[ML論文読み会資料] Teaching Machines to Read and Comprehend
1.
Teaching Machines to
Readand Comprehend
Karl Moritz Hermann, Tomas Kocisky,
Edward Grefenstette, Lasse Espeholt, Will Kay,
Mustafa Suleyman and Phil Blunsom
NIPS 2015
読む人: M1 山岸駿秀
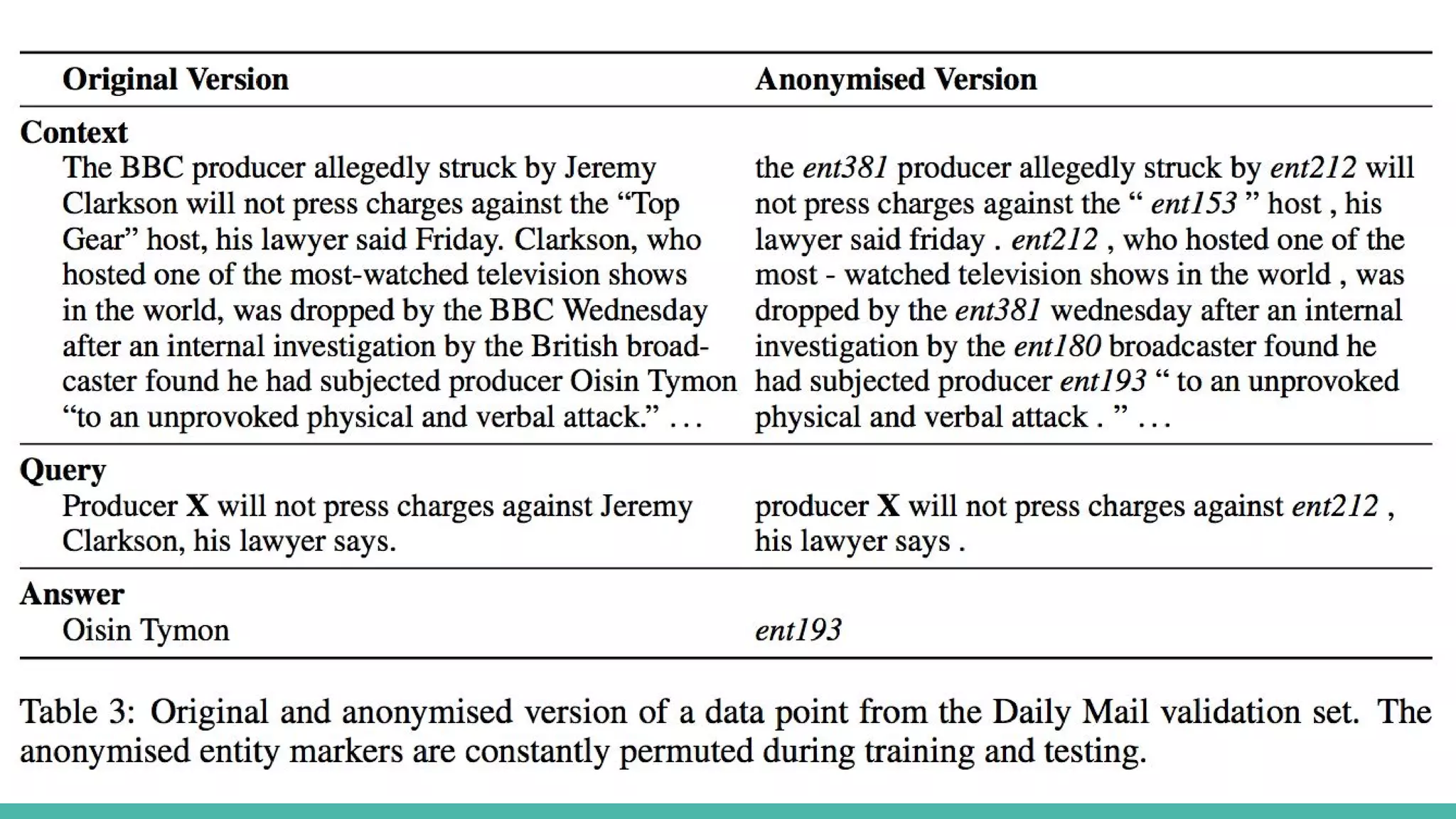
Entity replacement andpermutation
● 共起を見たり、世界知識で解けたりするデータは困る
○ The hi-tech bra that helps you beat breast X.
○ Could Saccharin help beat X?
○ Can fish oils help fight prostate X?
○ Xに当てはまるのは?→ Cancer.
● 共参照解析を使って、同じ意味のフレーズを特殊トークンで置
き換える(Anonymize)
○ トークンは毎回変える
○ クエリだけ読めばわかる問題を減らす
Result 2: WordDistance Benchmark
● 思っていたよりよくできていた
● 3つ組の関係では取れないものが取れている?
○ Q: “Tom Hanks is friends with X’s manager, Scooter Brown.”
○ D: “ ... turns out he is good friends with Scooter Brown,
manager for Carly Rae Jepsen.”
○ 3つ組は動詞を含む → (he, is, friend) しか得られなかった?
○ Word Distance Benchmarkは、friendshipやmanagementの
関係も得られている?
● 文書とクエリの単語の表層の一致も多かったため、向いてい
た可能性



















![Conclusion
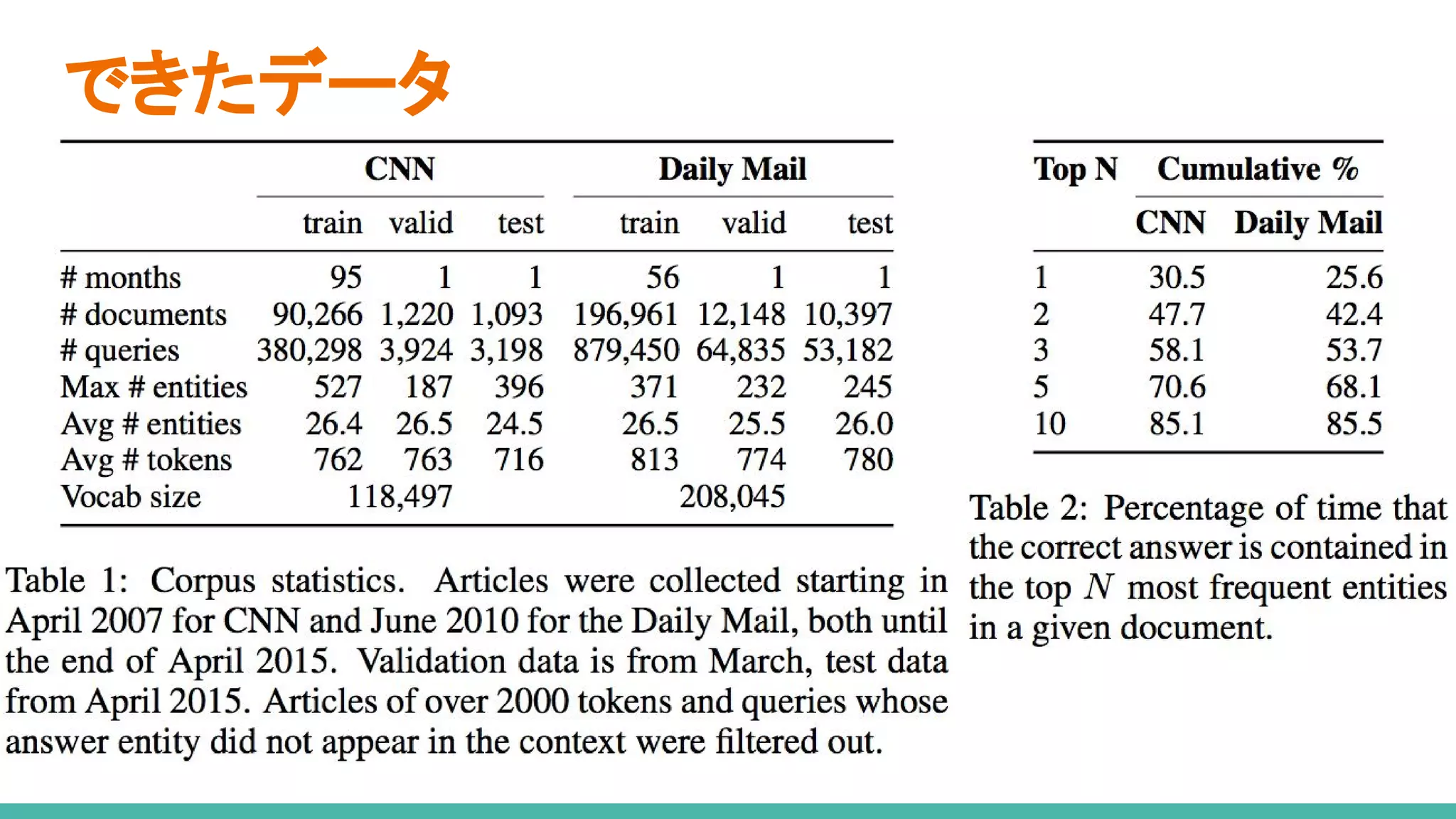
● 自然言語理解のための大きなデータを作った
○ [Chen+ ACL2016]で、簡単なタスクであることが判明
○ 2015-2016の2年間ではよく使われていたが、2017年はあまり…
○ https://www.slideshare.net/takahirokubo7792/machine-comprehension
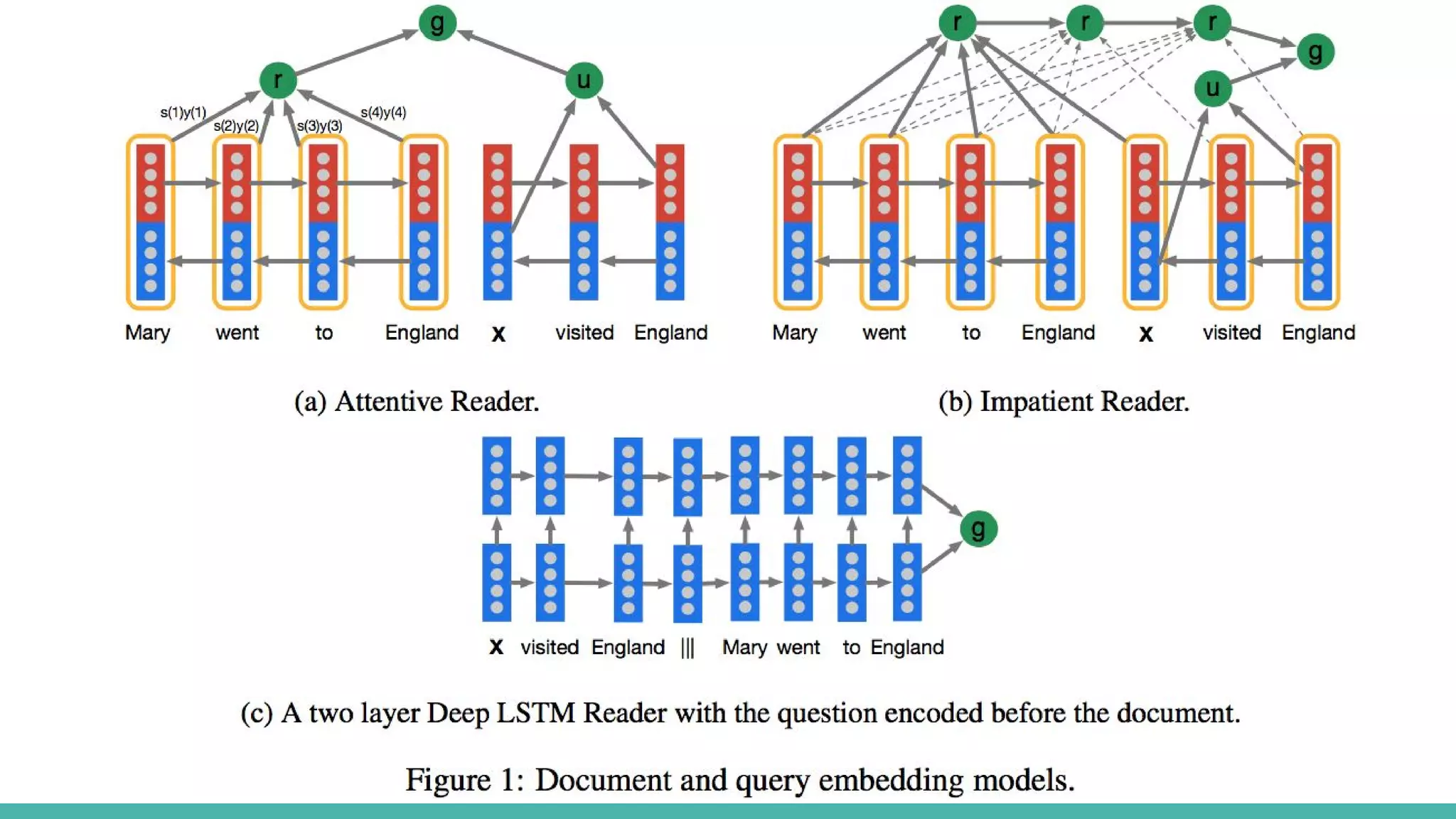
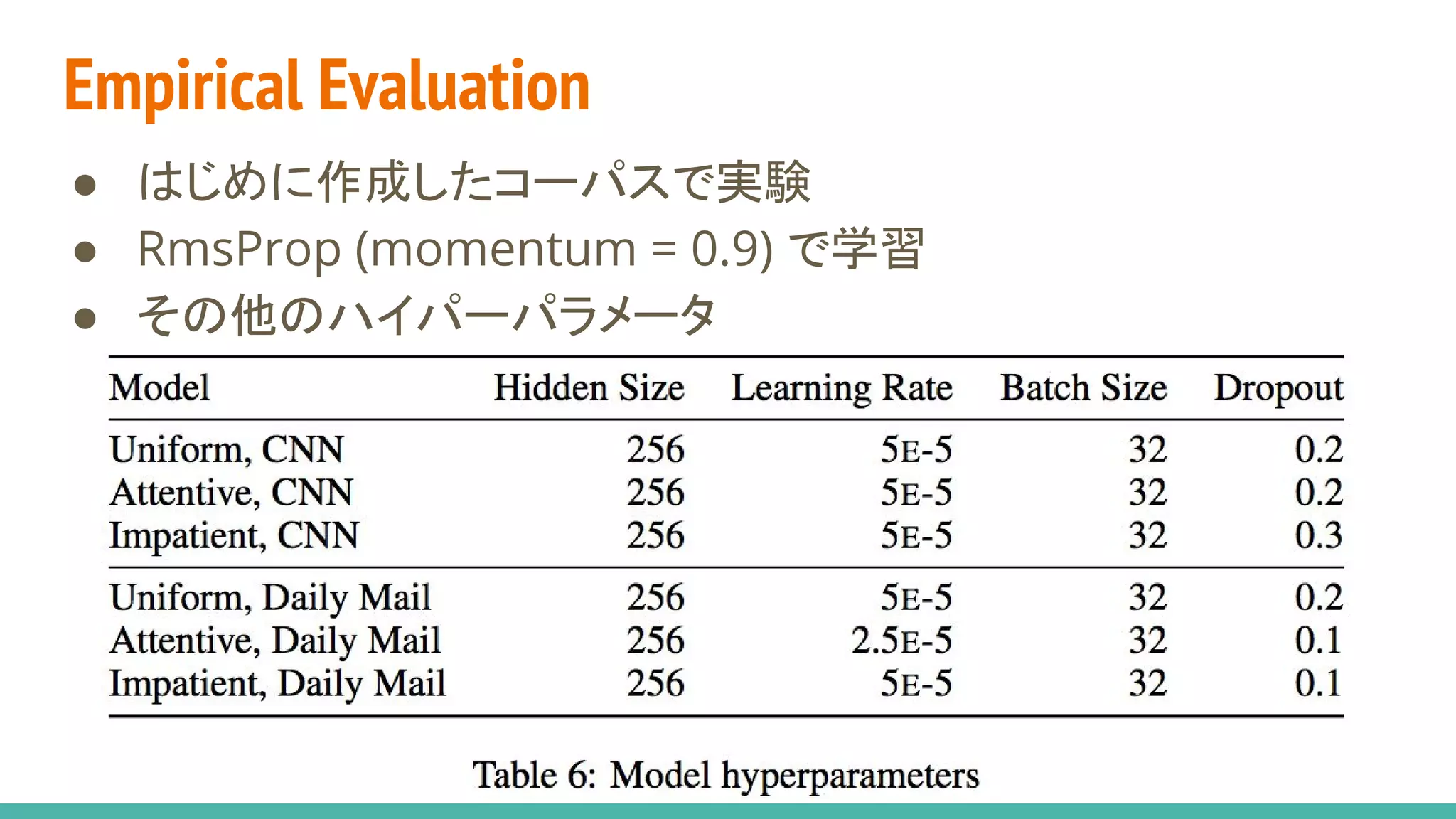
● 基礎的なニューラル手法を試した
○ アテンションは長い系列を見るためには必須
● 単語の知識や複数文書を使いたい
○ データサイズに対して計算の複雑さが線形比例してはいけない
● 大規模データがあればNNのモデルでよい結果を出せる](https://image.slidesharecdn.com/ml2-171222014201/75/ML-Teaching-Machines-to-Read-and-Comprehend-24-2048.jpg)

































![[DL輪読会]Convolutional Sequence to Sequence Learning](https://cdn.slidesharecdn.com/ss_thumbnails/dl0519-170519005603-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]QUASI-RECURRENT NEURAL NETWORKS](https://cdn.slidesharecdn.com/ss_thumbnails/quasi-recurrentneuralnetworks-170512014332-thumbnail.jpg?width=640&height=640&fit=bounds)







![[PACLING2019] Improving Context-aware Neural Machine Translation with Target-...](https://cdn.slidesharecdn.com/ss_thumbnails/paclingpresen-191012011632-thumbnail.jpg?width=640&height=640&fit=bounds)
![[修論発表会資料] 目的言語の文書文脈を用いたニューラル機械翻訳](https://cdn.slidesharecdn.com/ss_thumbnails/shuronpresen-191012004831-thumbnail.jpg?width=640&height=640&fit=bounds)
![[論文読み会資料] Beyond Error Propagation in Neural Machine Translation: Characteris...](https://cdn.slidesharecdn.com/ss_thumbnails/paperreading2018later-181107050738-thumbnail.jpg?width=640&height=640&fit=bounds)
![[ACL2018読み会資料] Sharp Nearby, Fuzzy Far Away: How Neural Language Models Use C...](https://cdn.slidesharecdn.com/ss_thumbnails/acl2018reading-181029052106-thumbnail.jpg?width=640&height=640&fit=bounds)
![[NAACL2018読み会] Deep Communicating Agents for Abstractive Summarization](https://cdn.slidesharecdn.com/ss_thumbnails/naacl2018reading-180801082628-thumbnail.jpg?width=640&height=640&fit=bounds)
![[論文読み会資料] Asynchronous Bidirectional Decoding for Neural Machine Translation](https://cdn.slidesharecdn.com/ss_thumbnails/reading0510-180511063343-thumbnail.jpg?width=640&height=640&fit=bounds)
![[EMNLP2017読み会] Efficient Attention using a Fixed-Size Memory Representation](https://cdn.slidesharecdn.com/ss_thumbnails/emnlp2017-171122025333-thumbnail.jpg?width=640&height=640&fit=bounds)
![[ML論文読み会資料] Training RNNs as Fast as CNNs](https://cdn.slidesharecdn.com/ss_thumbnails/ml-171110024905-thumbnail.jpg?width=640&height=640&fit=bounds)

![[ACL2017読み会] What do Neural Machine Translation Models Learn about Morphology?](https://cdn.slidesharecdn.com/ss_thumbnails/acl2017-171011024754-thumbnail.jpg?width=640&height=640&fit=bounds)




![[EMNLP2016読み会] Memory-enhanced Decoder for Neural Machine Translation](https://cdn.slidesharecdn.com/ss_thumbnails/emnlp-170228052941-thumbnail.jpg?width=640&height=640&fit=bounds)
![[ACL2016] Achieving Open Vocabulary Neural Machine Translation with Hybrid Wo...](https://cdn.slidesharecdn.com/ss_thumbnails/acl-161026074300-thumbnail.jpg?width=640&height=640&fit=bounds)