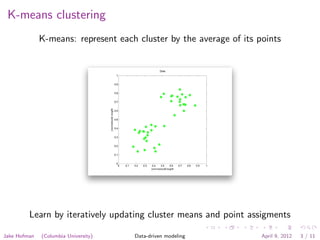
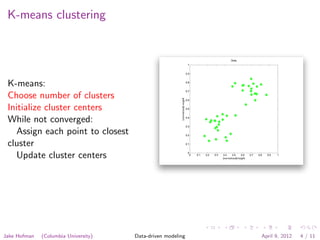
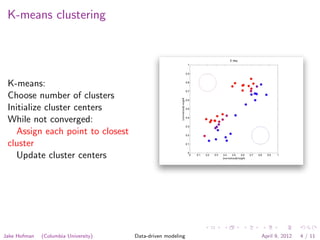
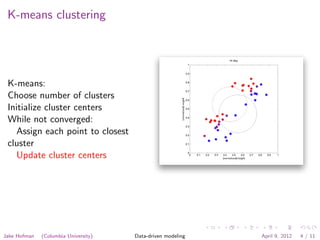
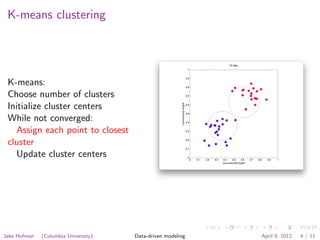
The document discusses clustering techniques for images using k-means clustering. K-means clustering involves choosing the number of clusters, initializing cluster centers, and iteratively assigning points to the closest cluster and updating cluster centers until convergence. Clustering can be applied to pixels within an image, representing each pixel as an RGB value and finding groups of similar pixels. It can also be applied to images, representing each as a binned RGB intensity histogram and finding groups of similar images.