More Related Content

PDF
闇のニコニコ学会β - 闇と欲望とコンピュータビジョン 
PDF
第17回関西CVPRML勉強会 (一般物体認識) 1,2節 
PDF
関西CVPRML勉強会 2012.2.18 (一般物体認識 - データセット) 
PDF

PDF
Opencv object detection_takmin 
PPTX

ODP

PDF
Viewers also liked

PDF

PPTX

PDF
VIEW2013 Binarycode-based Object Recognition 
PPTX
おりこうさんな秘書 ―画像認識による高機能な艦これユーティリティへの挑戦― 
PPTX
艦これ支援ツール『おりこうさんな秘書』解説 1:チュートリアル 
PPTX
艦これ支援ツール『おりこうさんな秘書』解説 2:シーン認識編 
PDF

PPTX
Watson visual recognitionで簡単画像認識 
PDF

PDF

PDF
Similar to AV 画像認識とその周辺 - UT Startup Gym 講演資料

PDF
Face Recognition with OpenCV and scikit-learn 
PPTX
Image Retrieval Overview (from Traditional Local Features to Recent Deep Lear... 
PDF
Retail Face Analysis Inside-Out 
PDF

PDF

PDF
Fast, Accurate Detection of 100,000 Object Classes on a Single Machine 
PDF

PDF

PDF

PDF
20110904cvsaisentan(shirasy) 3 4_3 
PDF
2016年1月期 AITCオープンラボ 「第1回 機械学習勉強会 ~Deep Learningを使って訪問者判定してみた」 
PDF

PDF
【2015.05】cvpaper.challenge@CVPR2015 
PDF

DOCX

PPTX
深層学習を用いたコンピュータビジョン技術とスマートショップの実現 
PDF
静岡Developers勉強会コンピュータビジョンvol2 
PDF
これからのコンピュータビジョン技術 - cvpaper.challenge in PRMU Grand Challenge 2016 (PRMU研究会 2... 
PDF
コンピュータビジョンで作る未来の栽培技術POL共催セミナー_20220527 
PDF
コンピュータビジョン7章資料_20140830読書会 AV 画像認識とその周辺 - UT Startup Gym 講演資料
- 1.
- 2.
- 3.
予定
1.自己紹介 ← やや長い
1.趣味
2. 職歴
3. 研究
2.AV顔画像検索ツール
1. 概要
2. システム詳細
3.関連面白研究 (論文参照)
1. 画像補完
2. スケッチからの写真検索
3. 近年の顔認識
4.まとめ
5.質疑応答
- 4.
1. 自己紹介
● ぱろすけ
●http://parosky.net
● 東大 情報理工 修士1年
● Activity
– プログラムとか書いてる
– ベンチャーとかやってた
– 研究してる
– 就活してる
- 5.
1. 1. プログラミング
●趣味でいろいろ書いてる
● ツール:AV顔画像検索, 人気エロ動画DL, 2chまとめサイト自動生成,
Twitter画像まとめサイト自動生成
● Android: 『赤い配管工』, 『ゴリラ』
● Twitterボット: @parosky1, @anniv_salad, @1000favs_
● その他いくつかの小ネタ
- 6.
1. 1. 1.ツール
● AV顔画像検索
● 後述
● 人気エロ動画DL
● XVIDEOS からはてブ数が多いものを自動で収集
● 2chまとめサイト自動生成
● 全盛期で 5,000PV / day くらい
● Twitter画像まとめサイト自動生成
● 現在 3,000PV / day くらい
- 7.
1. 1. 2.Android
● 赤い配管工 (およそ30,000DL)
● タッチで操作する
横スクロール2Dクソゲー
● Androidの練習的な感じで作った
● ゴリラ (およそ700DL)
● 「ゴリラを眺めて癒されよう!」
● いわゆる「鏡」
- 8.
1. 1. 3.Twitterボット
● @parosky1 (約80,000フォロワー)
● 発言は僕のメインアカウントのコピー
● フォロワーを増やすためのいくつかの工夫
● @anniv_salad (約1,700フォロワー)
● 全自動俵万智
● @1000favs_ (約90,000フォロワー)
● 丸パクリボット @1000favs を丸パクリするボット
- 9.
1. 2. 職歴
●ベンチャーとかやってた (2011/08 - 2012/10)
● Web系のスタートアップの創業メンバ
● ASCII とか WIRED とかに載ったらしい
● 某社の起業家支援プログラムに採択
● Python/Django, JavaScript, ActionScript とか書いてた
● AWS でサーバの構築と管理とかしてた
● 今も別のベンチャー的なのに一応コミット
- 10.
- 11.
2. 1. 1.反響
● 反響(半月間)
● 85,000PV
● 3,500ツイート
● 1,200はてブ
● 500いいね
● 200本の売上 (=10万円)
● 反響(長期)
● 週刊アスキーに掲載
● UT Startup Gym から
声がかかった
● 論文がベストペーパー取った
● いろんな人と仲良くなった
AVすごい
- 12.
2. 1. 2.システム概要
● データベースの構築
1. DMM. R18 からAVのサンプ
ル画像を取得(16万タイトル
170万枚)
2. 画像群から顔検出して保存
(35万枚)
3. 特徴抽出 (2.5GB)
4. 主成分分析で圧縮 (70MB)
5. 保存
● 検索
1. 入力画像から顔検出
2. 特徴抽出
3. データベースを近傍探索
4. 結果をタイトルと合わせて表示
特徴抽出: 生データから推定や分析に有用な情報を抽出すること.
(ここでは「1枚の画像を何らかの方法で1本のベクトルに変換すること」)
主成分分析: データの冗長な部分を除いて次元を削減する手法.
近傍探索: 近くにあるデータを探すこと. 総当たりより効率的な方法がある.
顔検出: Viola & Jones の手法が有名.
- 13.
2. 2. 1.特徴抽出
● 画像そのままでは扱いづらい
● たとえば類似性はどう判断しよう? -> 全体の色合いを比べるとか?
– 左の画像は 縦22px * 横22px * 3色 = 1,452次元のデータ
– これを [赤, 緑, 青] = [0.2, 0.8, 0] と変換すれば3次元のデータに
● いろんな特徴量が提案されている
– 大域特徴: Color Histogram, HOG, GIST, HLAC, ...
– 局所特徴: SIFT, SURF, LBP, BRIEF, ...
– 局所特徴のコーディング: Bog of Features, Fischer Vector, …
– 今回は HOG を利用
- 14.
2. 2. 1.特徴抽出
● HOG (Histogram of Oriented Gradients) [Dalal et al., 05]
● 画像をグリッドで区切って
それぞれで明るさの勾配の
ヒストグラムを計算
● 今回のシステムでは顔画像が
1,764次元のベクトルに
hog = cv2.HOGDescriptor((64, 64), (16, 16), (8, 8), (8, 8), 9)
img = cv2.imread('face.jpg')
h = hog.compute(img)
Python/OpenCV を使えば
一瞬で計算可能
- 15.
2. 2. 2.主成分分析
● あんま意味のない次元を削る (荒っぽい解釈)
● データ量の削減, 「次元の呪い」の回避
● 今回のシステムでは1,764次元 → 100次元に削減
[http://www.nlpca.org/]
pca = sklearn.decomposition.PCA(dim)
r = pca.fit_transform(data);
Python/SciKits を使えば
一瞬で計算可能
- 16.
2. 2. 3.近傍探索
● この画像はどの画像と近いか?
→ この画像の特徴ベクトルはどの画像の特徴ベクトルと近いか?
→ ベクトル空間上での距離を見ればいい (今回の実装)
● 普通に総当たりでやってもいい
● が, もっと早い方法がいくつか提案されている
● 今回は FLANN [Muja et al., 09] を使用
[http://www.emeraldinsight.com/cont
ent_images/fig/0870280310006.png]
index = cv2.flann_Index(features, {"algorithm":0})
idx, dist = index.knnSearch(data, n, params={})
Python/OpenCV を使えば
一瞬で計算可能
- 17.
2. 2. 4.顔検出
● Viola と Jones による手法が有名
● 詳細は省略
● 「あー, あれね, Haar-like 特徴と AdaBoost で
Attentional Cascade だよね」とか言えば
知ったかぶりできる
hc = cv2.cv.Load("haarcascade_frontalface_alt.xml")
storage = cv2.cv.CreateMemStorage()
img = cv2.imread('person.jpg')
faces = cv2.cv.HaarDetectObjects(img, hc, storage)
Python/OpenCV を使えば
一瞬で計算可能
[http://www.name-
list.net/img/images.ph
p/Linewih_5.jpg]
- 18.
2. 1. 2.システム概要(再掲)
● データベースの構築
1. DMM. R18 からAVのサンプ
ル画像を取得(16万タイトル
170万枚)
2. 画像群から顔検出して保存
(35万枚)
3. 特徴抽出 (2.5GB)
4. 主成分分析で圧縮 (70MB)
5. 保存
● 検索
1. 入力画像から顔検出
2. 特徴抽出
3. データベースを近傍探索
4. 結果をタイトルと合わせて表示
特徴抽出: 生データから推定や分析に有用な情報を抽出すること.
(ここでは「1枚の画像を何らかの方法で1本のベクトルに変換すること」)
主成分分析: データの冗長な部分を除いて次元を削減する手法.
近傍探索: 近くにあるデータを探すこと. 総当たりより効率的な方法がある.
顔検出: Viola & Jones の手法が有名.
- 19.
- 20.
3. 1. 画像補完[Hayset al., 07]
● 一部が欠損した画像を自動で補完
● GIST 特徴で類似画像検索 → ポワソン画像合成
● 大量の画像を用意するのがキモ (240万枚)
Retrieval
Input Retrieval Output
- 21.
- 22.
3. 2. 1.スケッチ検索[Shrivastava et al., 11]
1.クエリ画像から HOG を抽出
2.100万枚の画像と比較して画像特有の部分を算出
3.それを用いて近傍探索による検索を行う
- 23.
3. 2. 2.スケッチ検索 [Zhou et al., 12]
● スケッチ検索に適した特徴量を提案
- 24.
3. 2. 2.スケッチ検索 [Zhou et al., 12]
● 縦, 横, 斜めの線がどこにどれだけあるか
● 画像中のどこが重要か (←線が密集してるところ)
- 25.
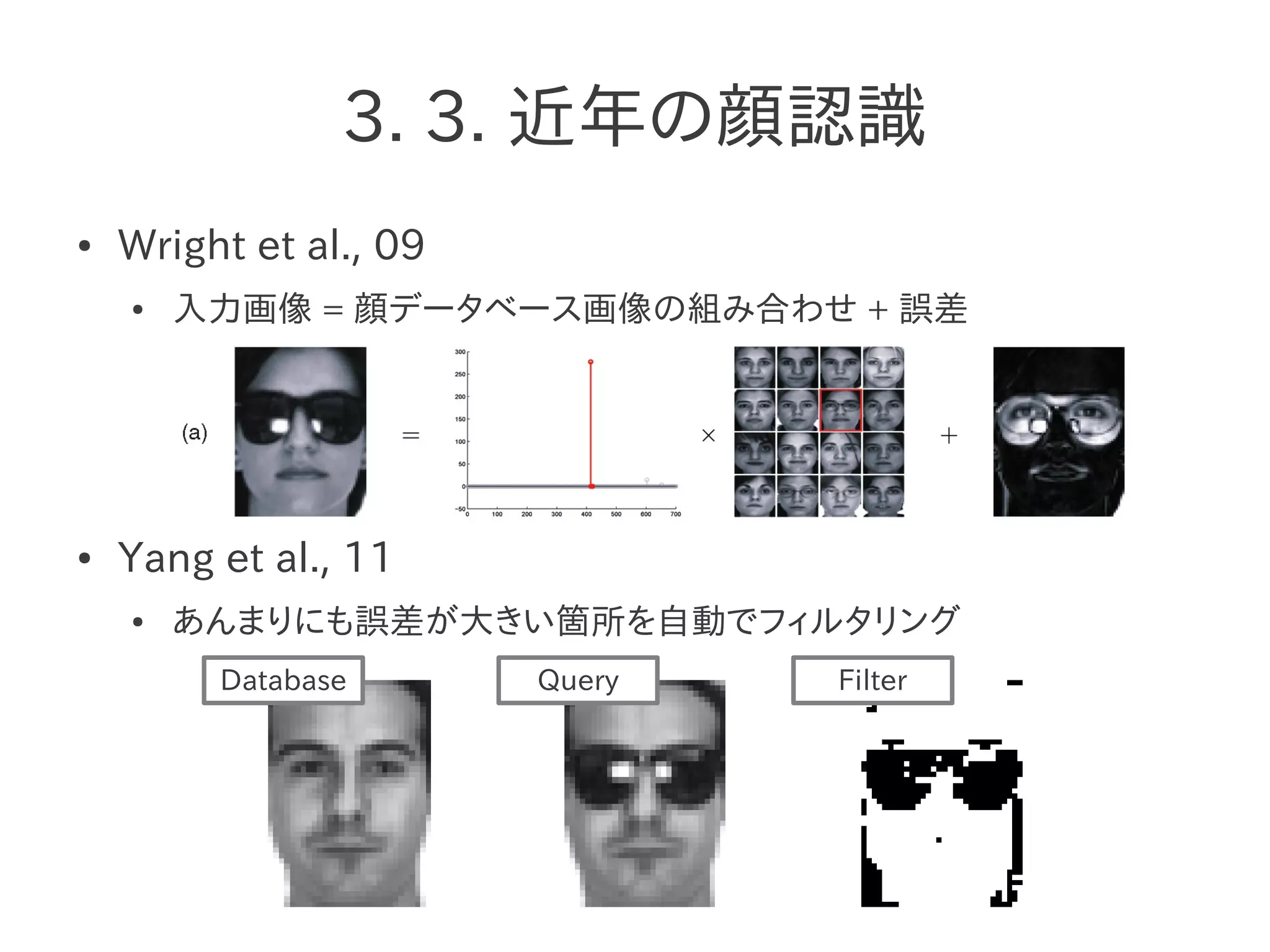
3. 3. 近年の顔認識
●Wright et al., 09
● 入力画像 = 顔データベース画像の組み合わせ + 誤差
● Yang et al., 11
● あんまりにも誤差が大きい箇所を自動でフィルタリング
Database Query Filter
- 26.
3. 4. 補足:画像認識とは
● 画像認識とは, 画像を識別 classification すること
● 手書き文字認識, 顔認識, シーン認識, 一般物体認識, ...
● 画像認識は機械学習を伴うことが多い
● 顔認識: 大量の顔画像の特徴量から「顔の特徴量らしさ」を学習
● 今回の AV 検索は画像認識なのか微妙
● 画像を16万タイトルのどれかに classification する問題
● 近傍探索しているだけであり機械学習していない
– 機械学習するにはデータ数が不足
- 27.
4. まとめ
● 内容のまとめ
●AV 類似顔画像検索ツールを題材として
コンピュータビジョンの初歩の一部を紹介した
● ついでに関連する研究も少しだけ紹介した
● 伝えたかったこと
● 画像のシンプルな取り扱いでこれくらいはできるよということ
● OpenCV/Python/NumPy/SciPy を使うと楽だよということ
● もう少しこういうスタートアップあってもいいよねということ
● お詫び
● もう少し体系的な話のほうがよかったのかな
- 28.













![2. 2. 1. 特徴抽出
● 画像そのままでは扱いづらい
● たとえば類似性はどう判断しよう? -> 全体の色合いを比べるとか?
– 左の画像は 縦22px * 横22px * 3色 = 1,452次元のデータ
– これを [赤, 緑, 青] = [0.2, 0.8, 0] と変換すれば3次元のデータに
● いろんな特徴量が提案されている
– 大域特徴: Color Histogram, HOG, GIST, HLAC, ...
– 局所特徴: SIFT, SURF, LBP, BRIEF, ...
– 局所特徴のコーディング: Bog of Features, Fischer Vector, …
– 今回は HOG を利用](https://image.slidesharecdn.com/usg-130209000936-phpapp02/75/AV-UT-Startup-Gym-13-2048.jpg)
![2. 2. 1. 特徴抽出
● HOG (Histogram of Oriented Gradients) [Dalal et al., 05]
● 画像をグリッドで区切って
それぞれで明るさの勾配の
ヒストグラムを計算
● 今回のシステムでは顔画像が
1,764次元のベクトルに
hog = cv2.HOGDescriptor((64, 64), (16, 16), (8, 8), (8, 8), 9)
img = cv2.imread('face.jpg')
h = hog.compute(img)
Python/OpenCV を使えば
一瞬で計算可能](https://image.slidesharecdn.com/usg-130209000936-phpapp02/75/AV-UT-Startup-Gym-14-2048.jpg)
![2. 2. 2. 主成分分析
● あんま意味のない次元を削る (荒っぽい解釈)
● データ量の削減, 「次元の呪い」の回避
● 今回のシステムでは1,764次元 → 100次元に削減
[http://www.nlpca.org/]
pca = sklearn.decomposition.PCA(dim)
r = pca.fit_transform(data);
Python/SciKits を使えば
一瞬で計算可能](https://image.slidesharecdn.com/usg-130209000936-phpapp02/75/AV-UT-Startup-Gym-15-2048.jpg)
![2. 2. 3. 近傍探索
● この画像はどの画像と近いか?
→ この画像の特徴ベクトルはどの画像の特徴ベクトルと近いか?
→ ベクトル空間上での距離を見ればいい (今回の実装)
● 普通に総当たりでやってもいい
● が, もっと早い方法がいくつか提案されている
● 今回は FLANN [Muja et al., 09] を使用
[http://www.emeraldinsight.com/cont
ent_images/fig/0870280310006.png]
index = cv2.flann_Index(features, {"algorithm":0})
idx, dist = index.knnSearch(data, n, params={})
Python/OpenCV を使えば
一瞬で計算可能](https://image.slidesharecdn.com/usg-130209000936-phpapp02/75/AV-UT-Startup-Gym-16-2048.jpg)
![2. 2. 4. 顔検出
● Viola と Jones による手法が有名
● 詳細は省略
● 「あー, あれね, Haar-like 特徴と AdaBoost で
Attentional Cascade だよね」とか言えば
知ったかぶりできる
hc = cv2.cv.Load("haarcascade_frontalface_alt.xml")
storage = cv2.cv.CreateMemStorage()
img = cv2.imread('person.jpg')
faces = cv2.cv.HaarDetectObjects(img, hc, storage)
Python/OpenCV を使えば
一瞬で計算可能
[http://www.name-
list.net/img/images.ph
p/Linewih_5.jpg]](https://image.slidesharecdn.com/usg-130209000936-phpapp02/75/AV-UT-Startup-Gym-17-2048.jpg)


![3. 1. 画像補完[Hays et al., 07]
● 一部が欠損した画像を自動で補完
● GIST 特徴で類似画像検索 → ポワソン画像合成
● 大量の画像を用意するのがキモ (240万枚)
Retrieval
Input Retrieval Output](https://image.slidesharecdn.com/usg-130209000936-phpapp02/75/AV-UT-Startup-Gym-20-2048.jpg)
![3. 1. 画像補完[Hays et al., 07]
Before Clip After](https://image.slidesharecdn.com/usg-130209000936-phpapp02/75/AV-UT-Startup-Gym-21-2048.jpg)
![3. 2. 1. スケッチ検索[Shrivastava et al., 11]
1.クエリ画像から HOG を抽出
2.100万枚の画像と比較して画像特有の部分を算出
3.それを用いて近傍探索による検索を行う](https://image.slidesharecdn.com/usg-130209000936-phpapp02/75/AV-UT-Startup-Gym-22-2048.jpg)
![3. 2. 2. スケッチ検索 [Zhou et al., 12]
● スケッチ検索に適した特徴量を提案](https://image.slidesharecdn.com/usg-130209000936-phpapp02/75/AV-UT-Startup-Gym-23-2048.jpg)
![3. 2. 2. スケッチ検索 [Zhou et al., 12]
● 縦, 横, 斜めの線がどこにどれだけあるか
● 画像中のどこが重要か (←線が密集してるところ)](https://image.slidesharecdn.com/usg-130209000936-phpapp02/75/AV-UT-Startup-Gym-24-2048.jpg)