Download as ODP, PPTX




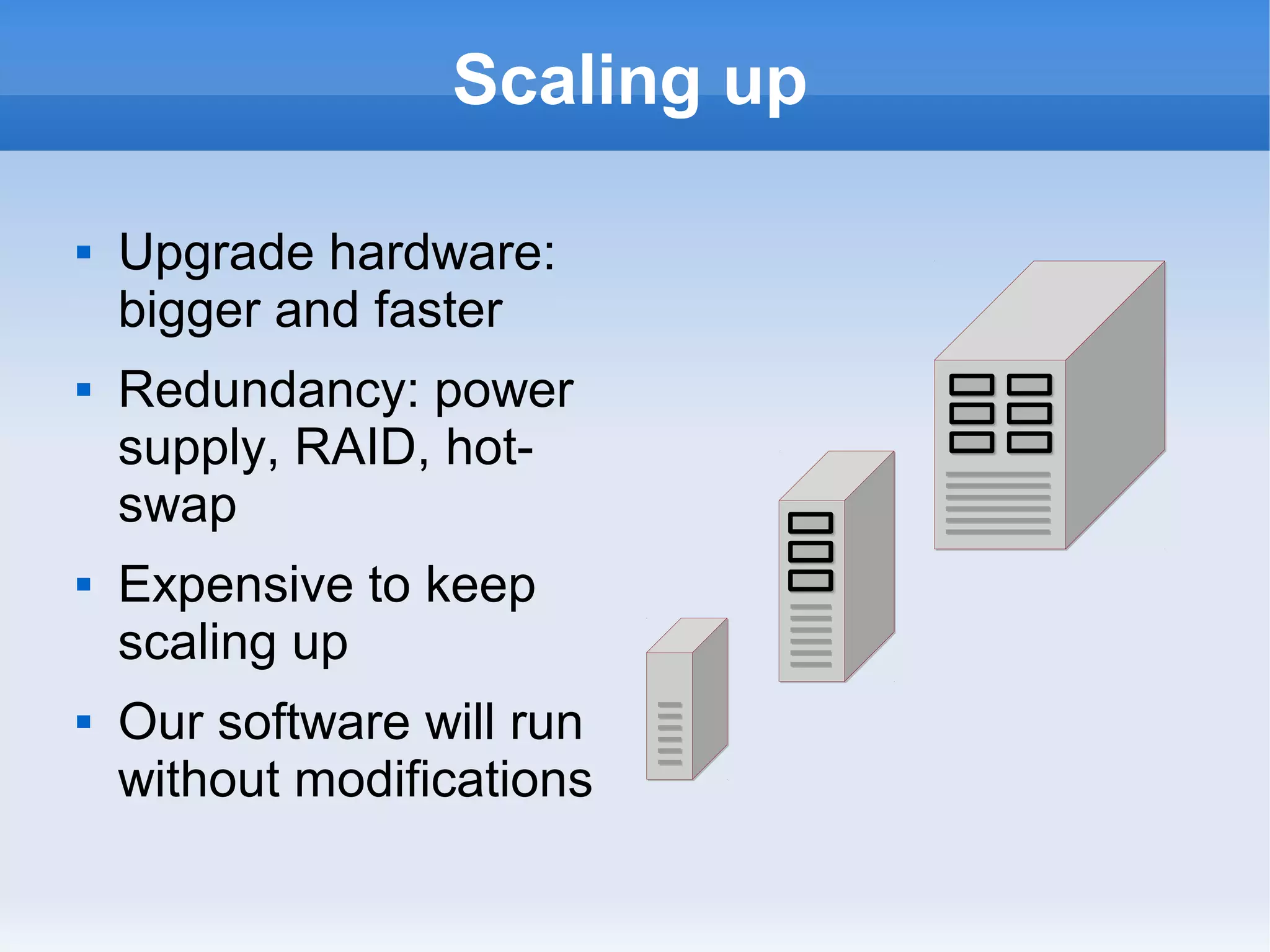








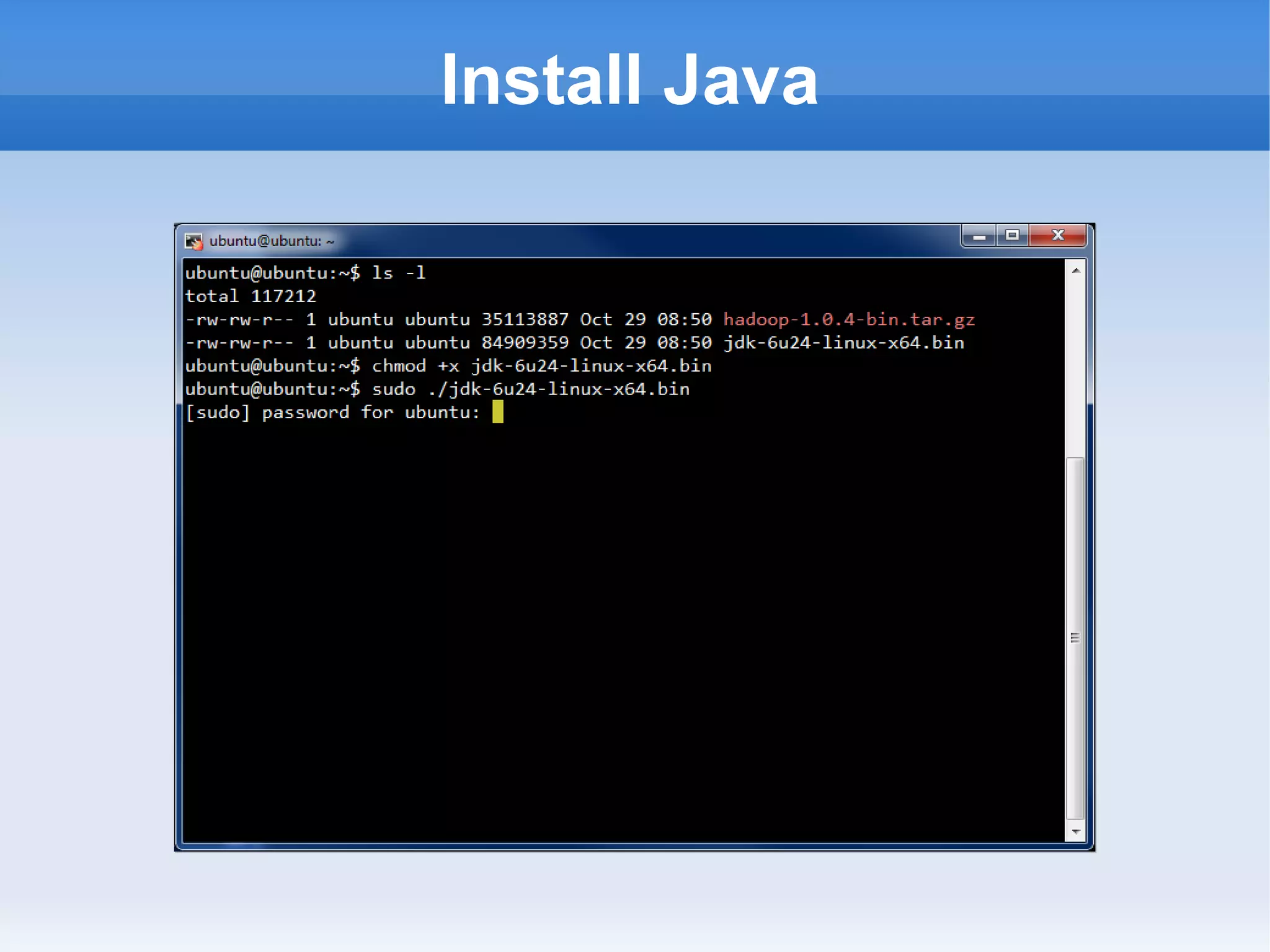
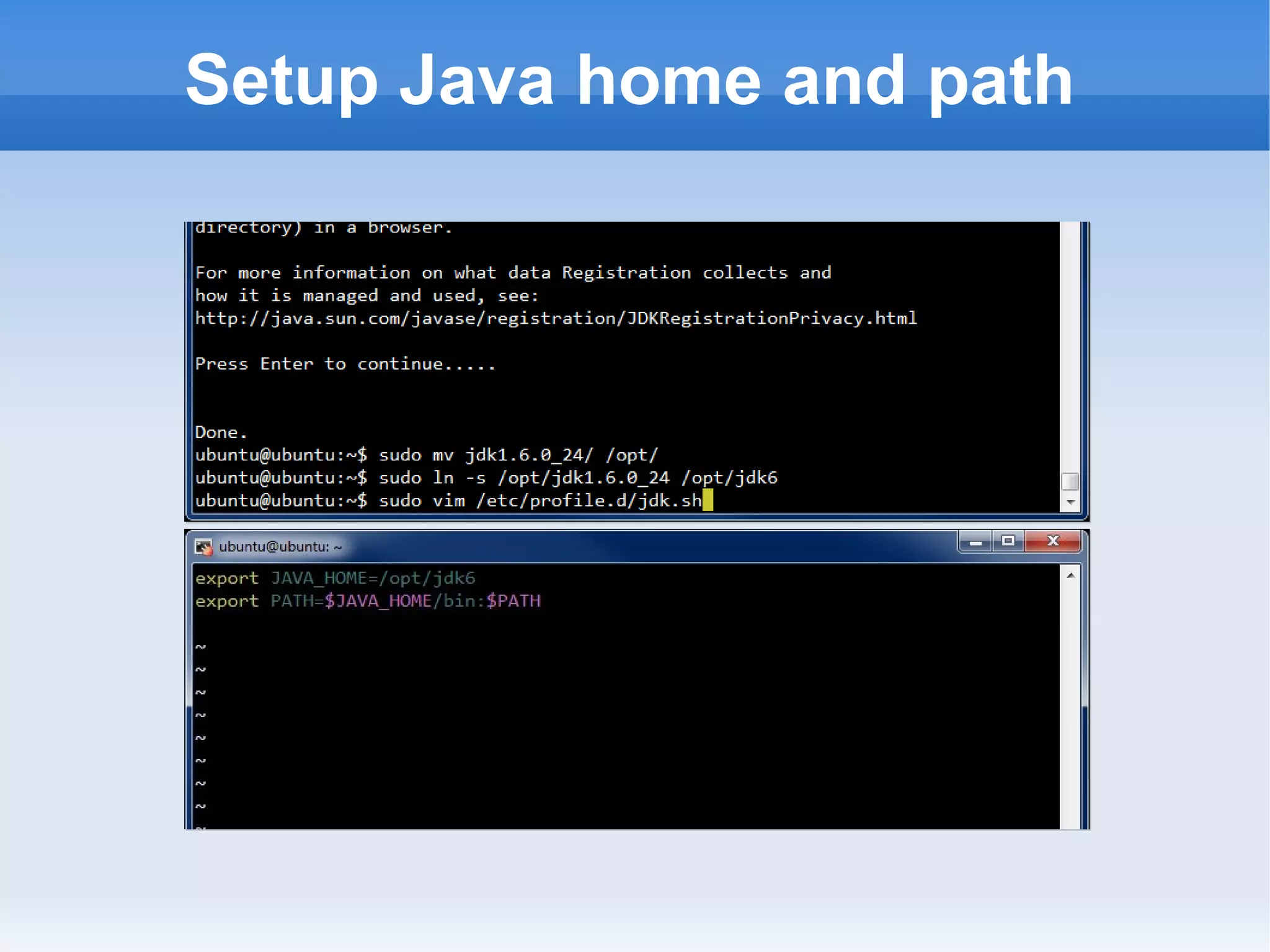
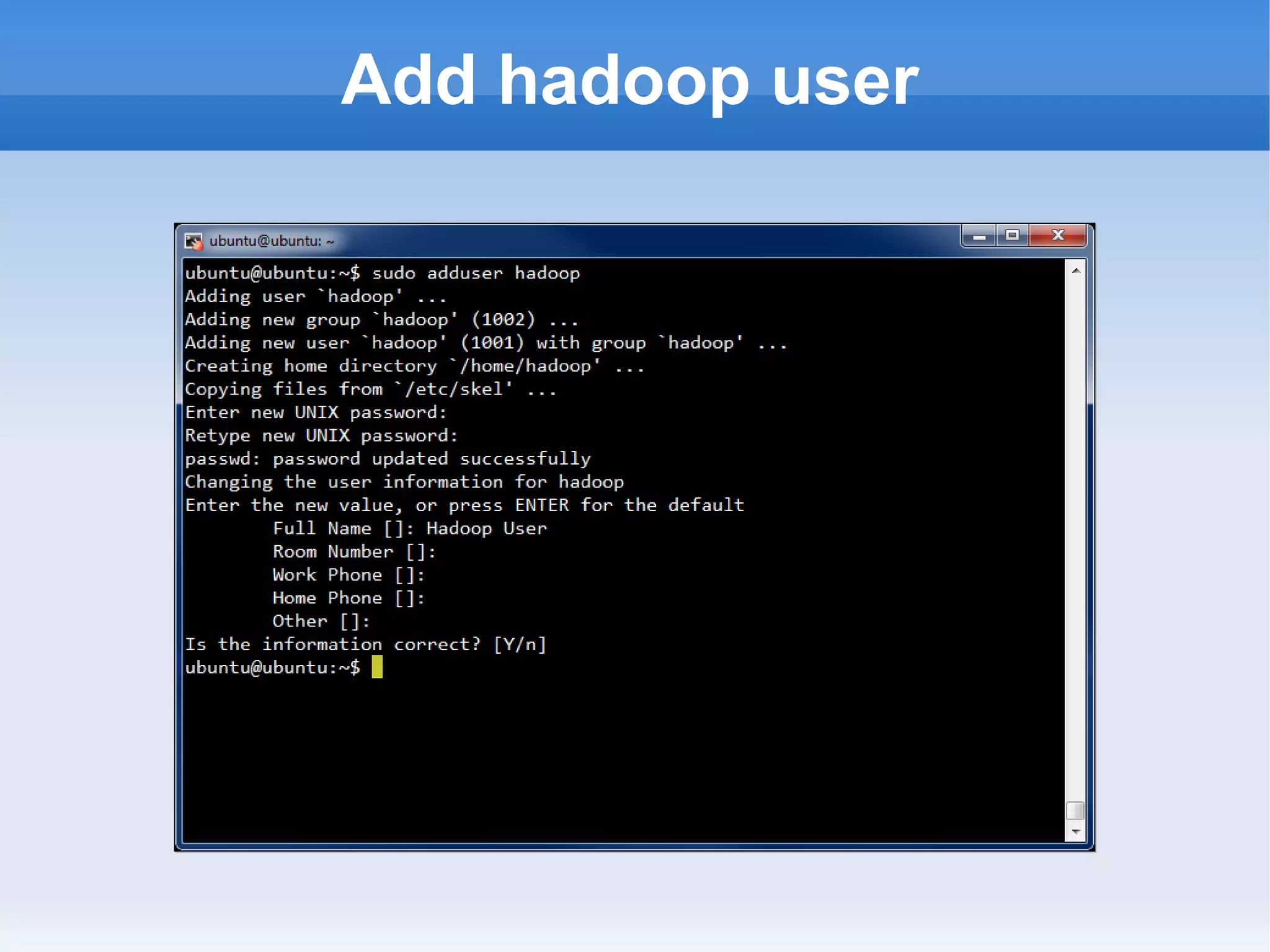
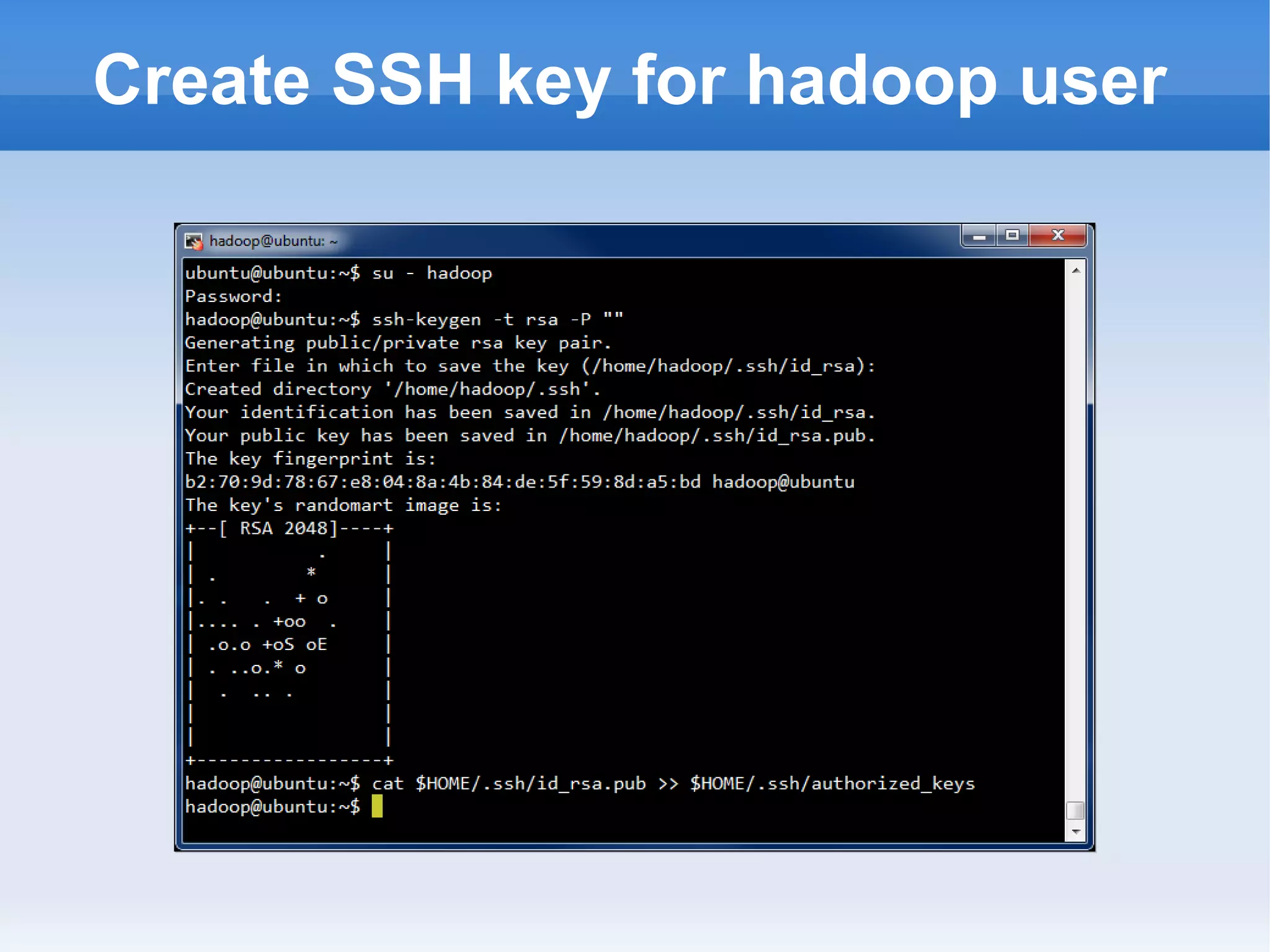
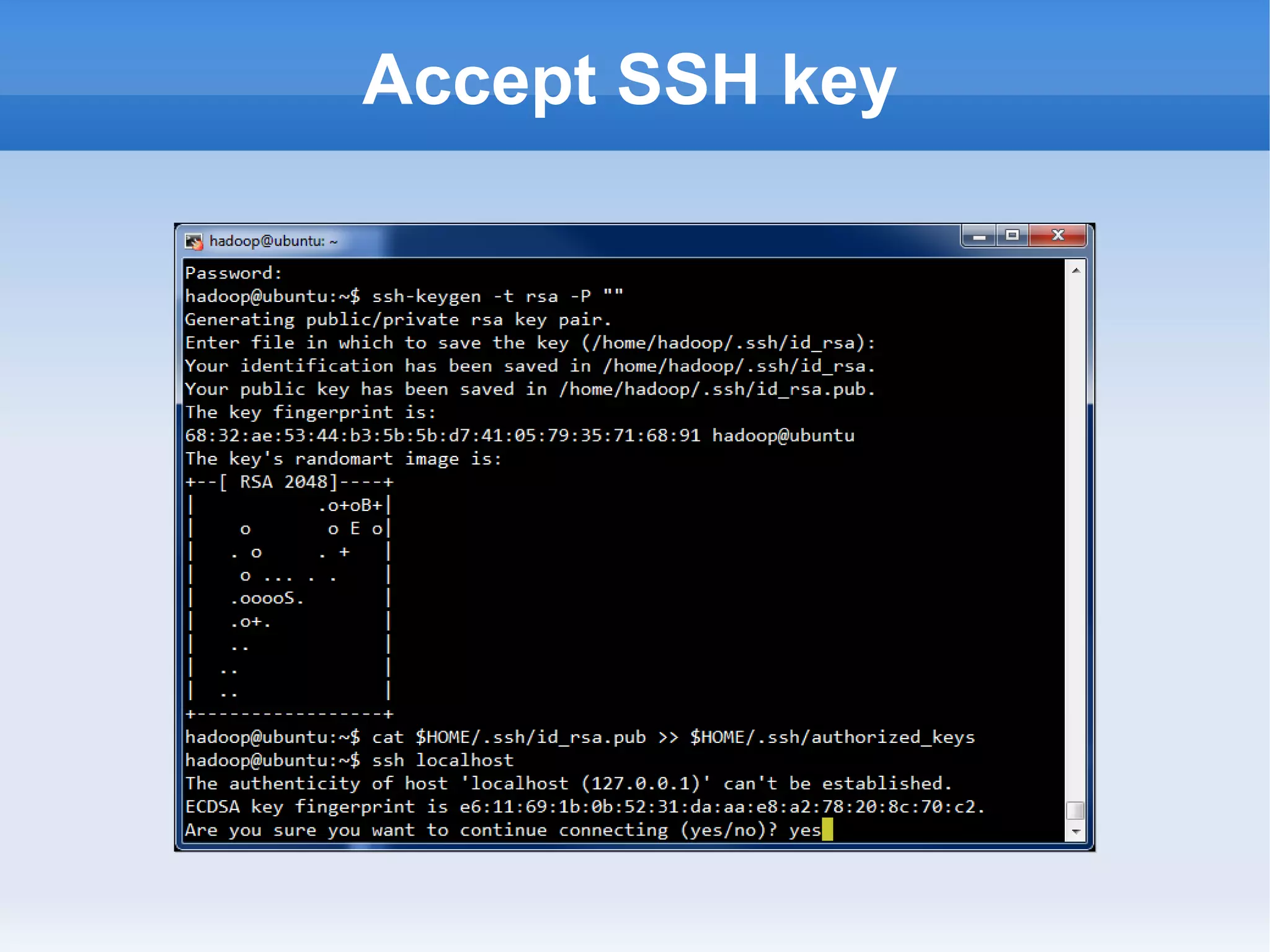
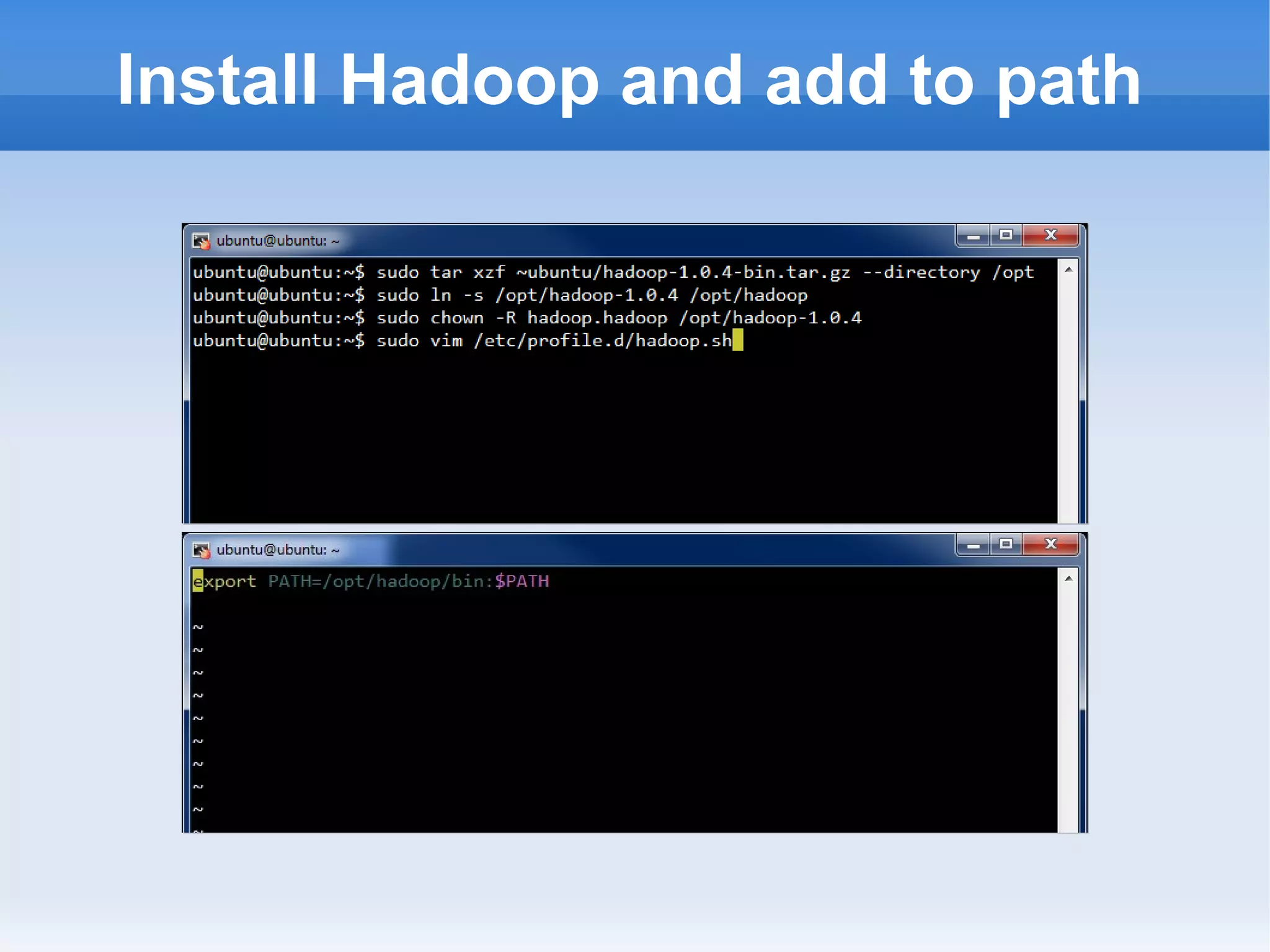
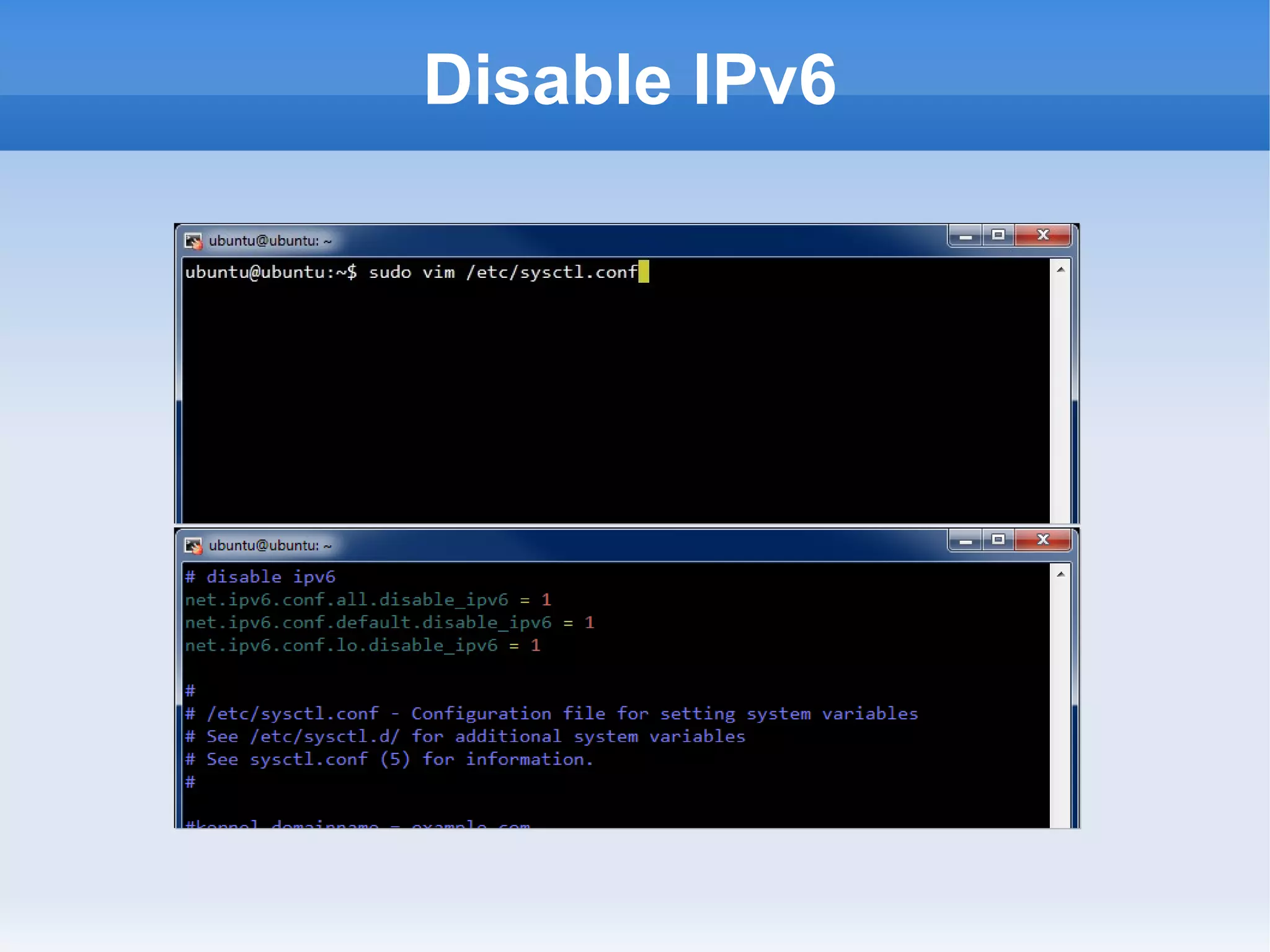
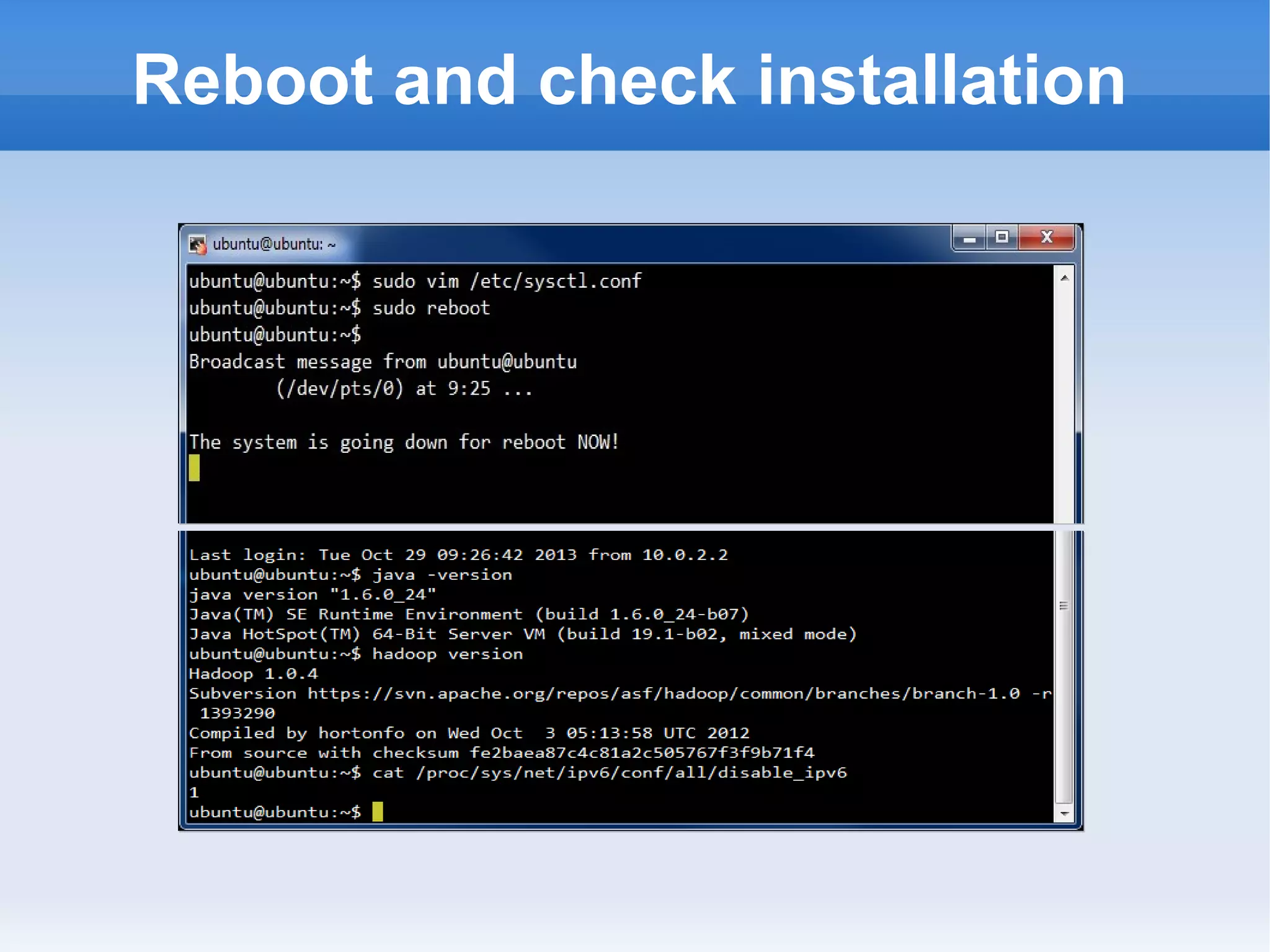

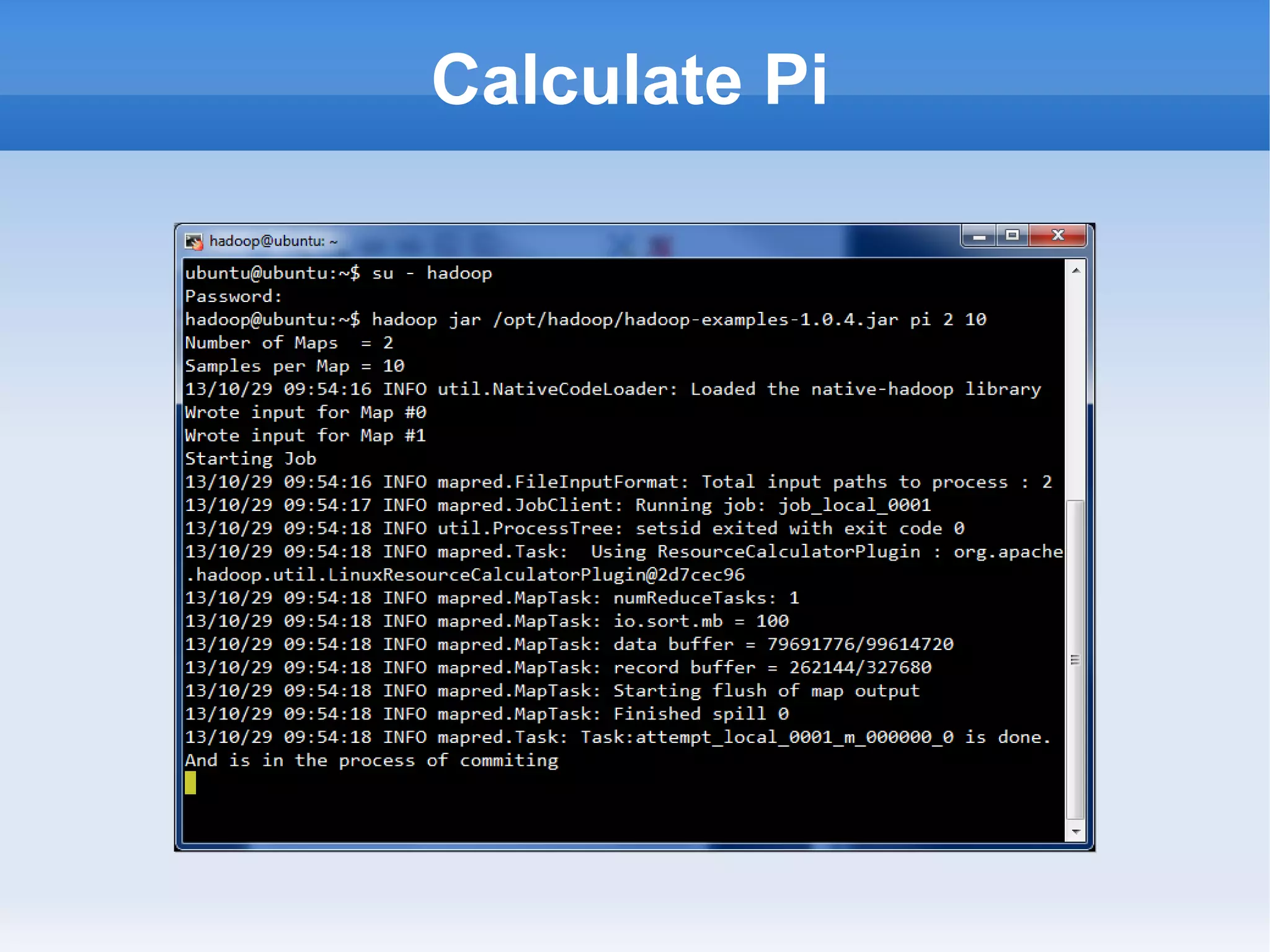
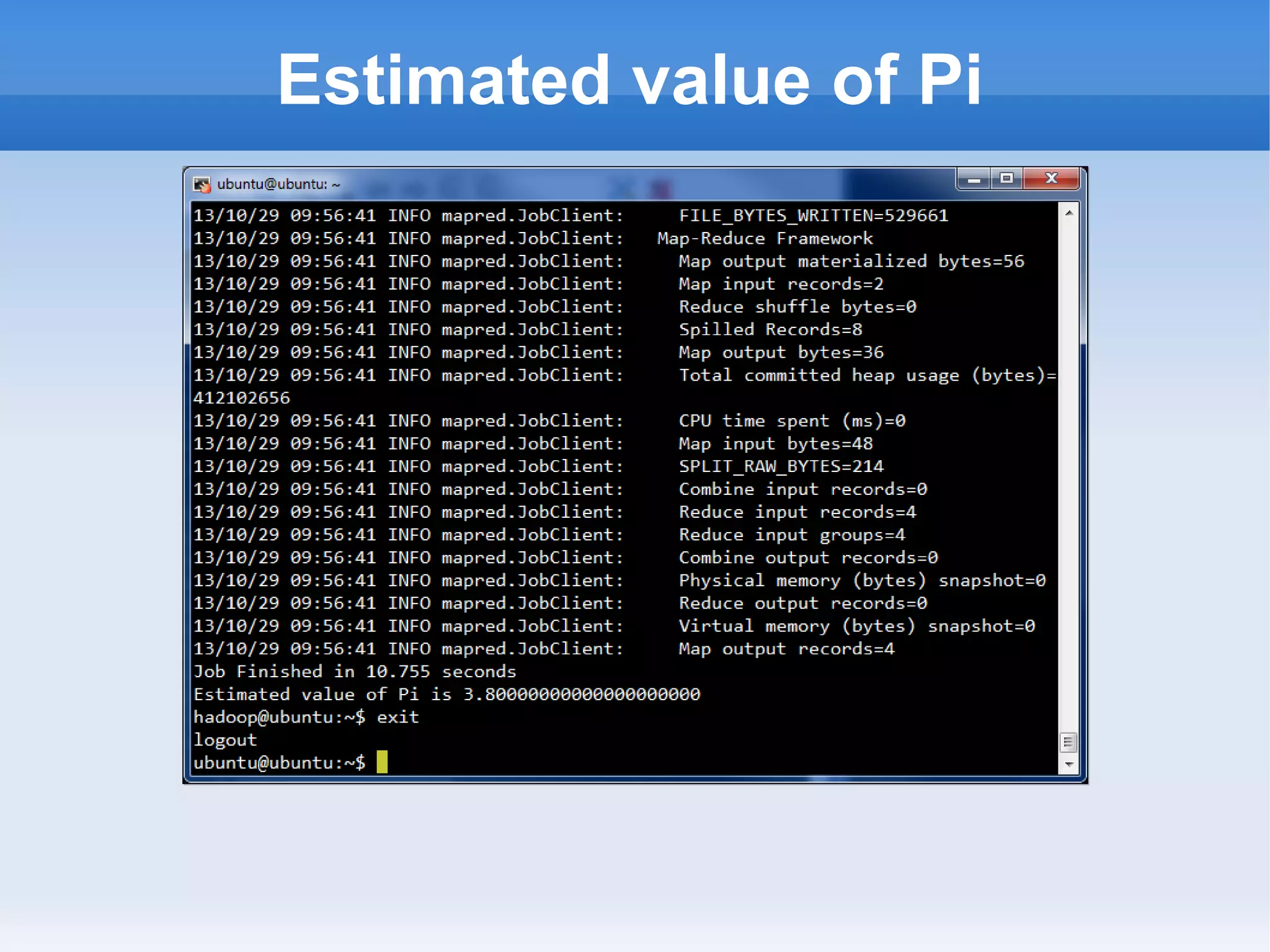

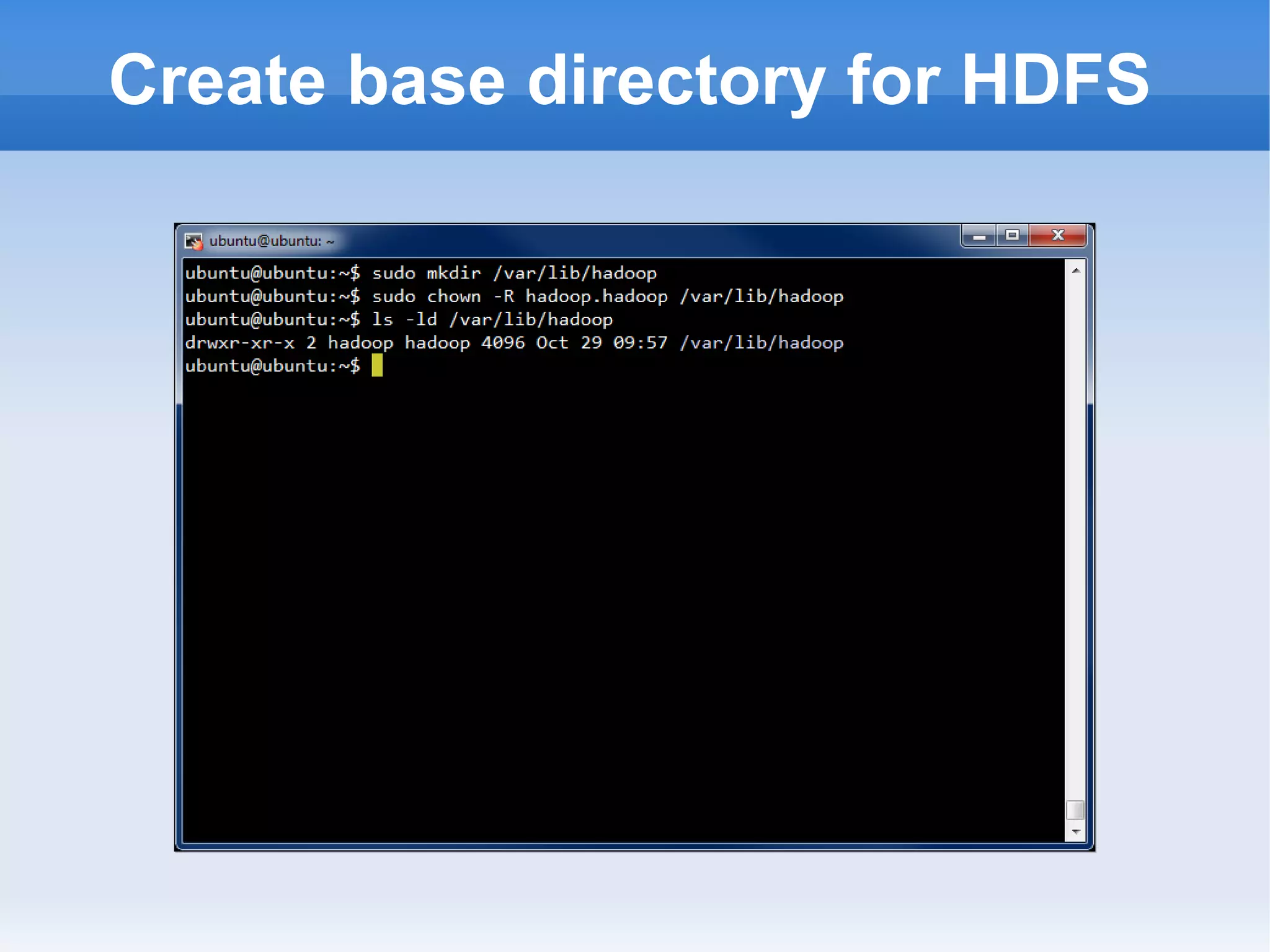
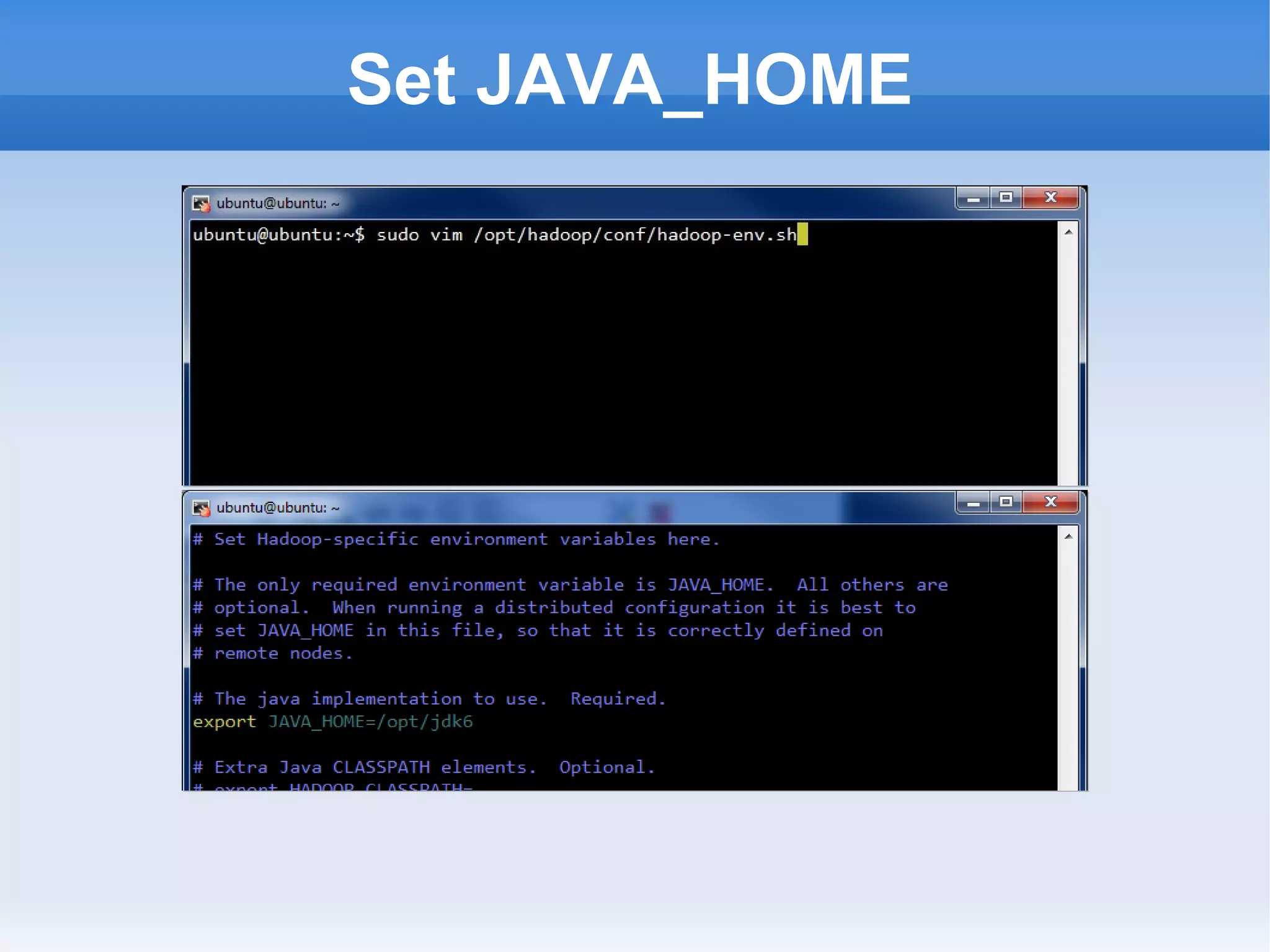
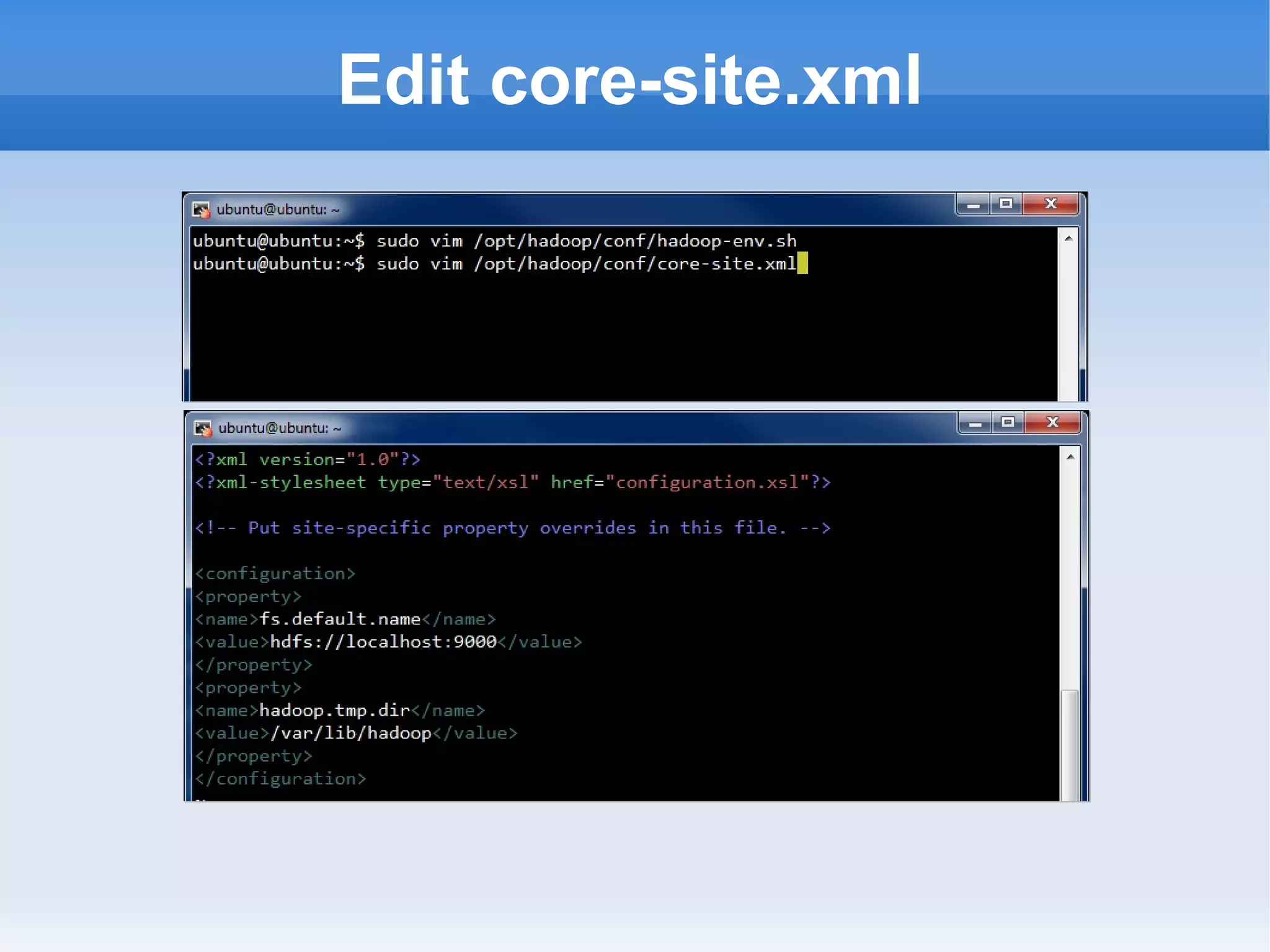
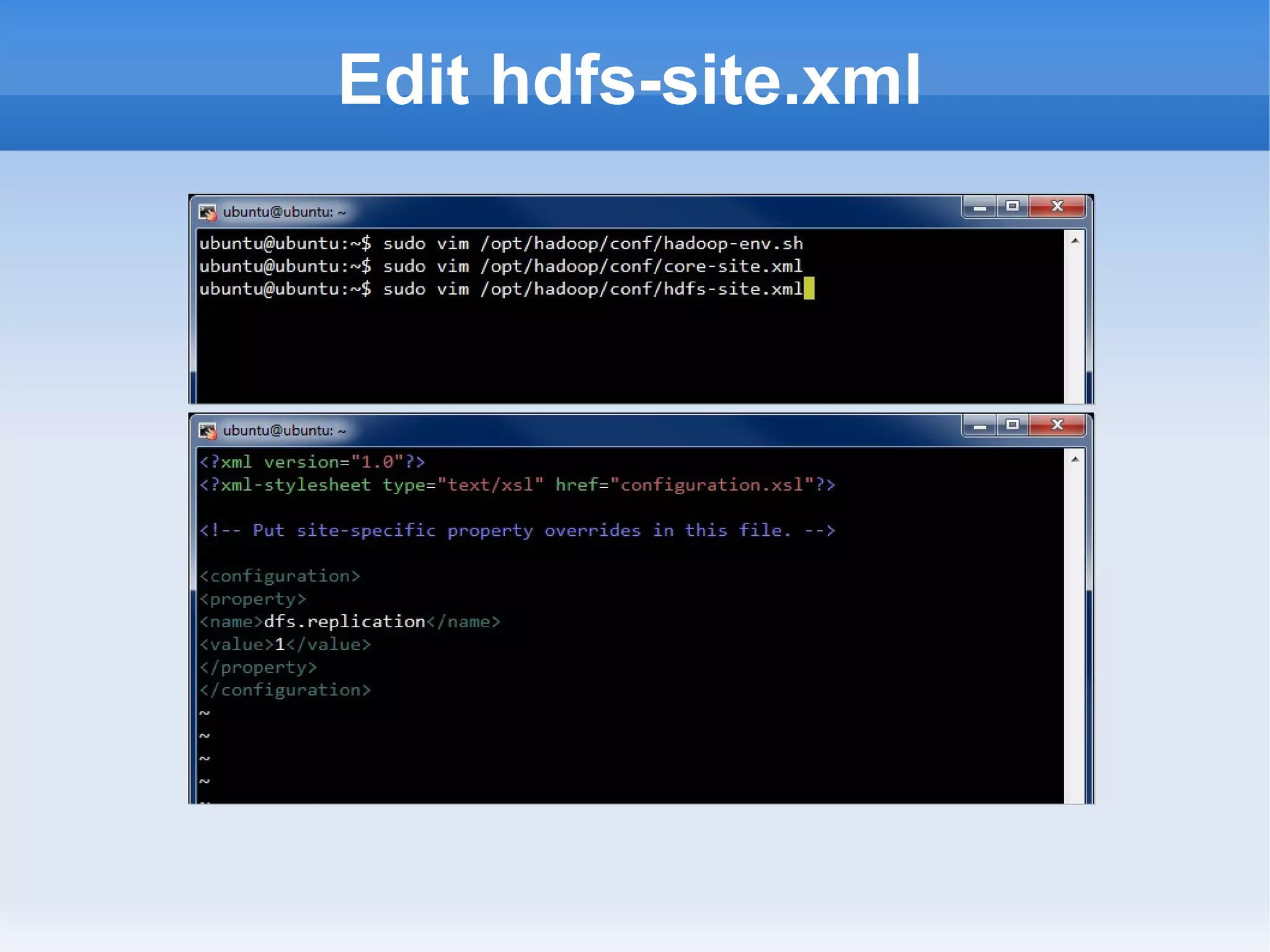
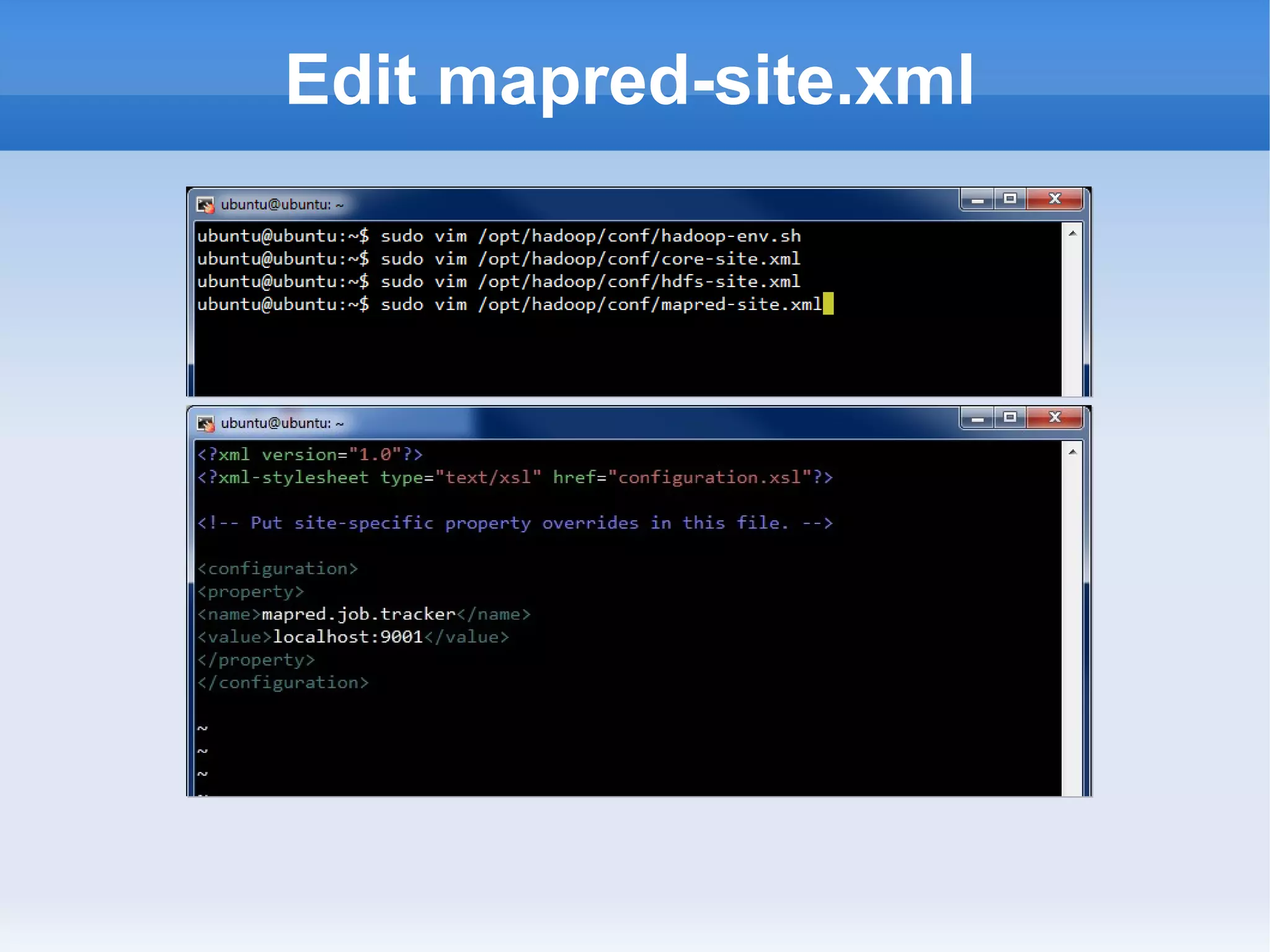
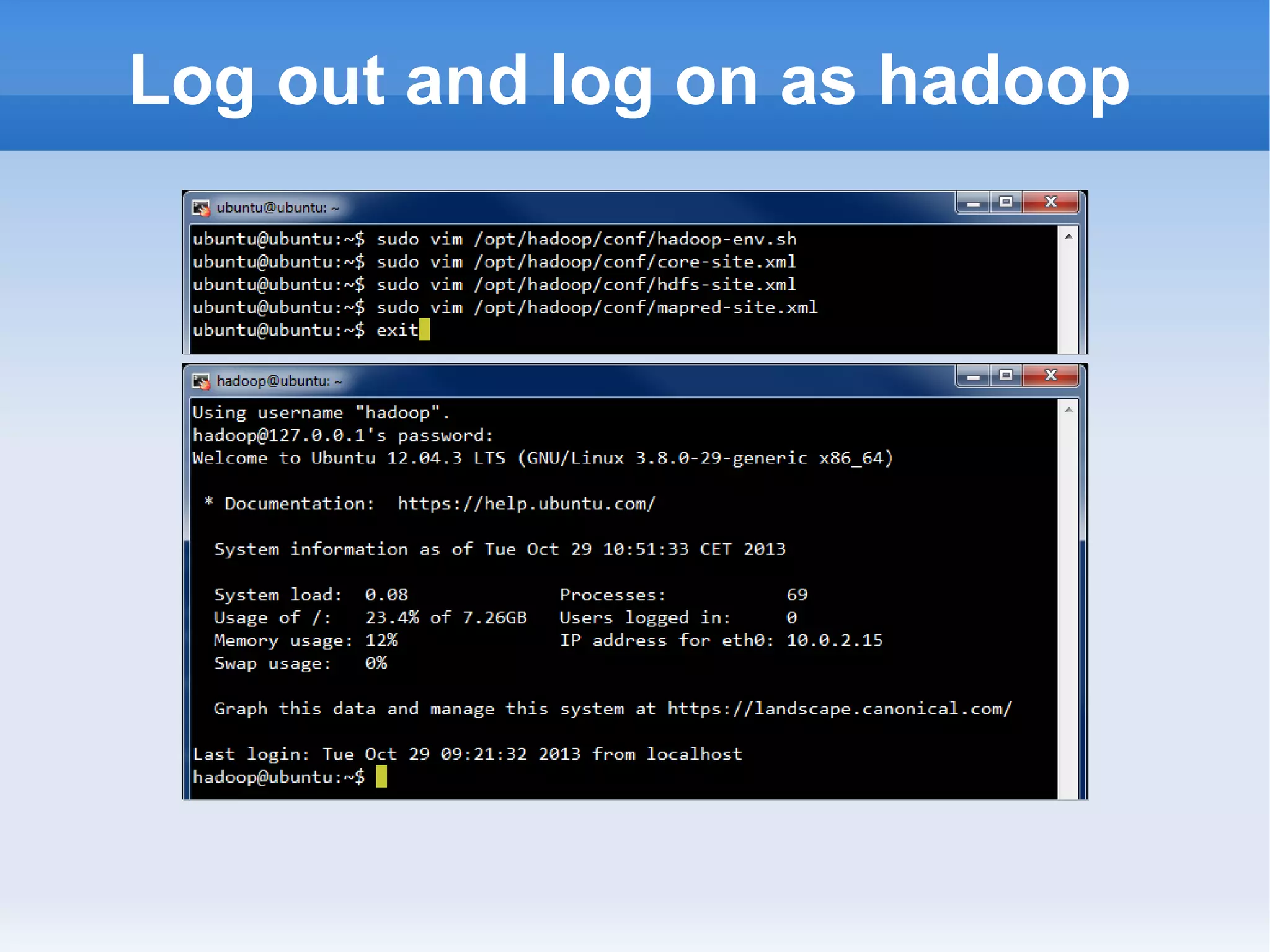
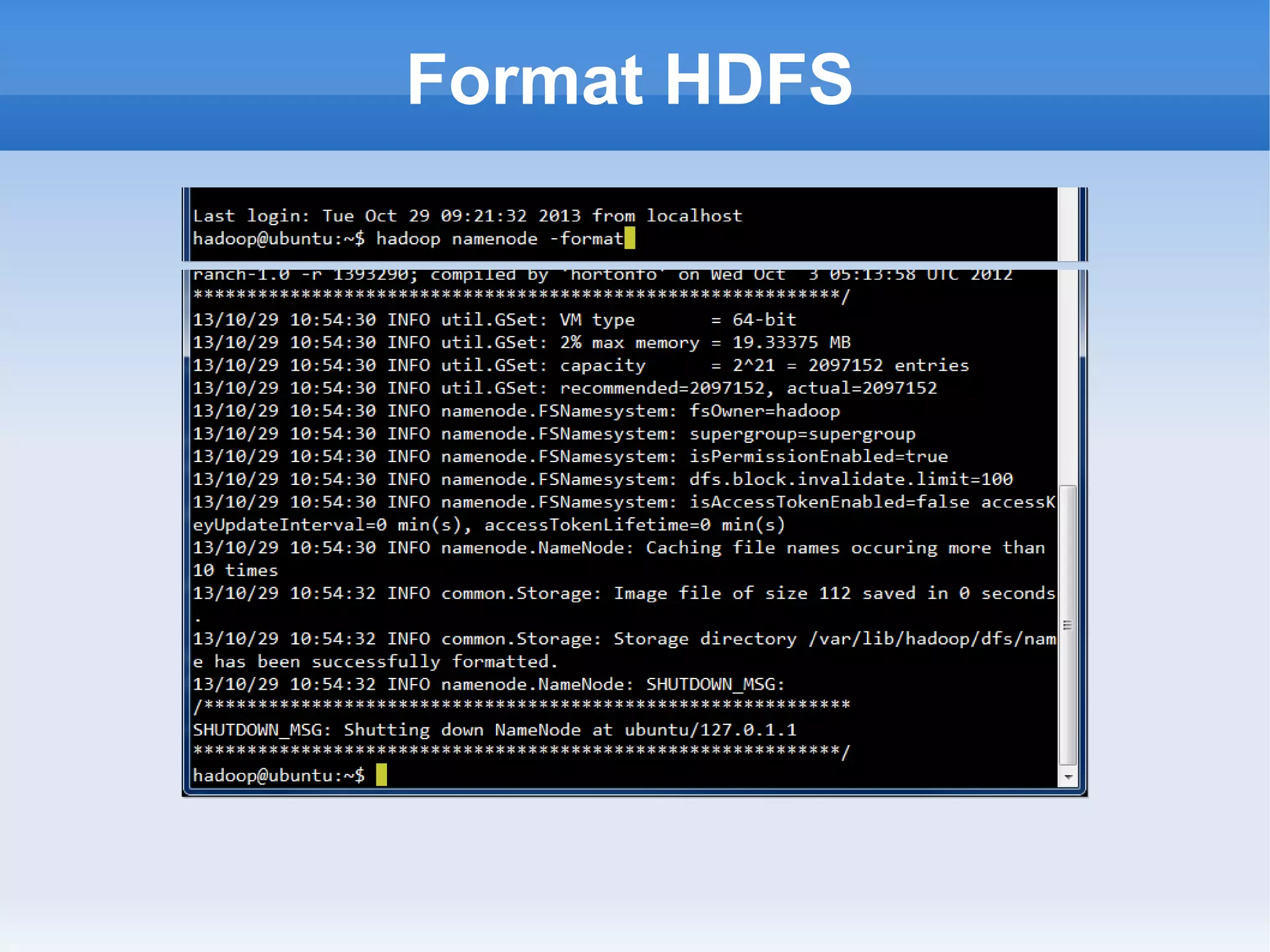
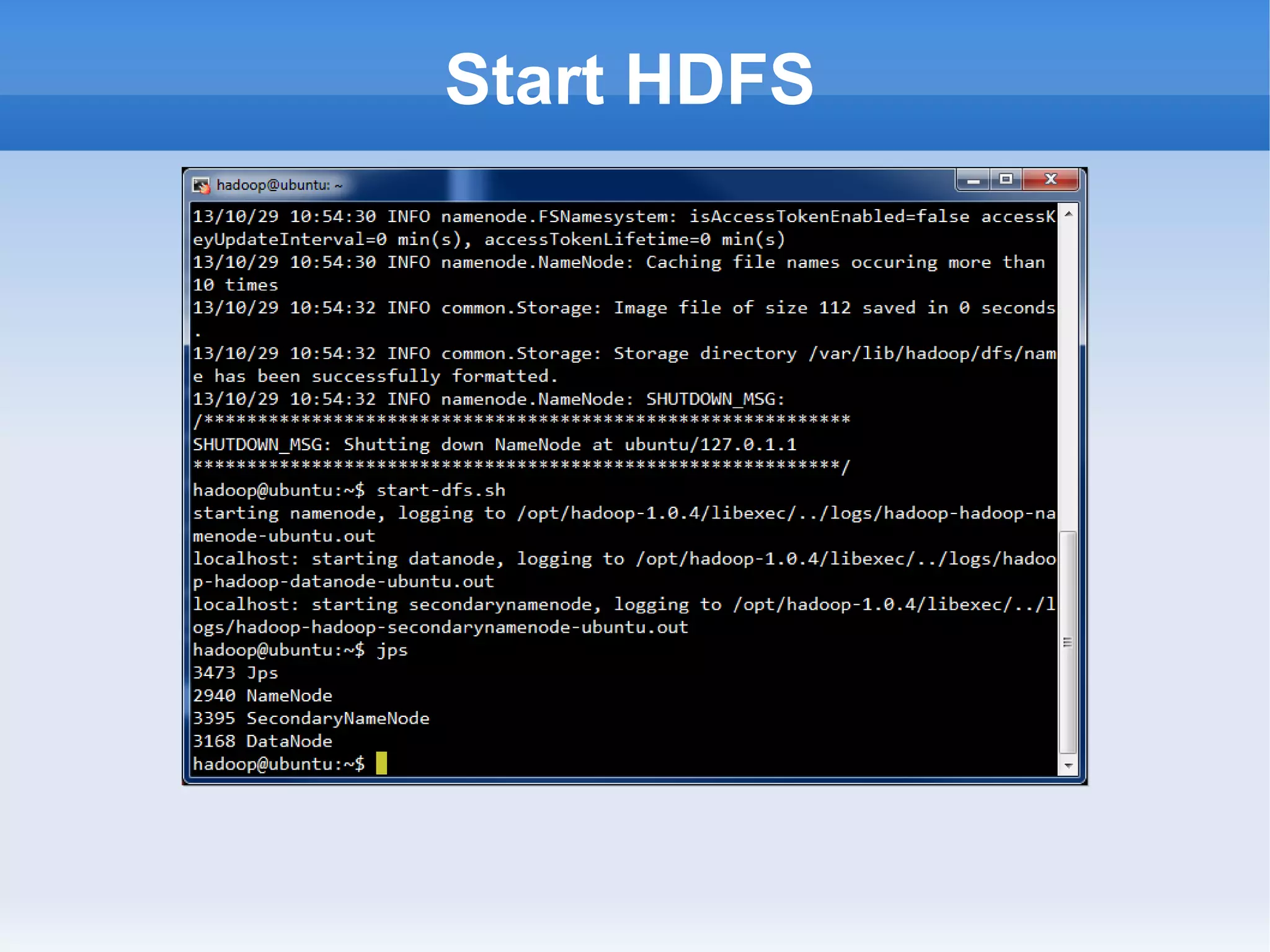
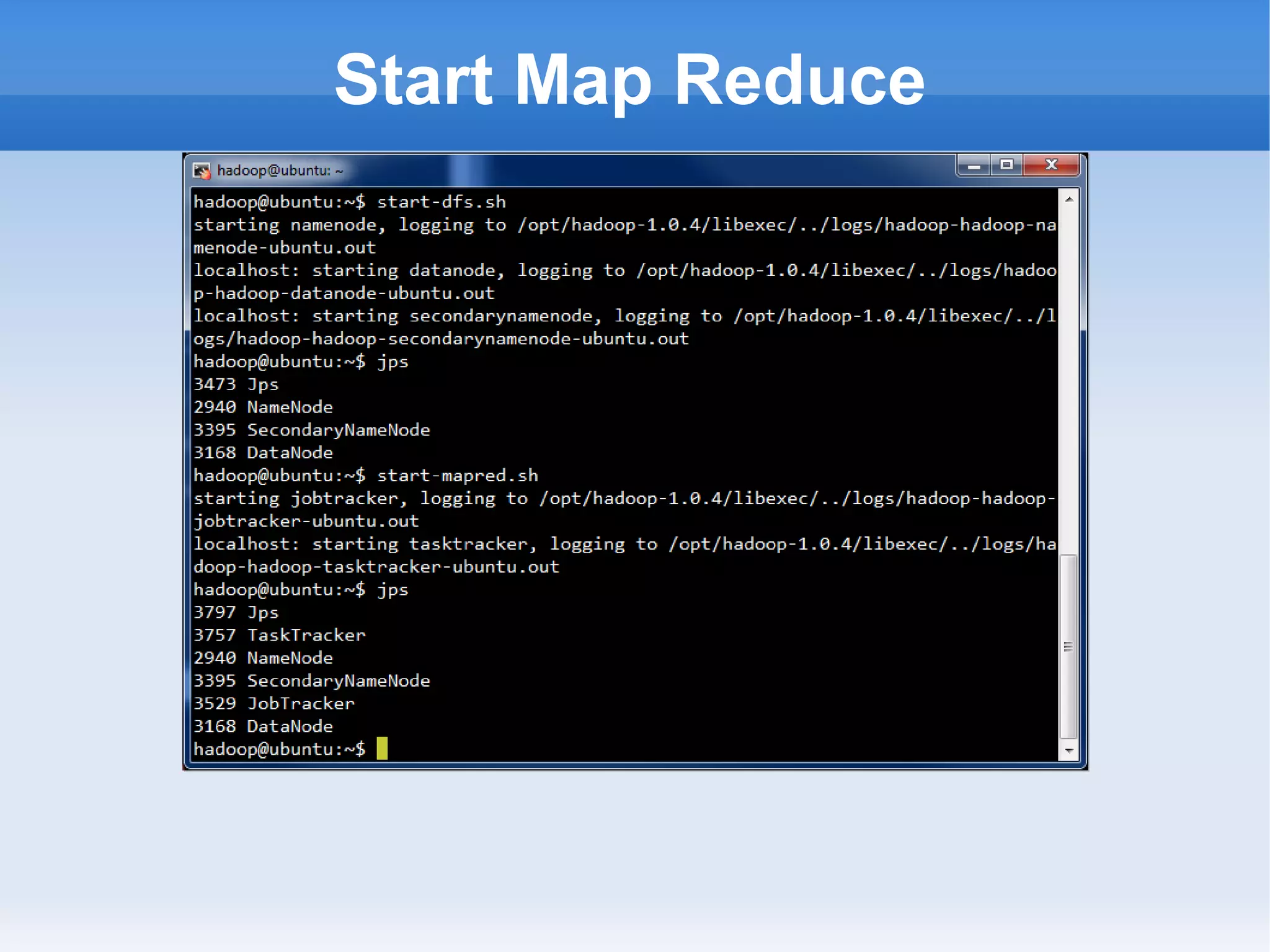
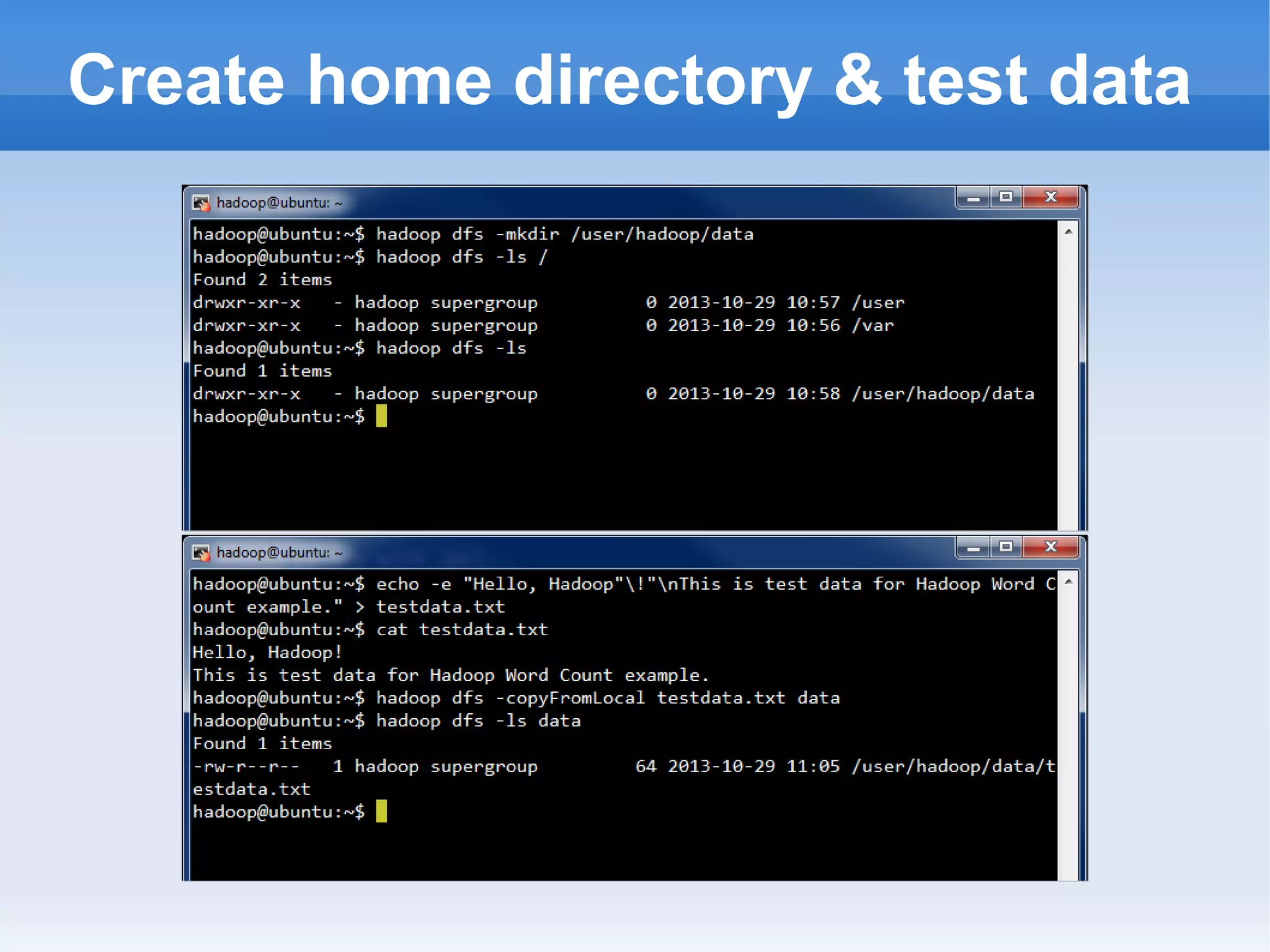
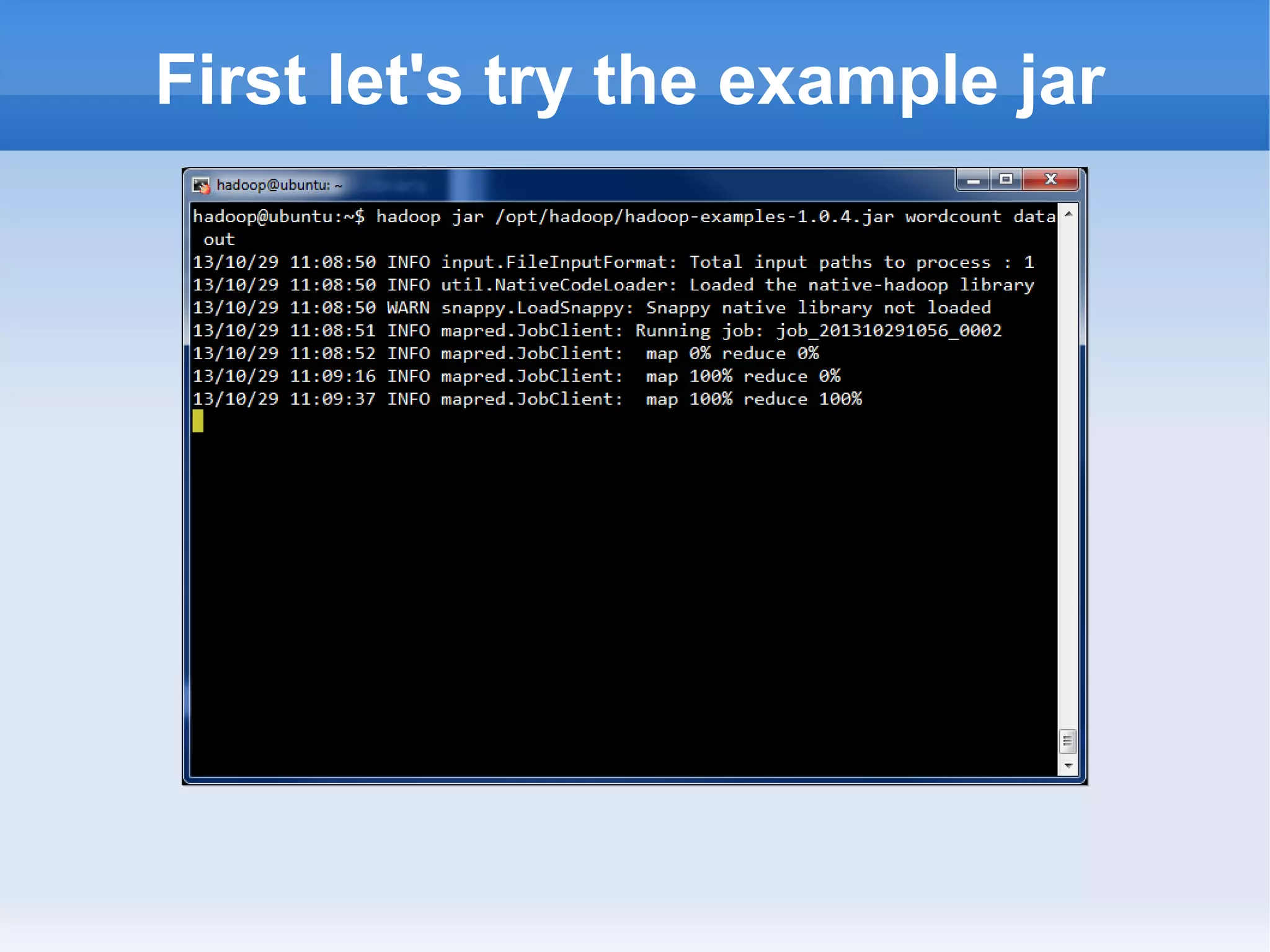
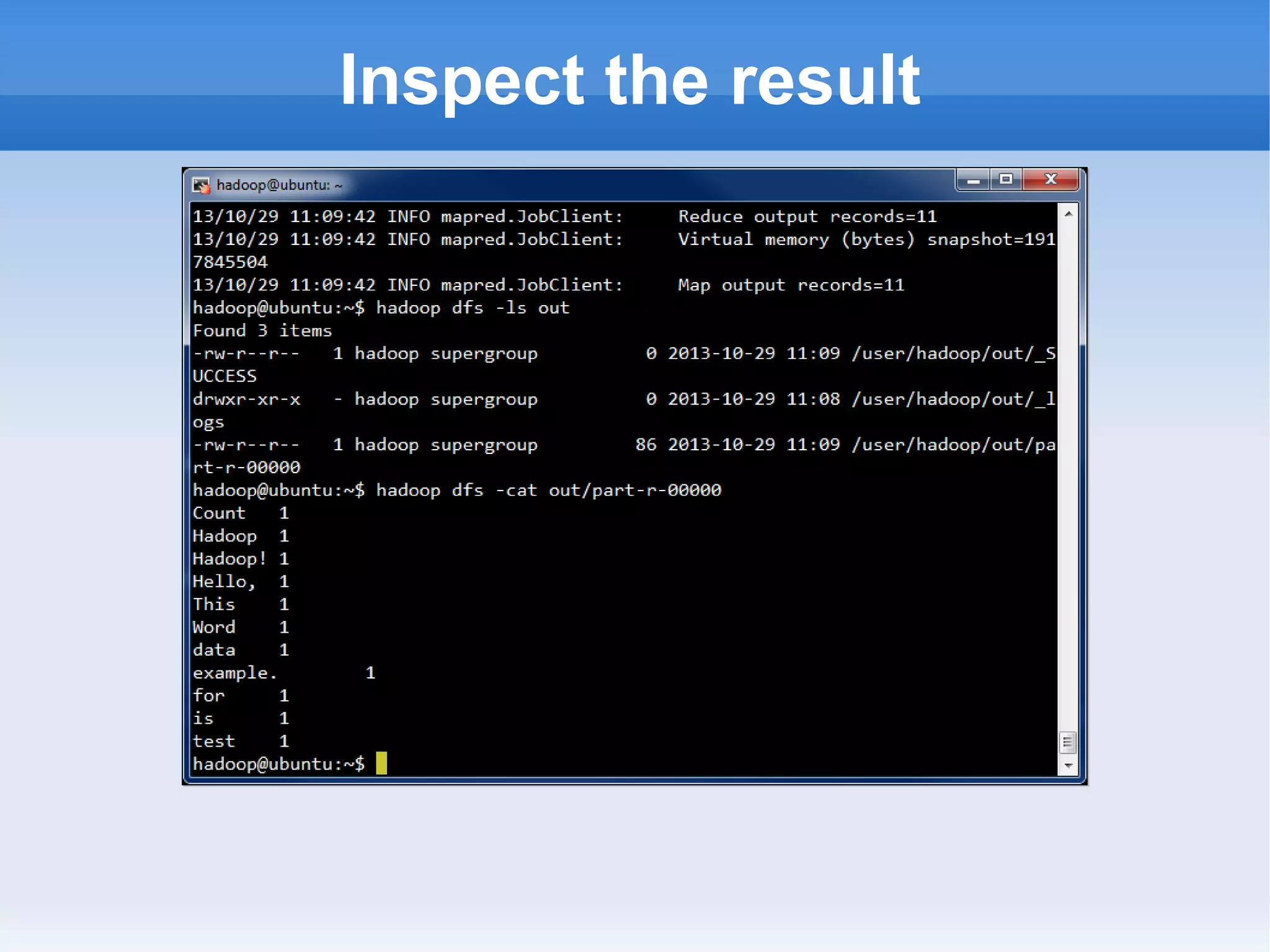
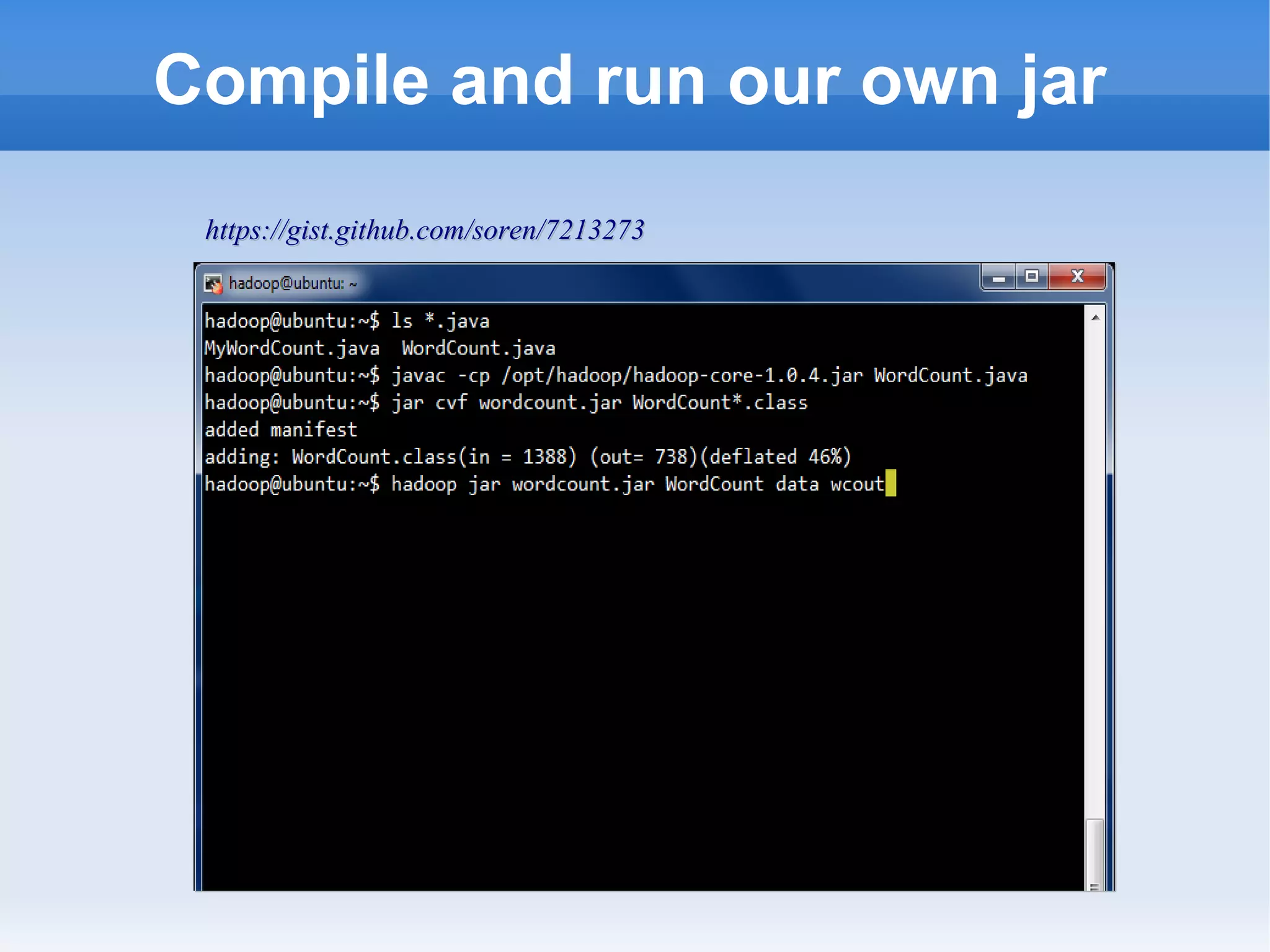
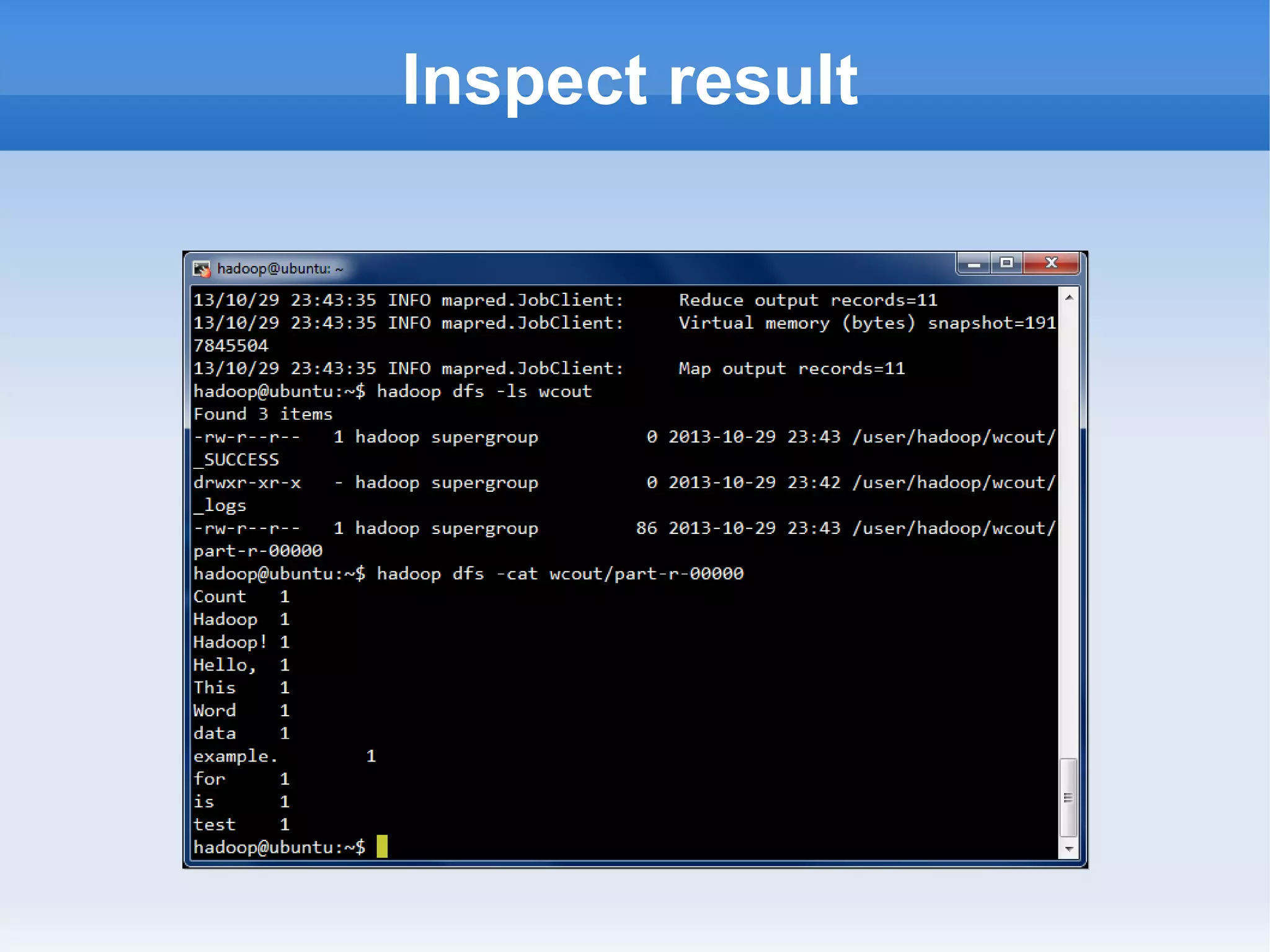
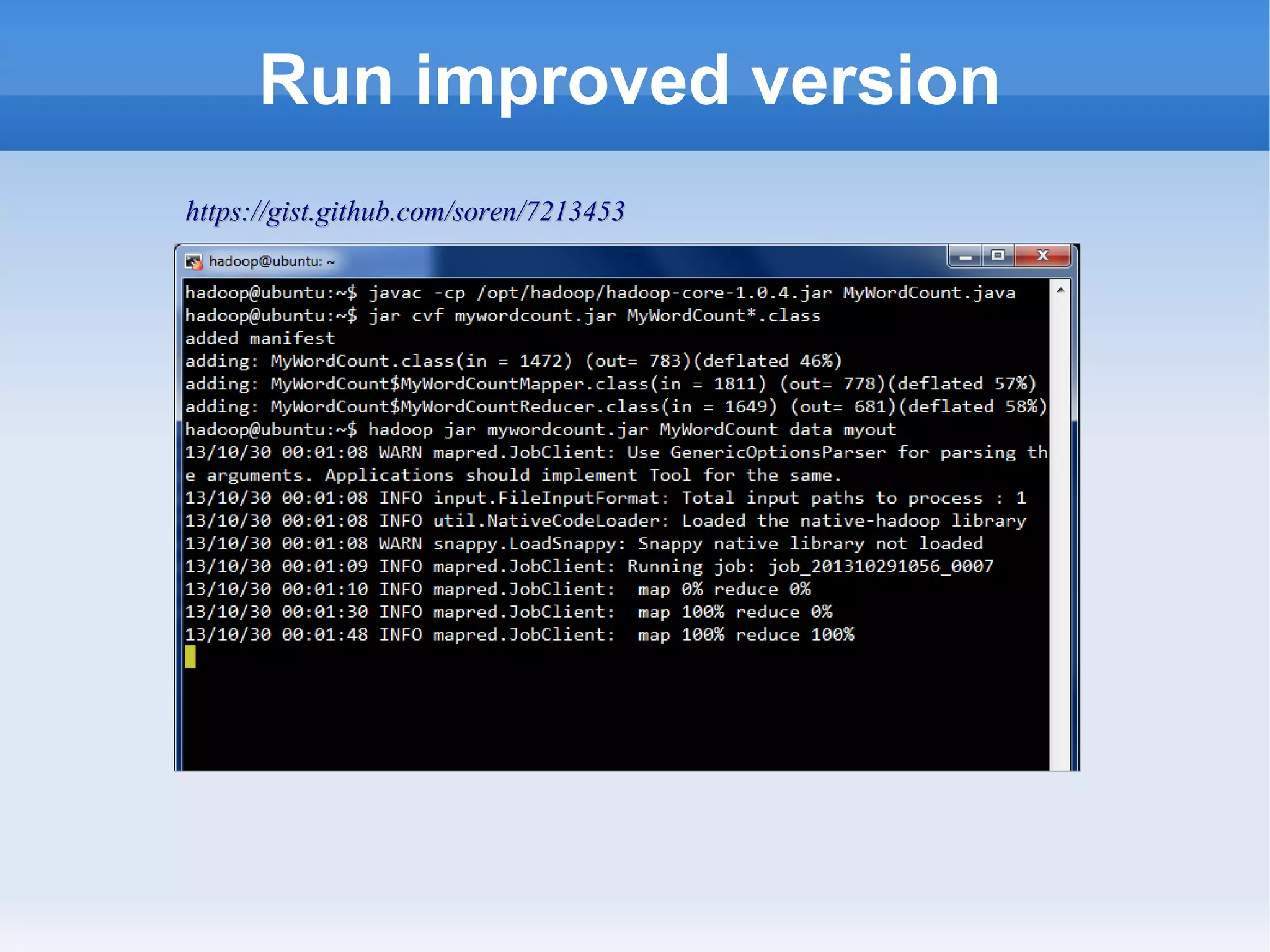
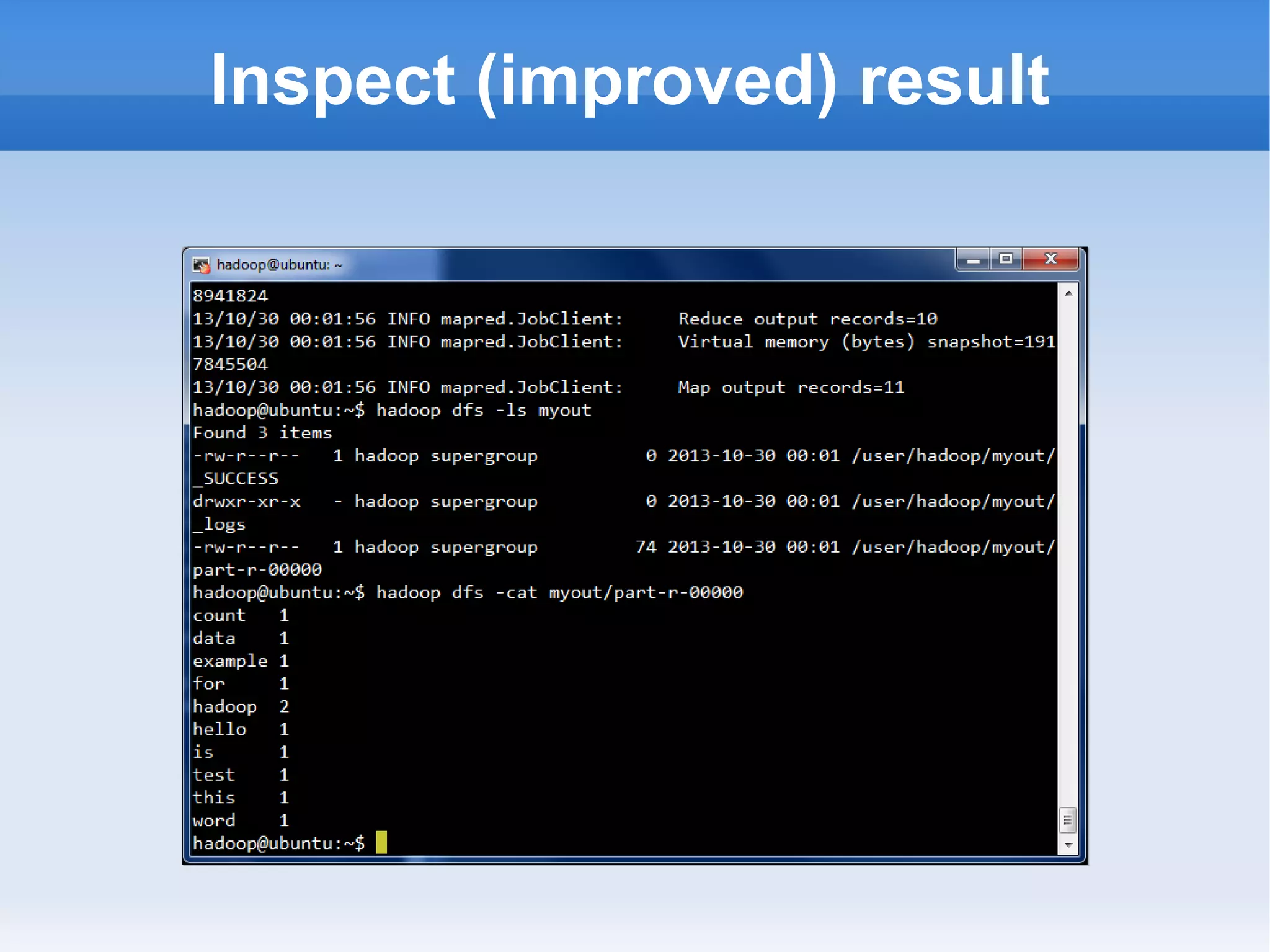



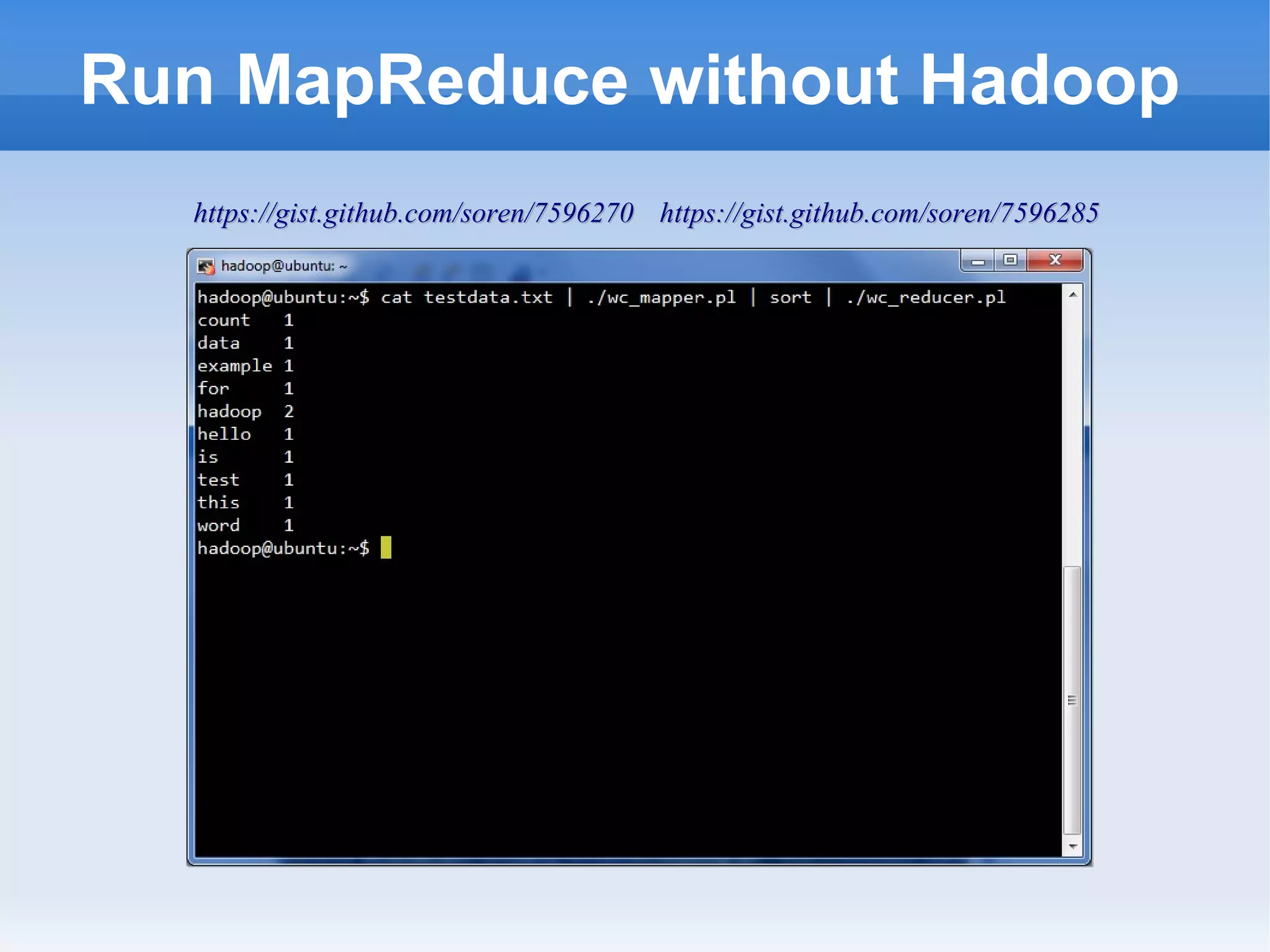

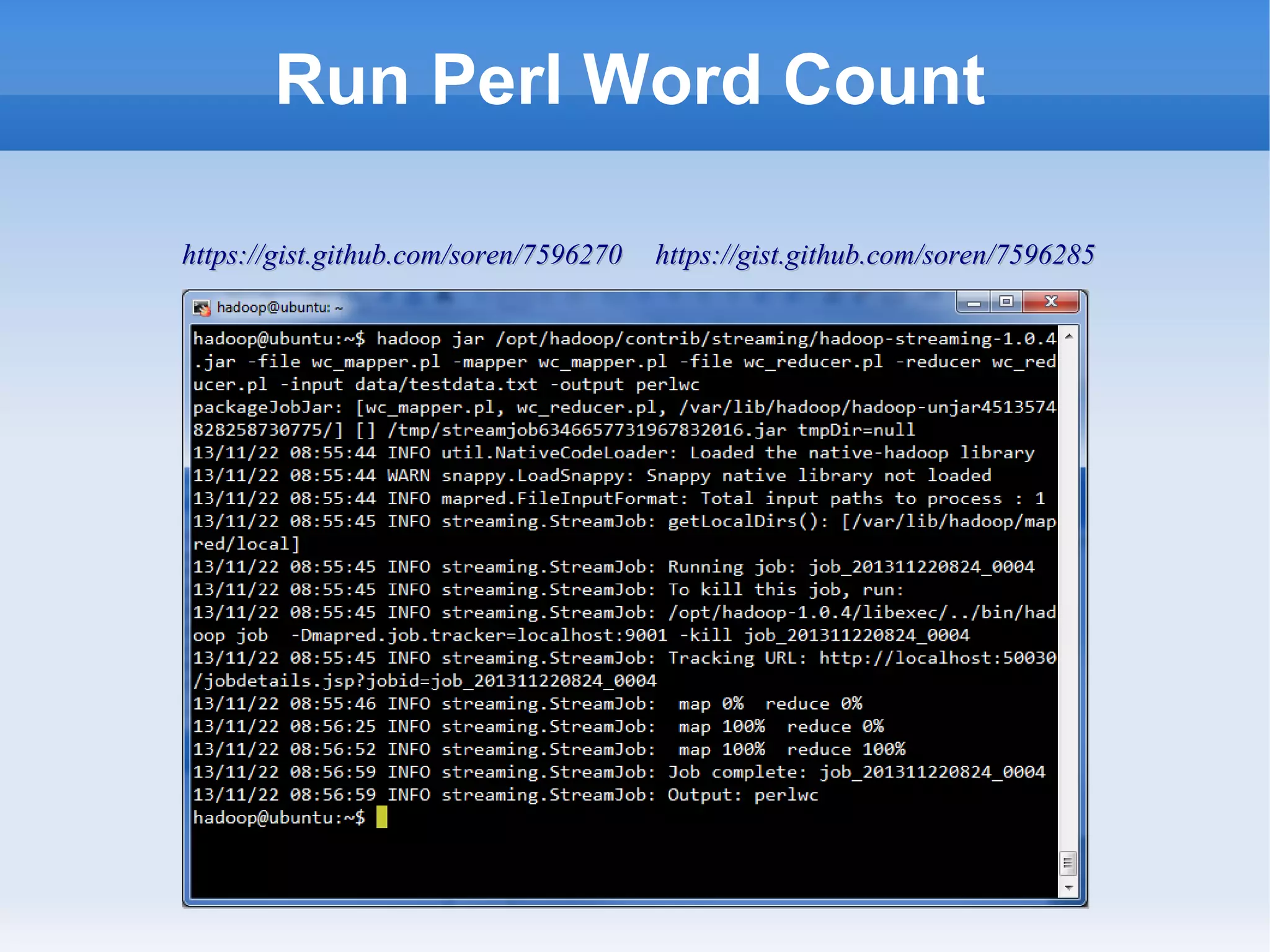
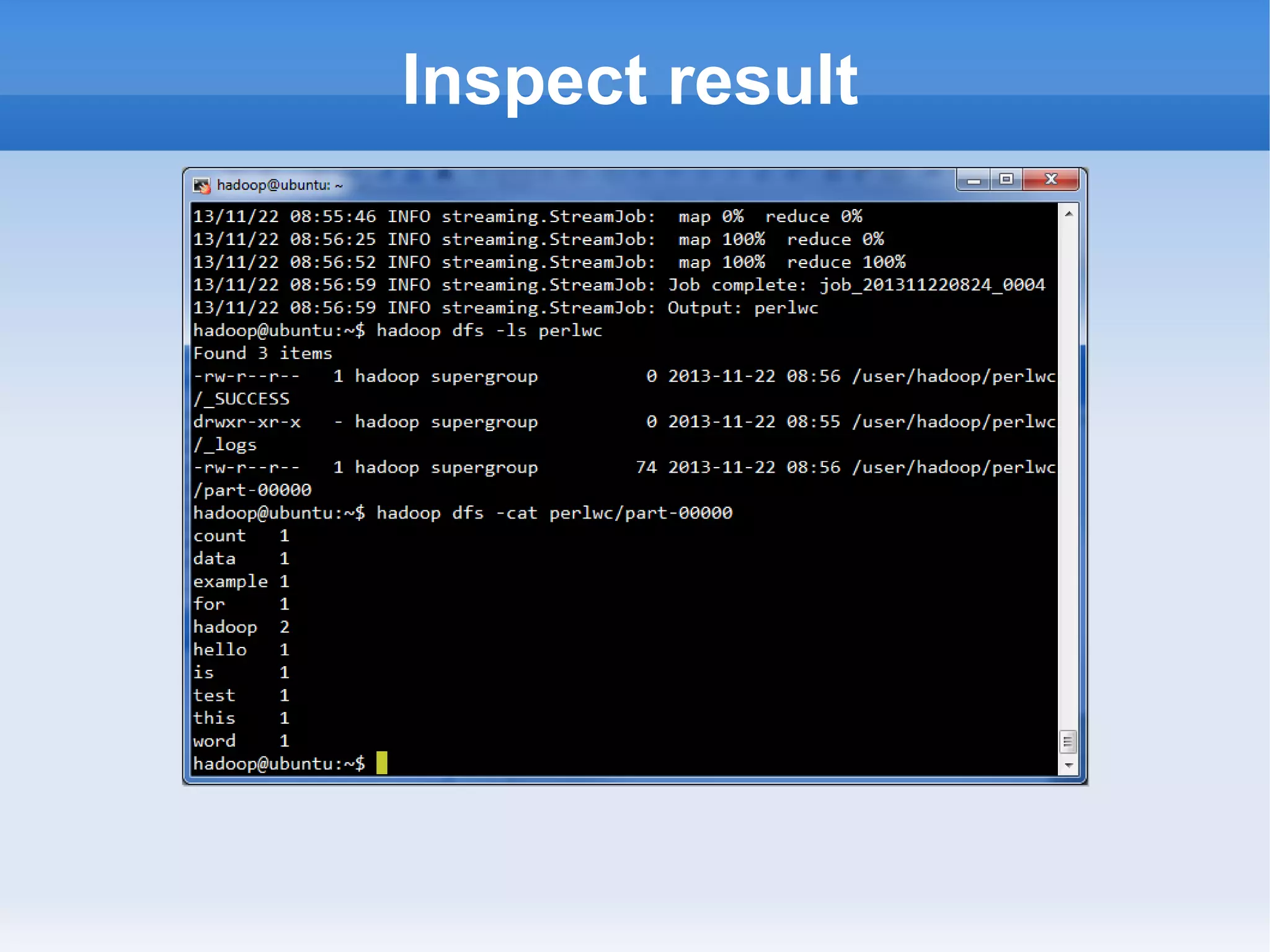


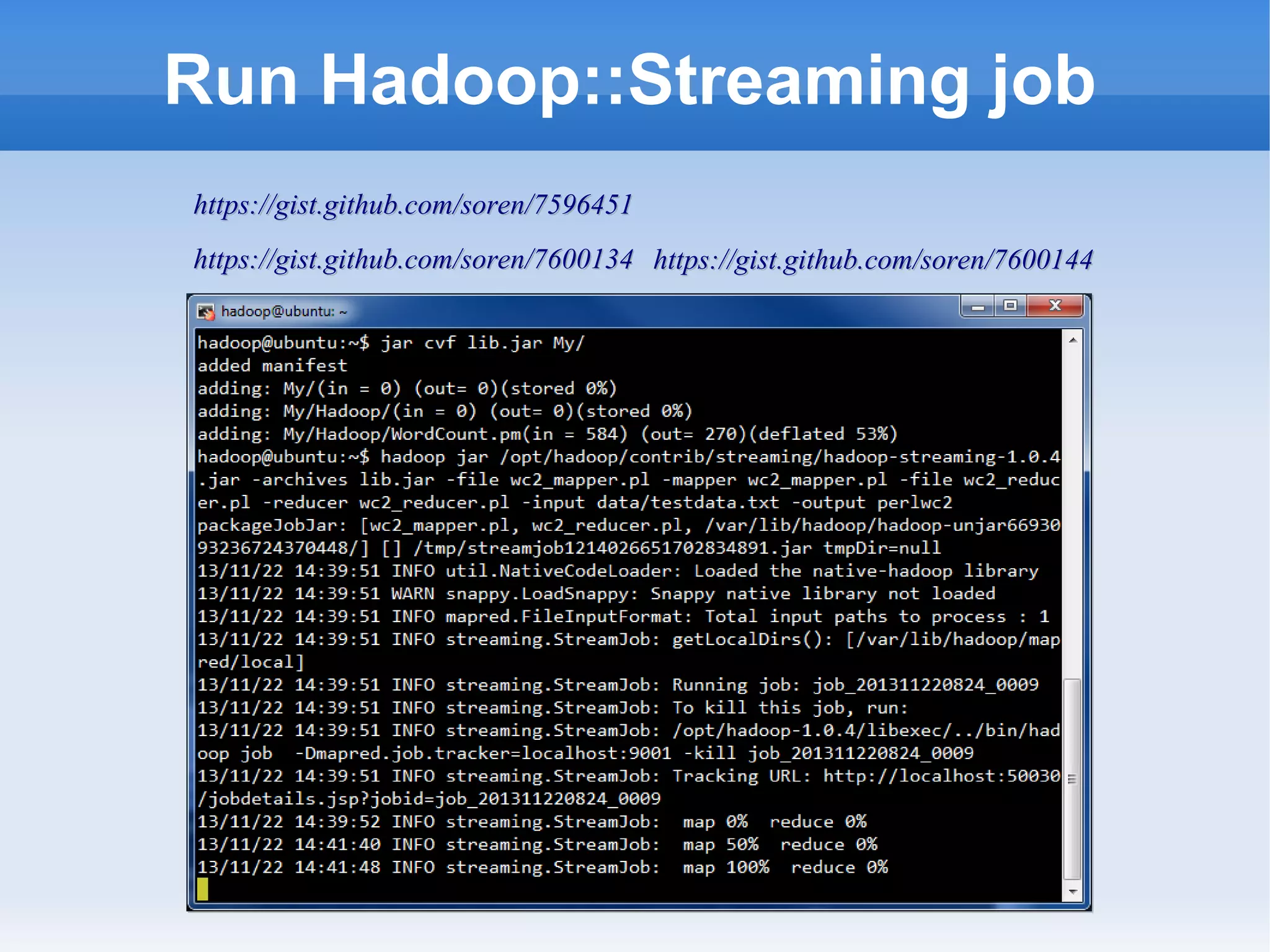
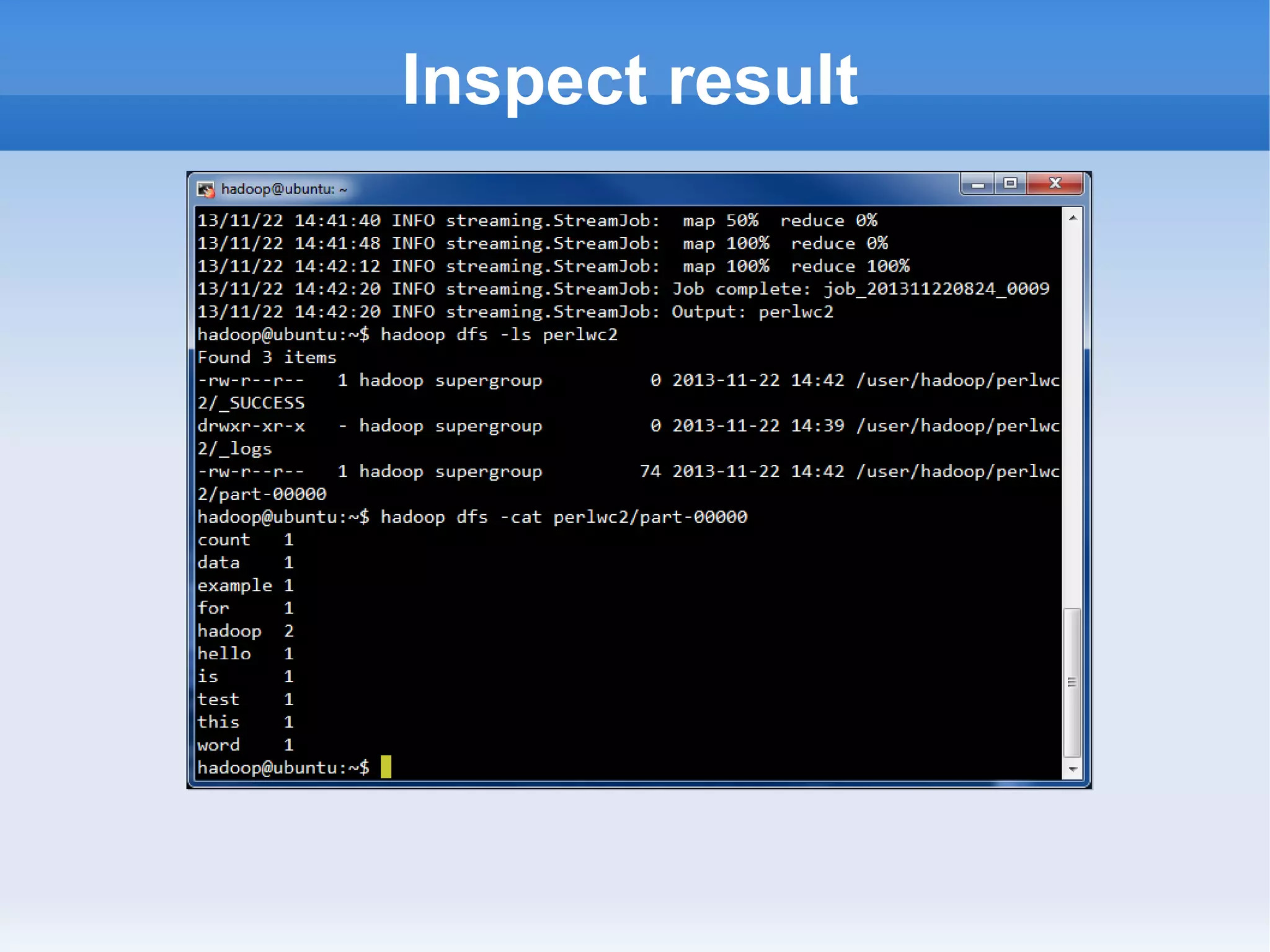







This document is a presentation on Hadoop given by Søren Lund. It begins with disclaimers that the speaker has no production experience with Hadoop. It then provides an overview of Hadoop, how it addresses the problem of scaling to large amounts of data, and its core components. The presentation demonstrates how to install and run Hadoop on a single machine, provides examples of running word count jobs locally and on Hadoop, and discusses related tools like Hive and Pig. It concludes with notes on the Hadoop user interface, joins, running Hadoop in the cloud, and other Hadoop distributions.


































![[090723]Web2.0to Sns](https://cdn.slidesharecdn.com/ss_thumbnails/090723web2-0tosns-090724222505-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

![[100621]제안발표](https://cdn.slidesharecdn.com/ss_thumbnails/100621-100621200046-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)







![[100129]나눔문화와 소셜네트워크](https://cdn.slidesharecdn.com/ss_thumbnails/100129-100128215936-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

























![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)















