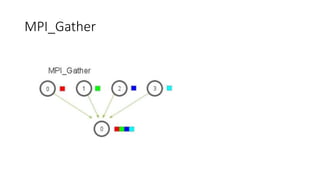
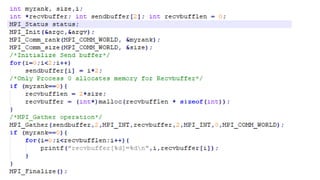
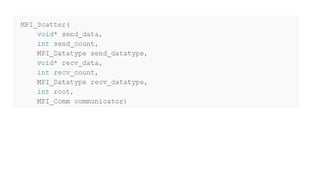
MPI collective communication routines like MPI_Allreduce, MPI_Gather, and MPI_Scatter allow processes in parallel programs to share data. MPI_Allreduce combines data from all processes using a reduction operation like sum or max. MPI_Gather collects portions of a send buffer from each process into a receive buffer. MPI_Scatter distributes different chunks of an array from a root process to other processes. Exercises demonstrate changing data and testing these routines work correctly across processes.


![MPI_Allreduce • MPI_Allreduce is the equivalent of
doing MPI_Reduce followed by an MPI_Bcast
MPI_Reduce vs MPI_AllReduce
[Source]: https://mpitutorial.com/tutorials/mpi-reduce-and-allreduce/](https://image.slidesharecdn.com/mpicollectivecommunicationoperations-200309024343/85/Mpi-collective-communication-operations-2-320.jpg)







































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)

