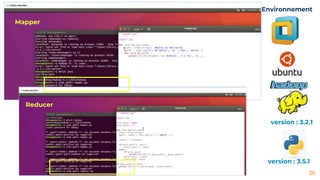
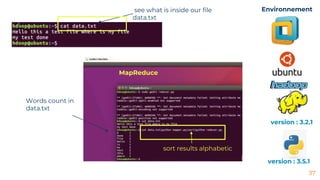
This document provides an introduction to MapReduce programming model. It describes how MapReduce inspired by Lisp functions works by dividing tasks into mapping and reducing parts that are distributed and processed in parallel. It then gives examples of using MapReduce for word counting and calculating total sales. It also provides details on MapReduce daemons in Hadoop and includes demo code for summing array elements in Java and doing word counting on a text file using the Hadoop framework in Python.

























![The ideas, concepts and diagrams are taken from the following websites:
● http://www.metz.supelec.fr/metz/personnel/vialle/course/BigData-2A-CS/poly-
pdf/Poly-chap6.pdf
● https://sites.cs.ucsb.edu/~tyang/class/240a17/slides/CS240TopicMapReduce.
pdf
● https://fr.slideshare.net/LiliaSfaxi/bigdatachp2-hadoop-mapreduce
● https://algodaily.com/lessons/what-is-mapreduce-and-how-does-it-work
[References]
39](https://image.slidesharecdn.com/mapreduce-230502111303-b2d199eb/85/map-Reduce-pptx-39-320.jpg)





























































