Download to read offline

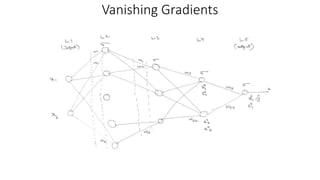

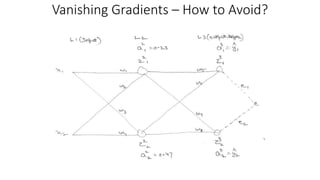



Vanishing gradients occur when error gradients become very small during backpropagation, hindering convergence. This can happen when activation functions like sigmoid and tanh are used, as their derivatives are between 0 and 0.25. It affects earlier layers more due to more multiplicative terms. Using ReLU activations helps as their derivative is 1 for positive values. Initializing weights properly also helps prevent vanishing gradients. Exploding gradients occur when error gradients become very large, disrupting learning. It can be addressed through lower learning rates, gradient clipping, and gradient scaling.



































































