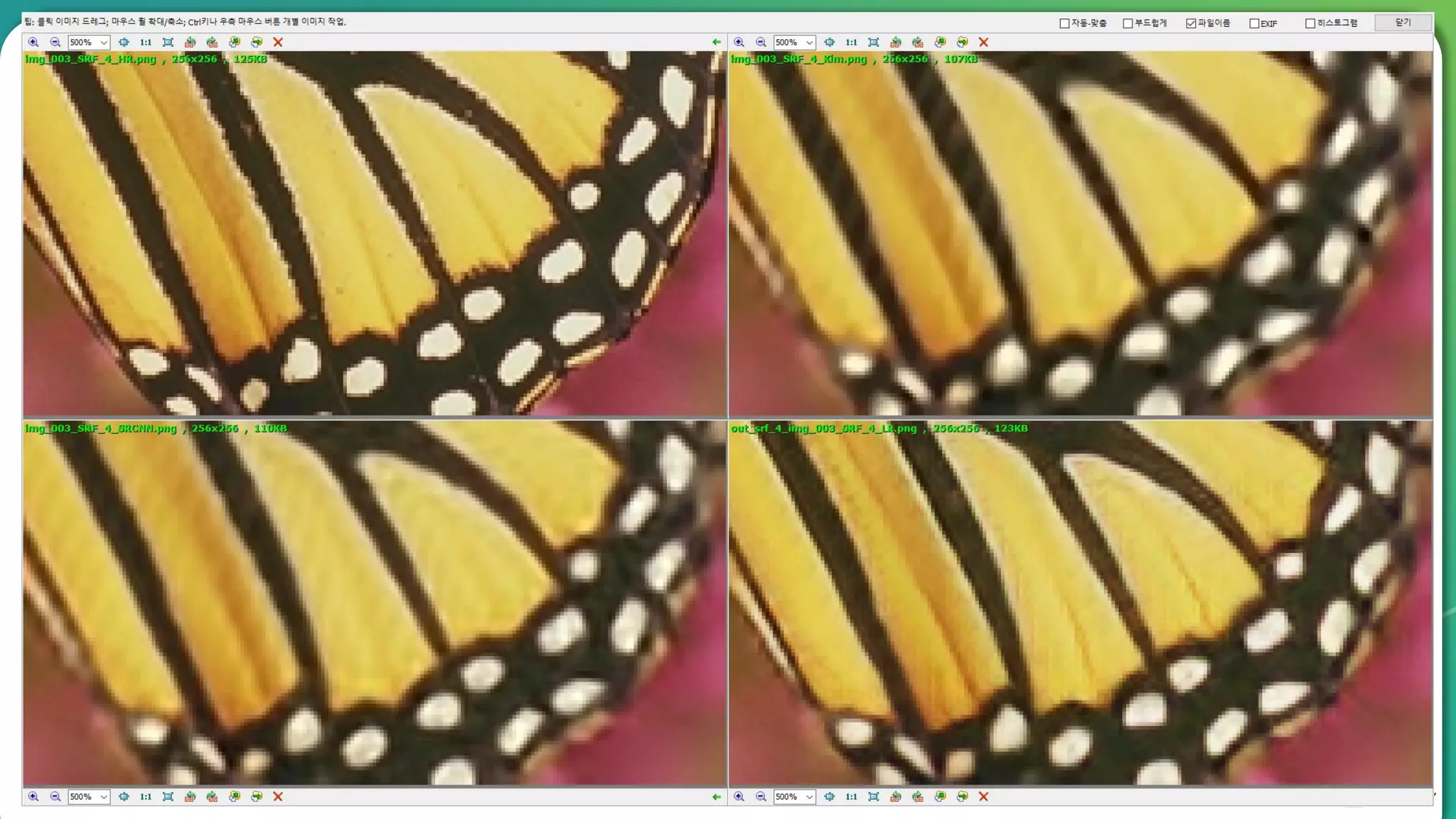
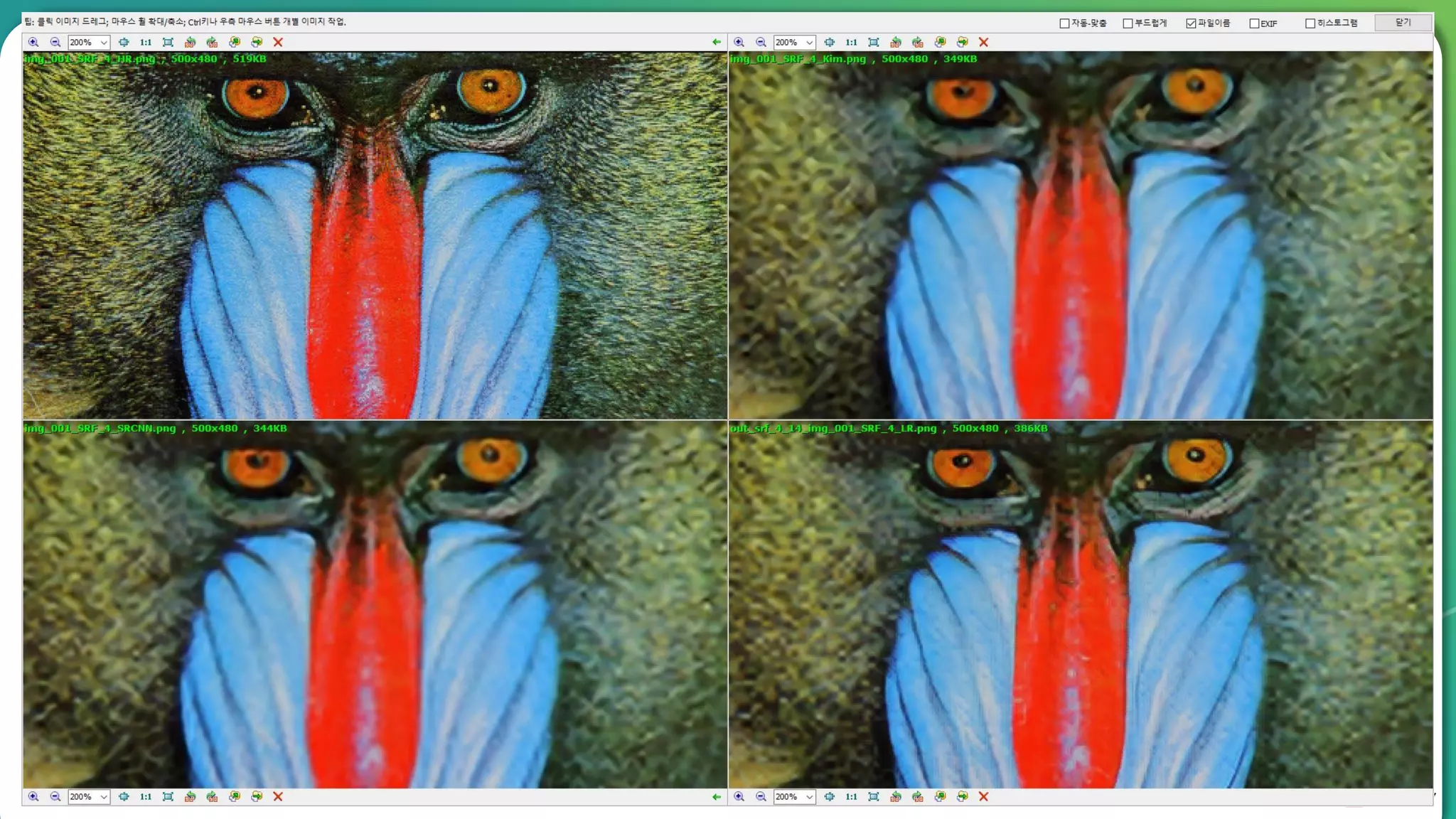
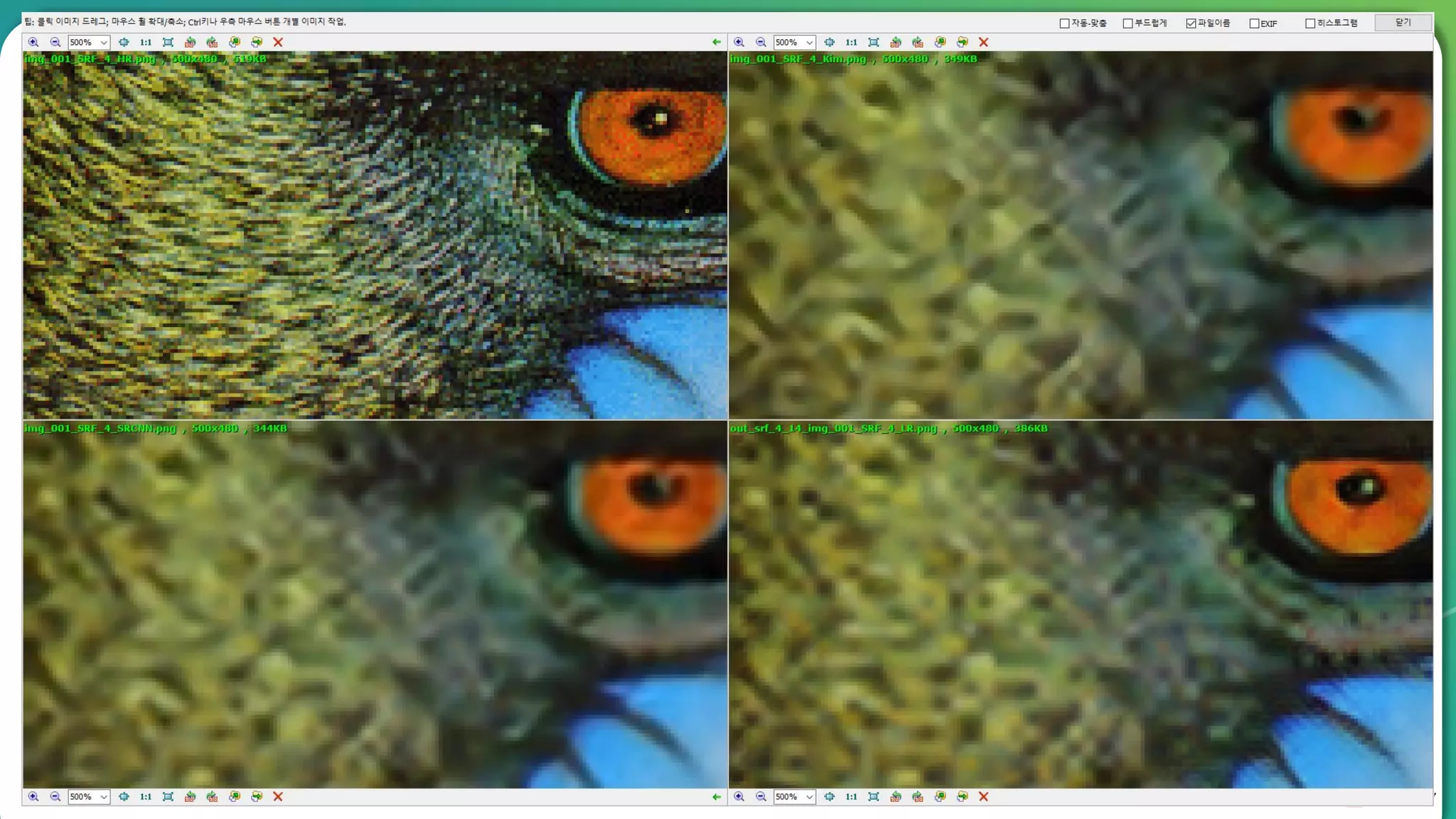
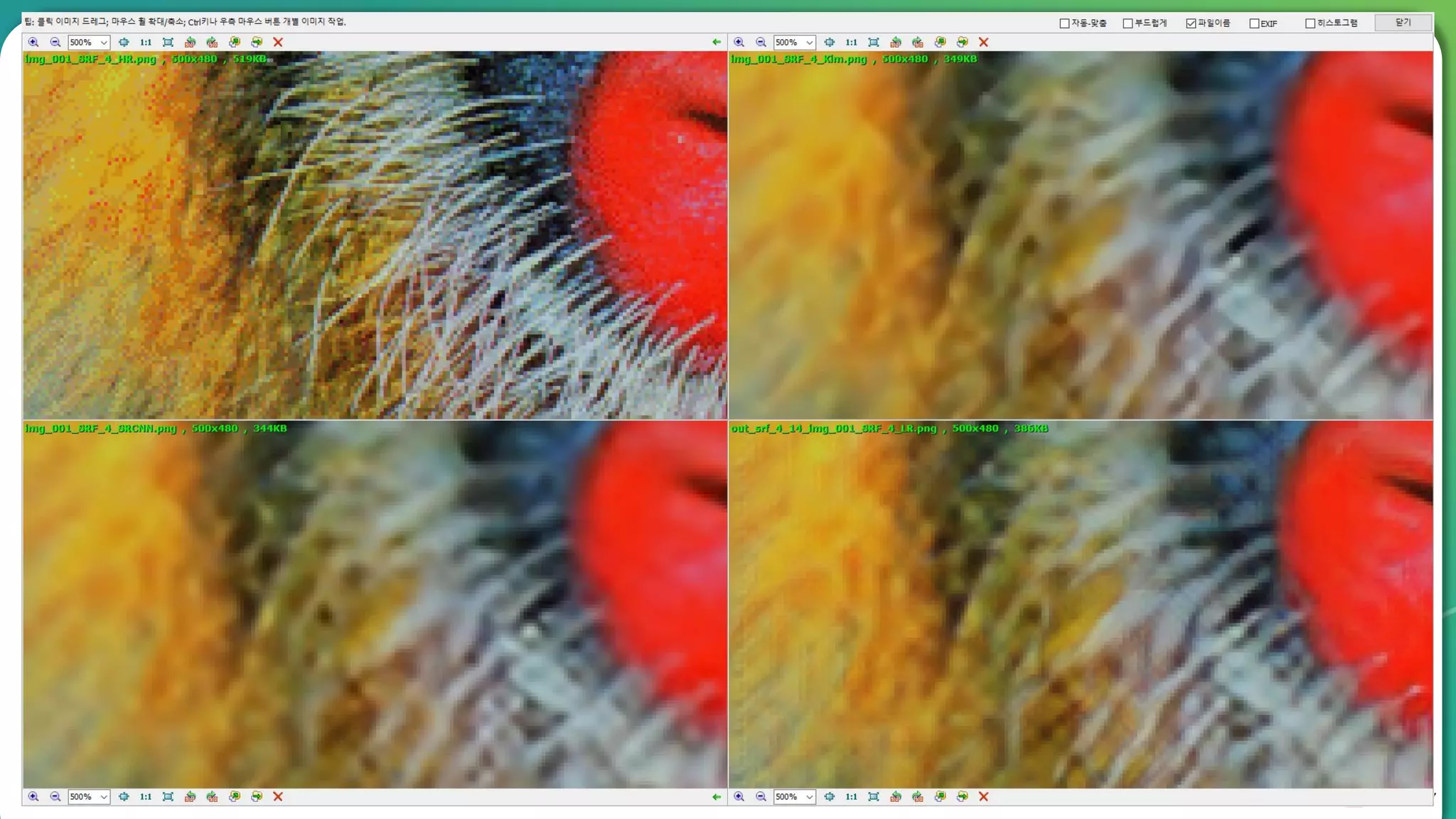
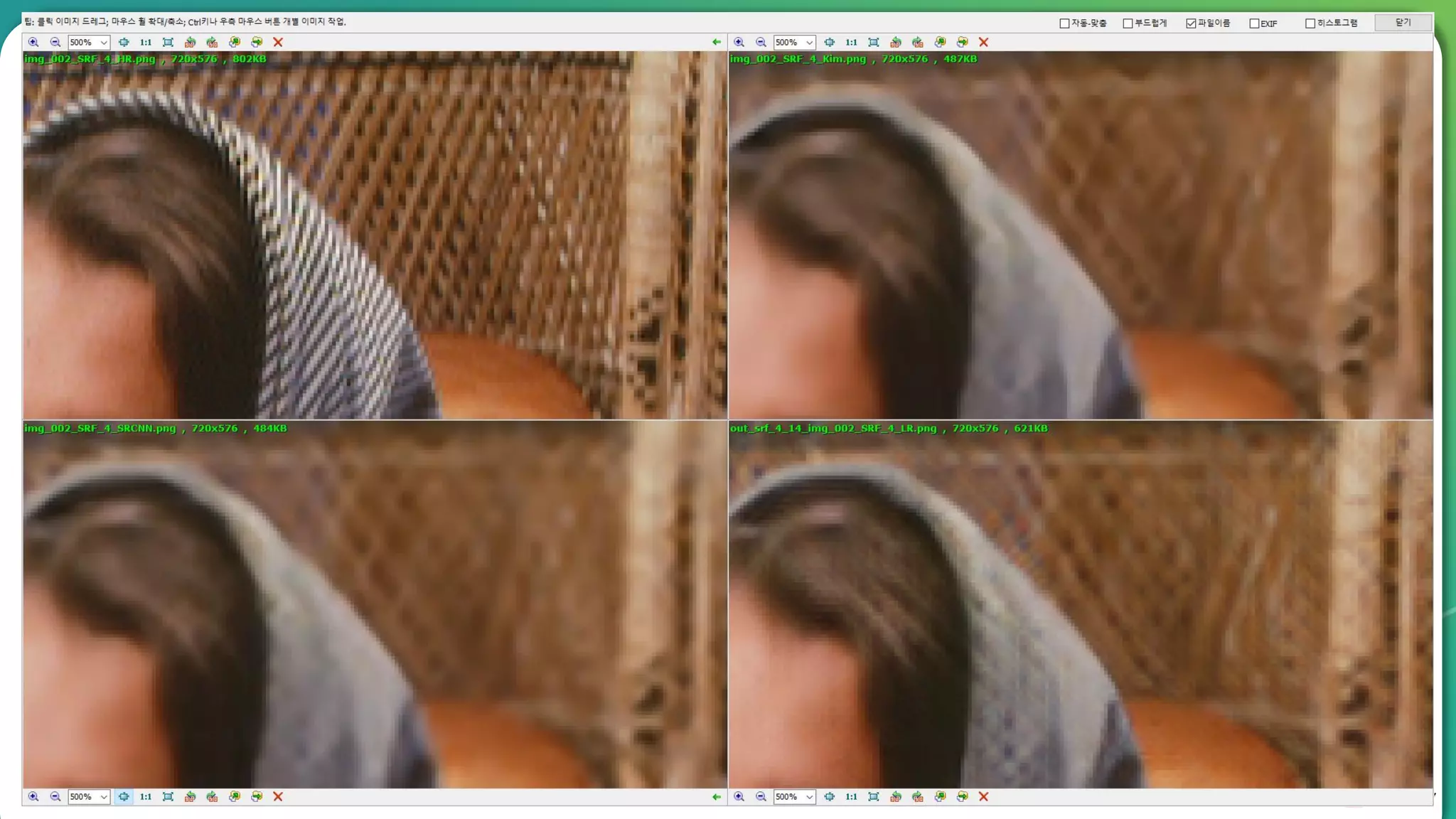
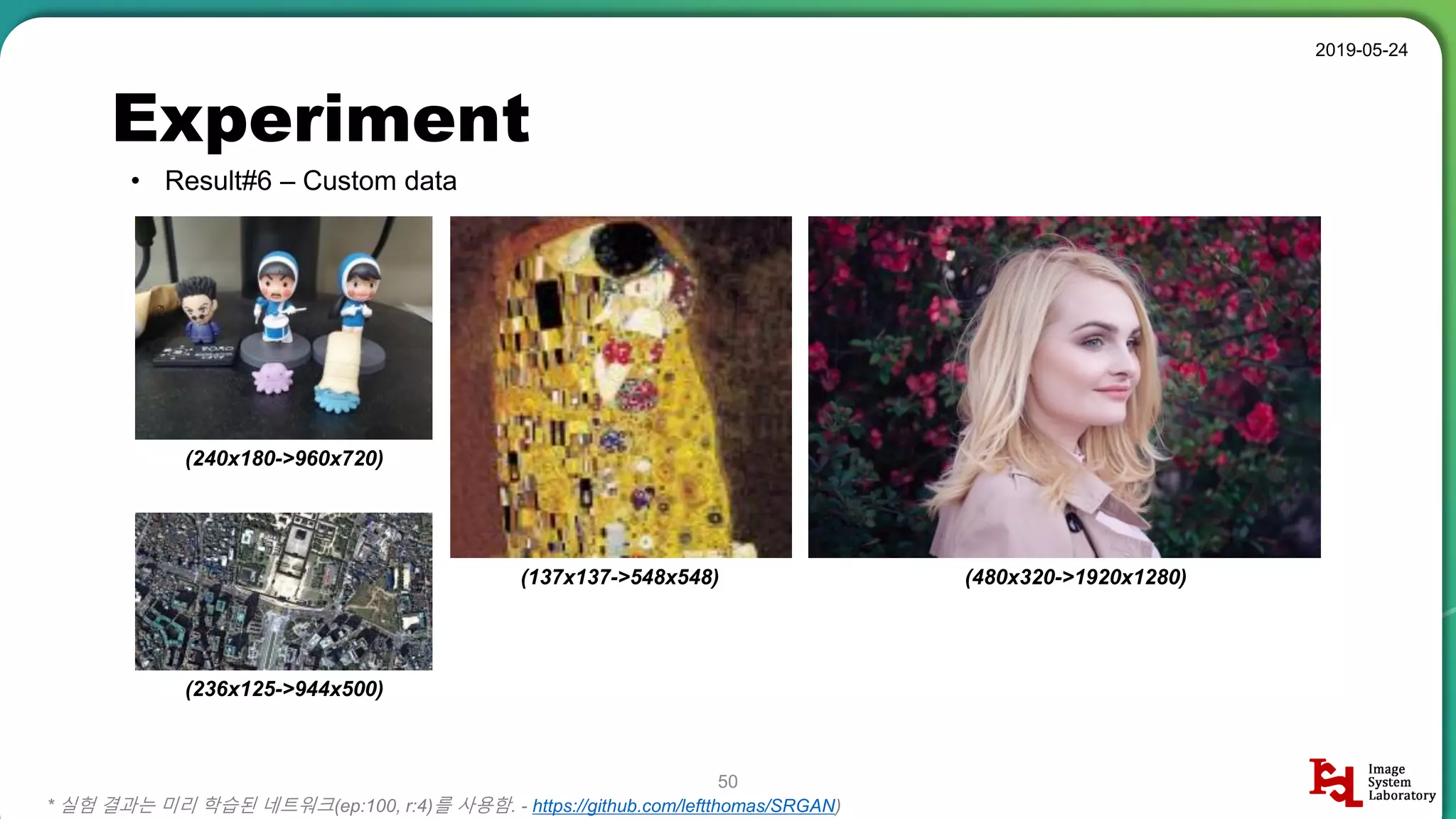
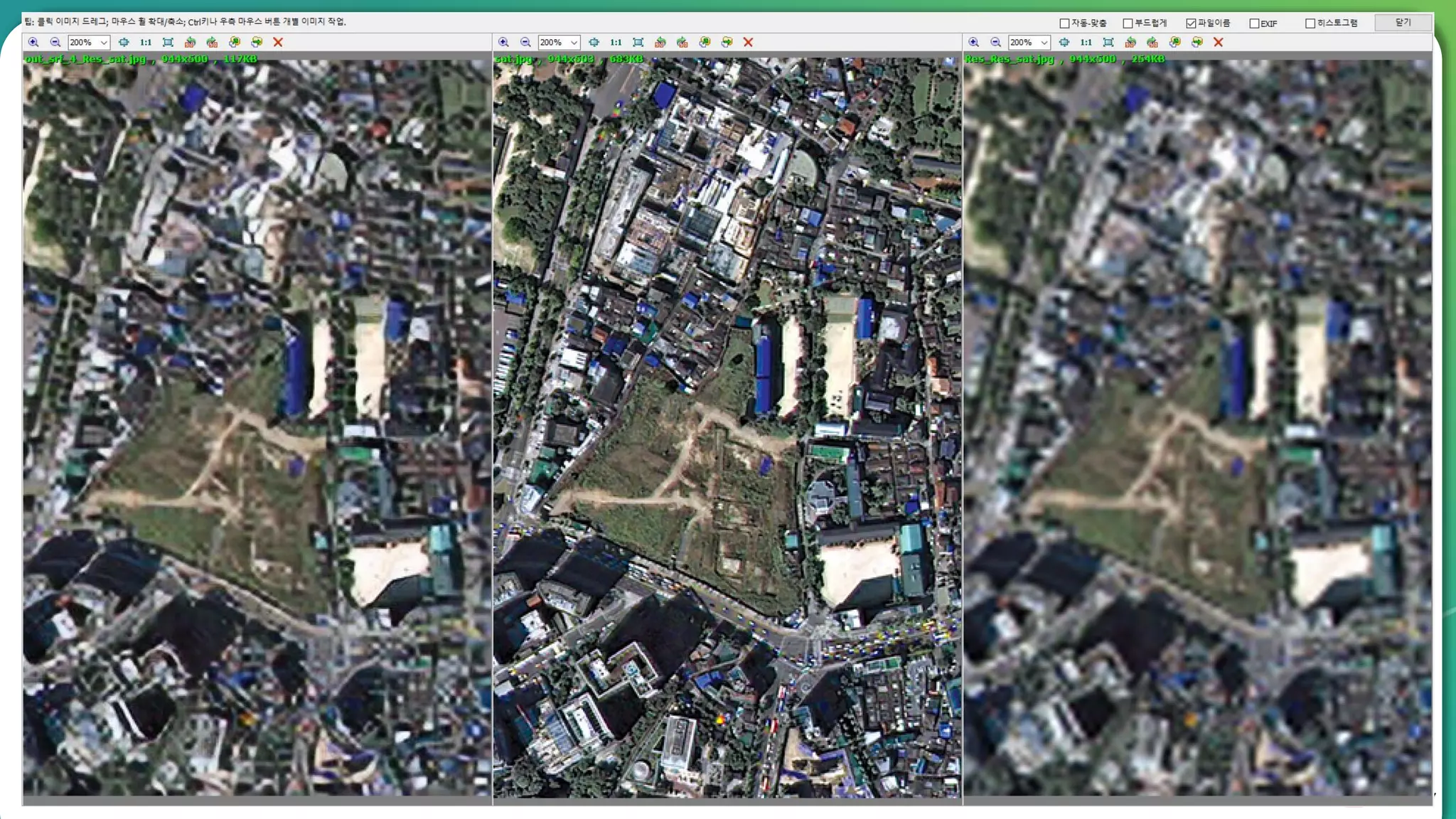
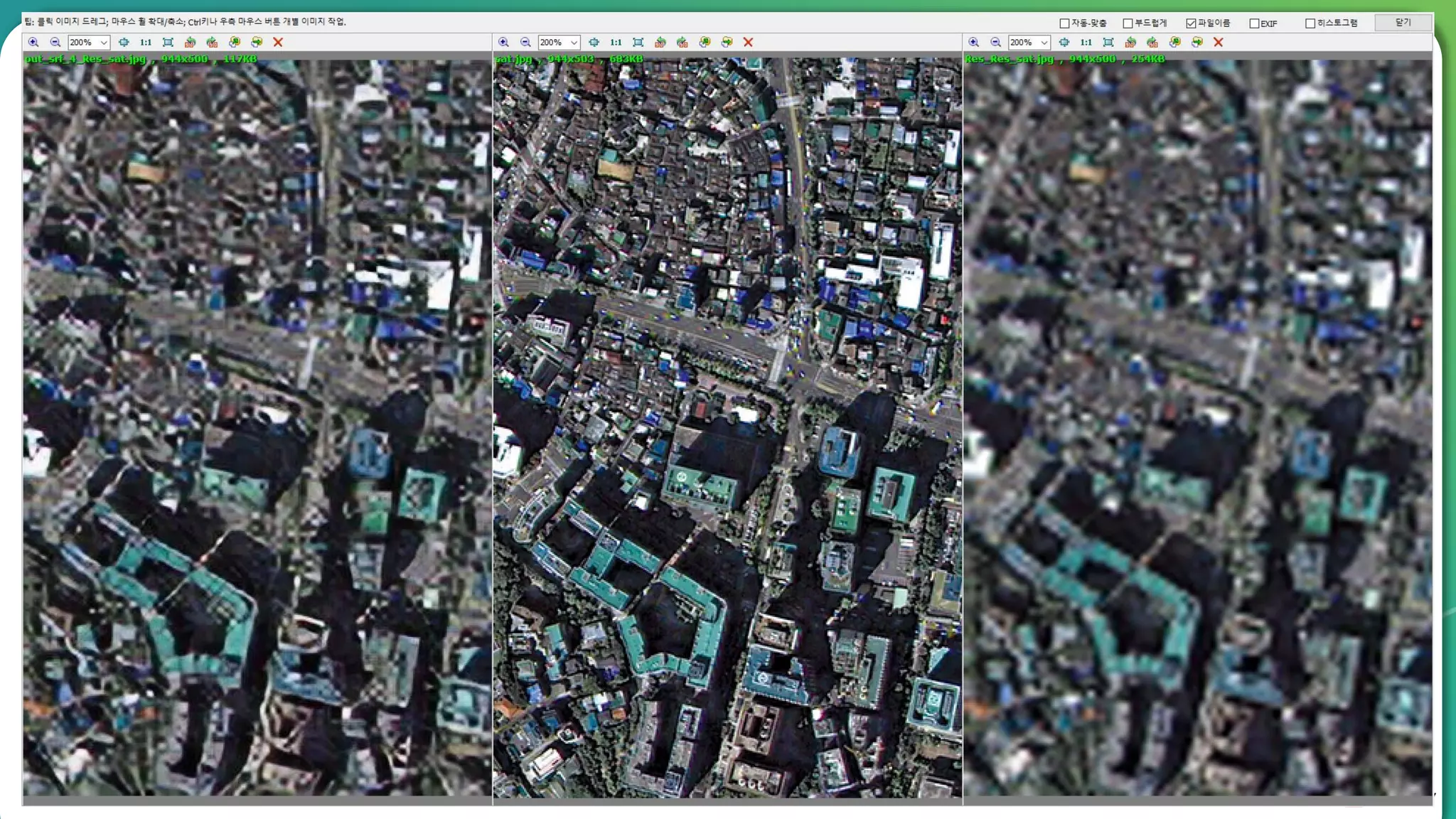
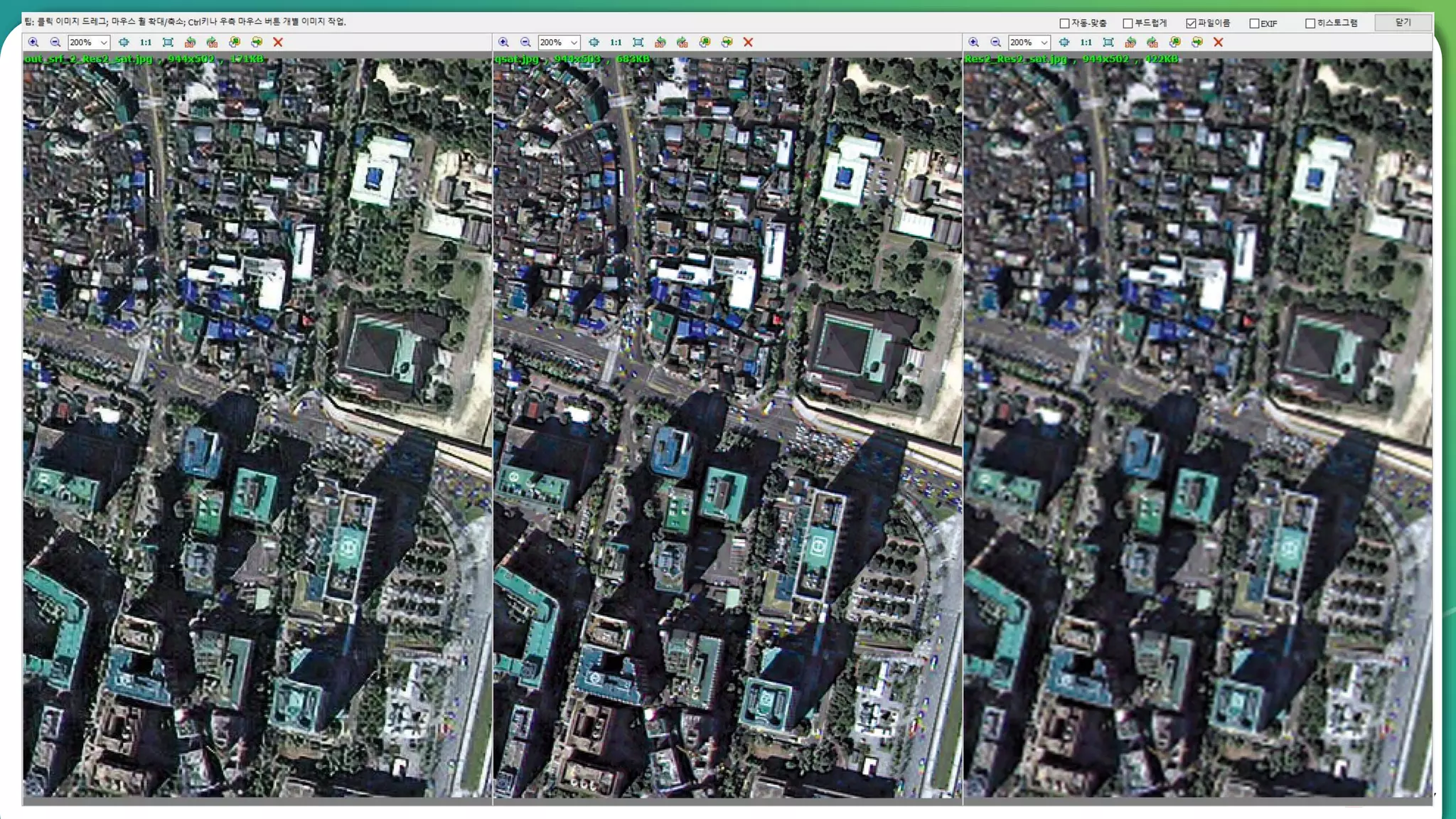
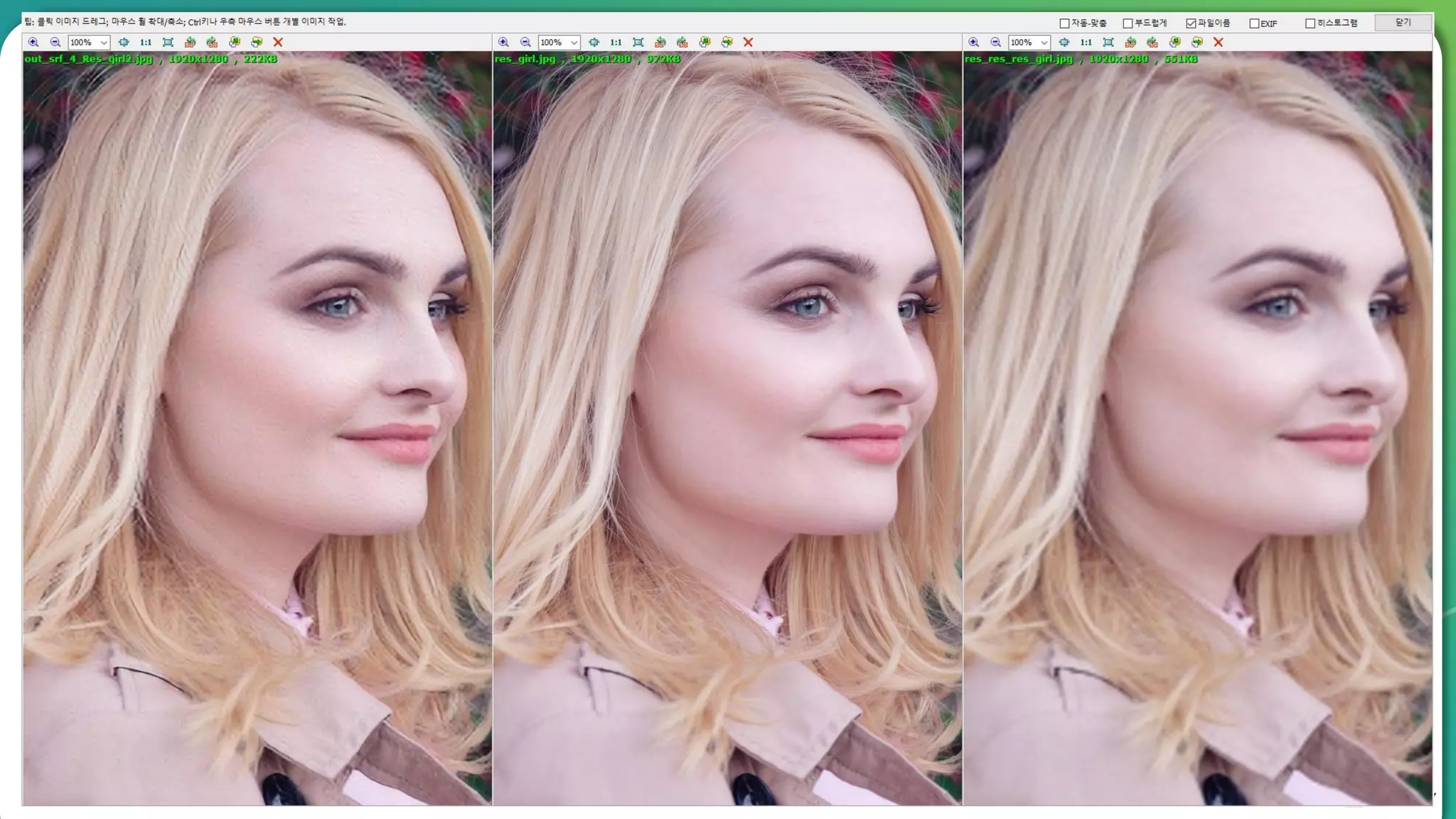
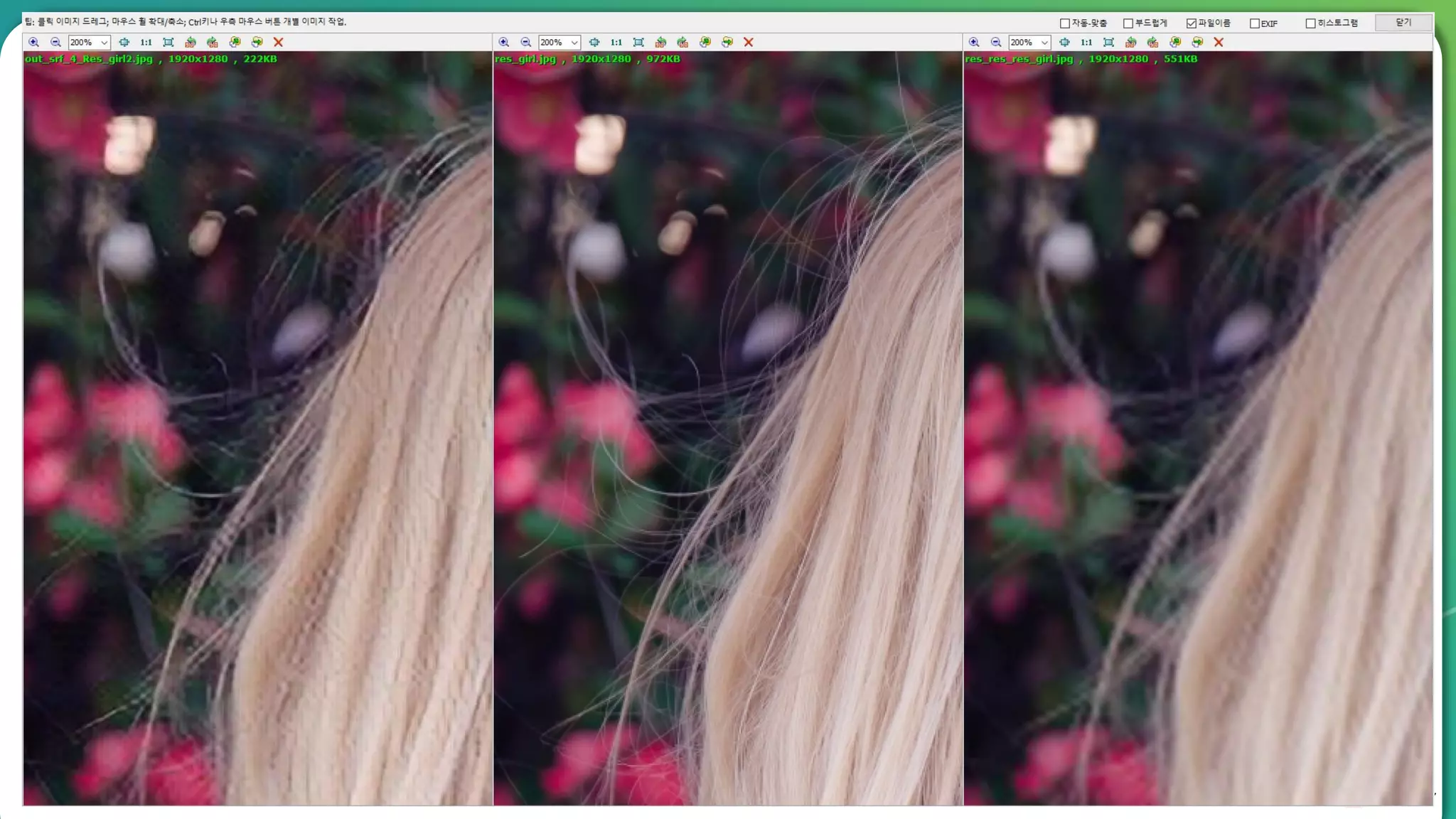
Results overview using various datasets (Set5, Set14, BSD100). Discussion on Mean Opinion Score (MOS) evaluations and implications of adversarial loss.
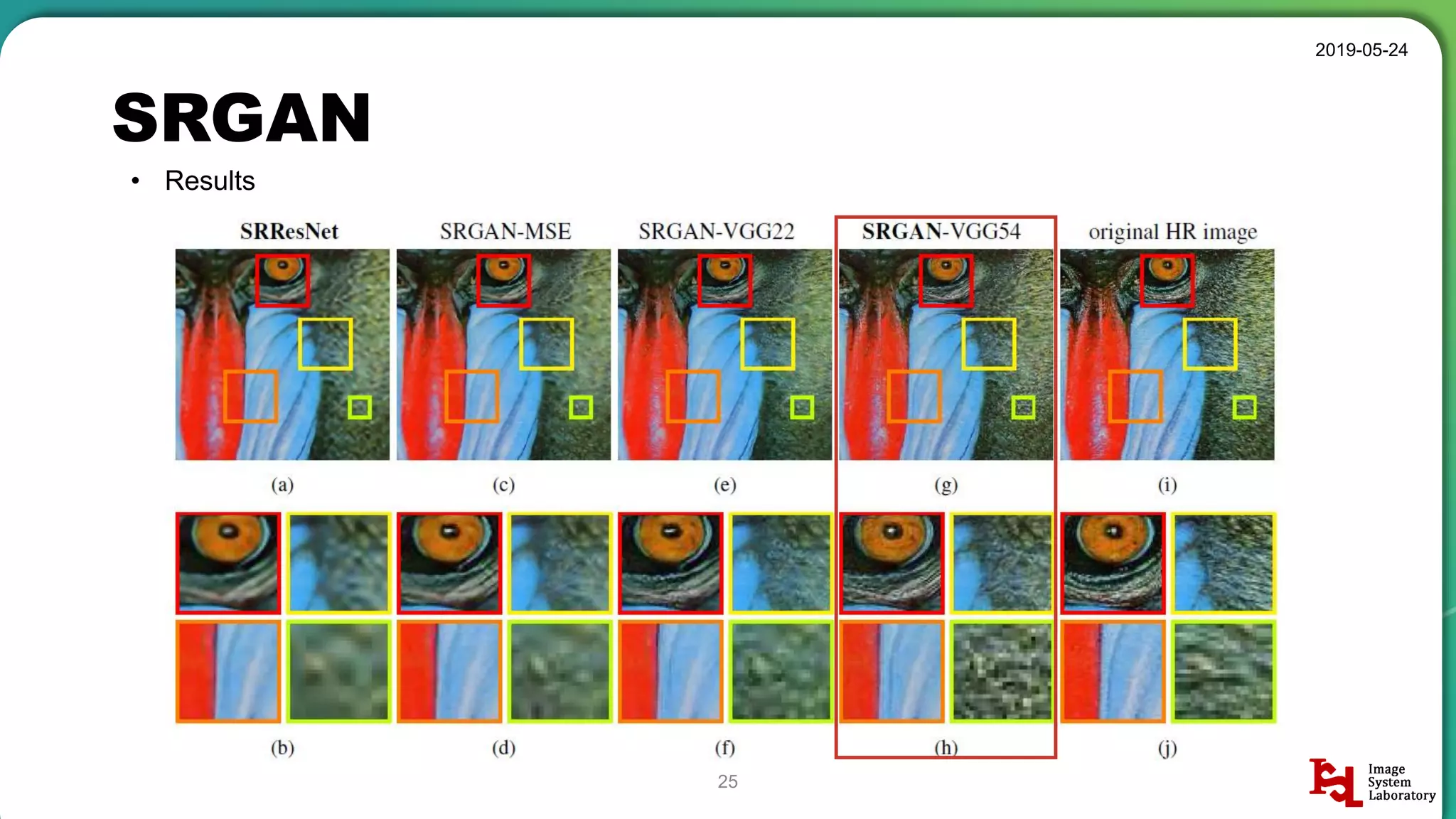
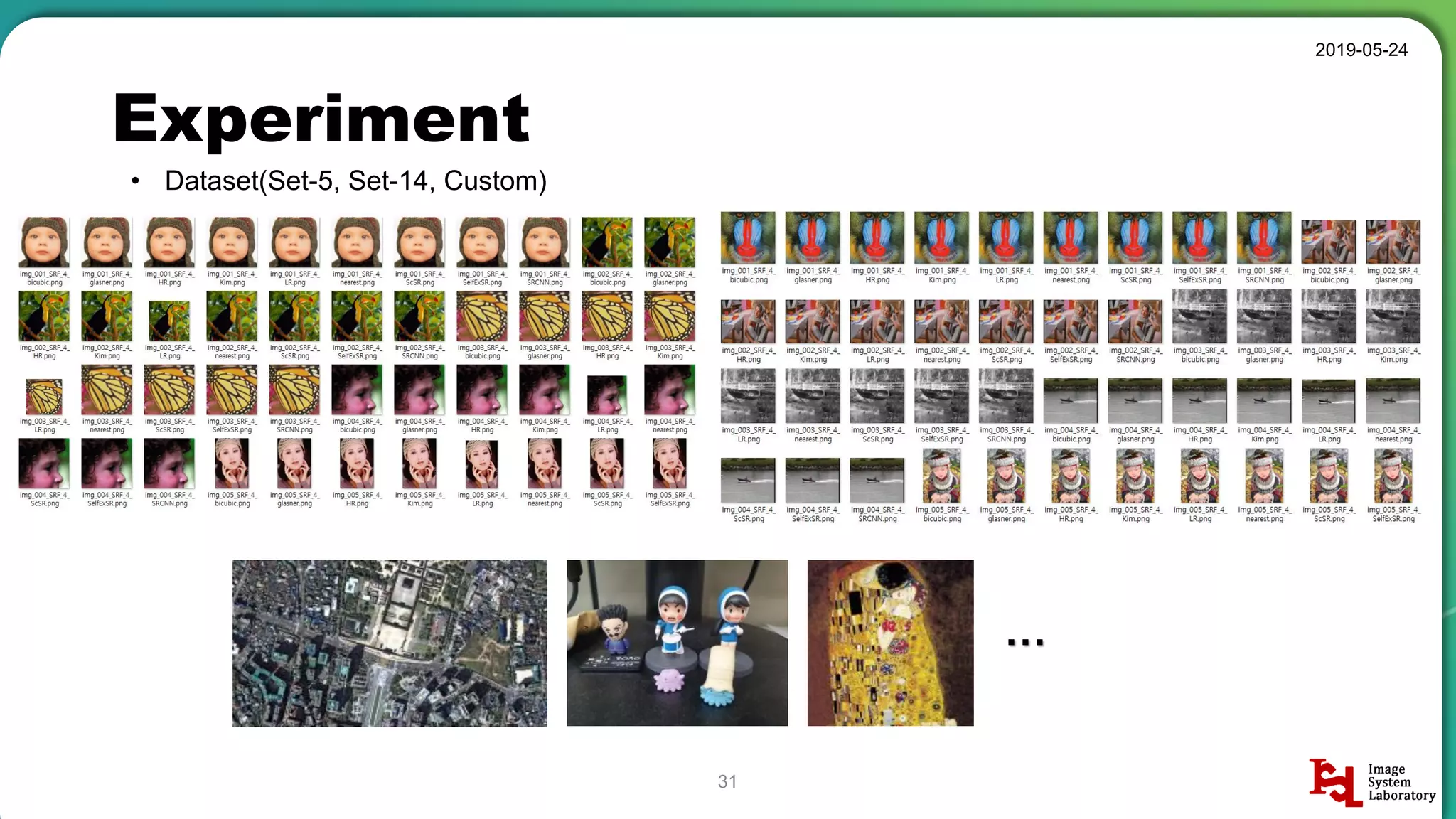
Detailed breakdown of experiments conducted, including source code, dataset usage, and examples from Set5 and Set14 results.
Summary of the findings highlighting the enhancement of MOS metrics. Plans for further research in GANs and associated technologies.













![ViT (Vision Transformer) Review [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/vitreviewcdm-201012184226-thumbnail.jpg?width=640&height=640&fit=bounds)






















































![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)





![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)