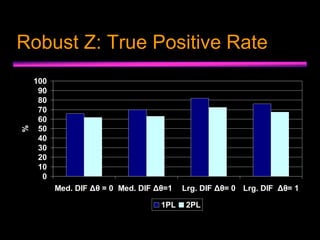
This document describes a Monte Carlo study that evaluated two Bayesian approaches for detecting differential item functioning (DIF) between items administered via computerized adaptive testing (CAT) and paper-and-pencil testing. The study generated CAT and P&P item response data under varying conditions and estimated item parameters. Two DIF detection procedures - a modified robust Z statistic and 95% credible intervals - were evaluated based on their true positive and false positive rates under different study factors like DIF size, trait level differences, and item usage. Both procedures showed adequate control of false positive DIF but power varied based on these factors, with credible intervals showing slightly higher power but also higher false positive rates. Future research is needed to test the procedures under