[ACL2018読み会資料] Sharp Nearby, Fuzzy Far Away: How Neural Language Models Use Context
1.
Sharp Nearby, FuzzyFar Away:
How Neural Language Models Use Context
Urvashi Khandelwal, He He, Peng Qi, Dan Jurafsky
(Stanford University)
M2 山岸駿秀 @ ACL2018読み会
2.
Introduction
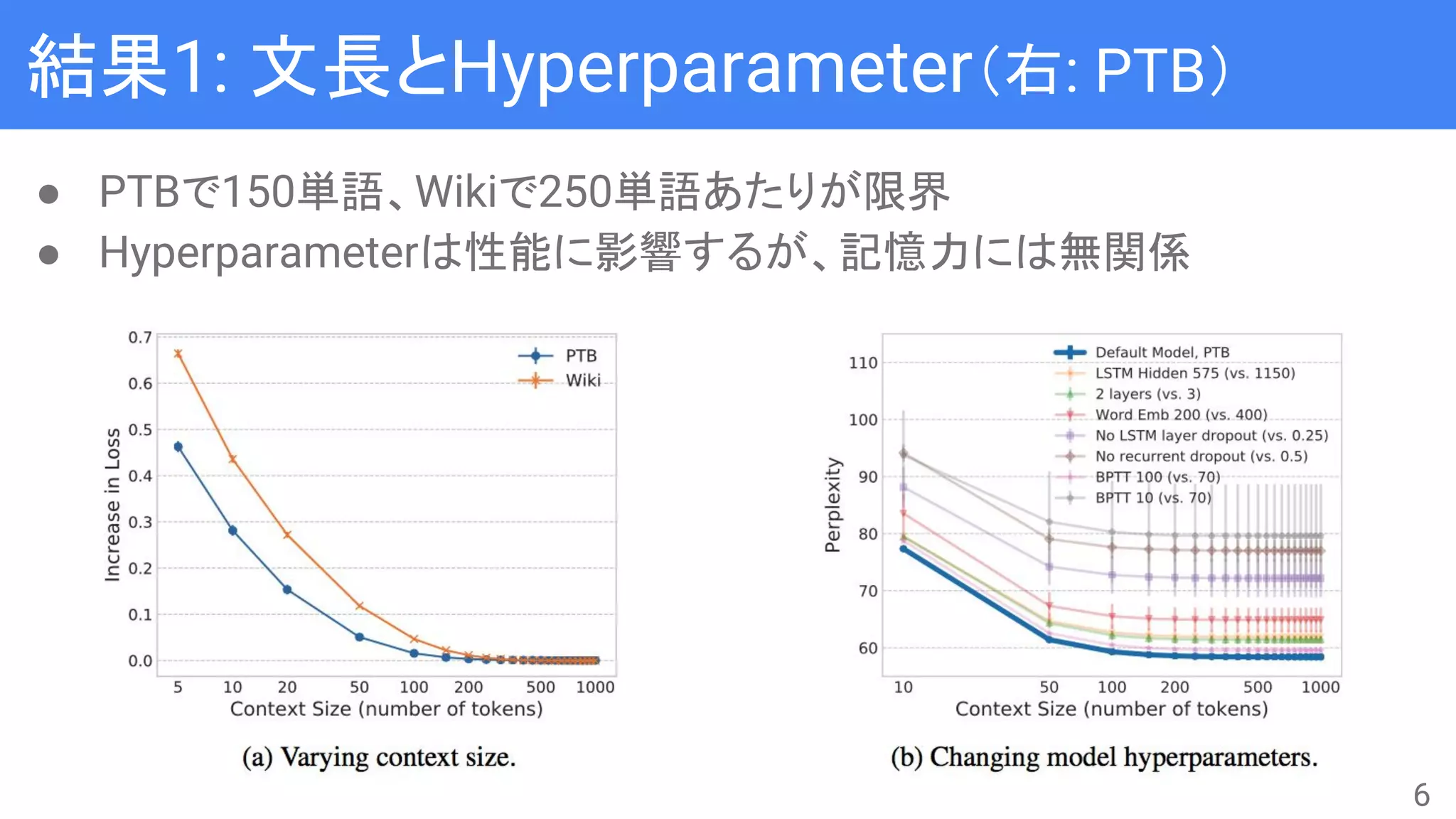
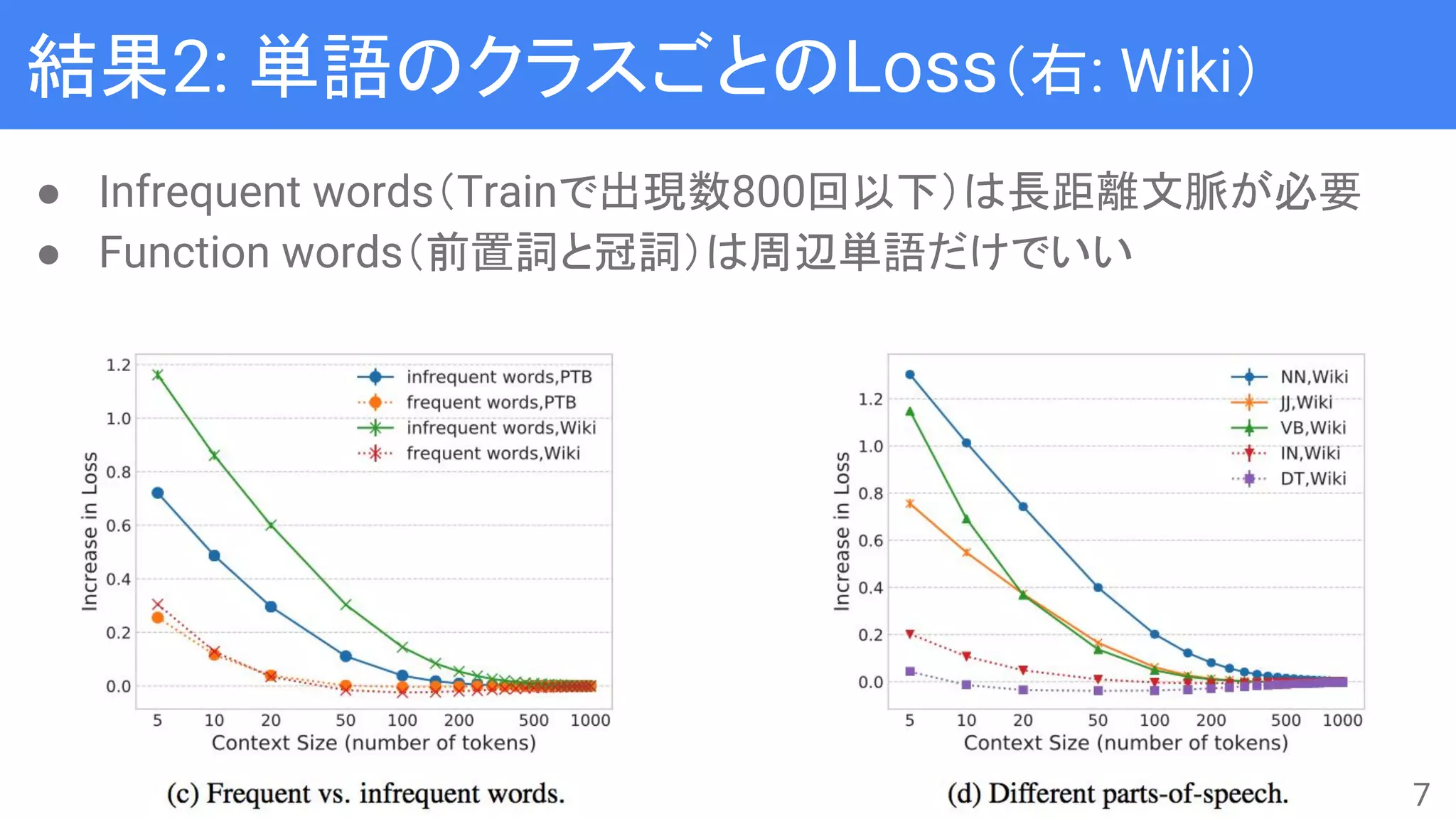
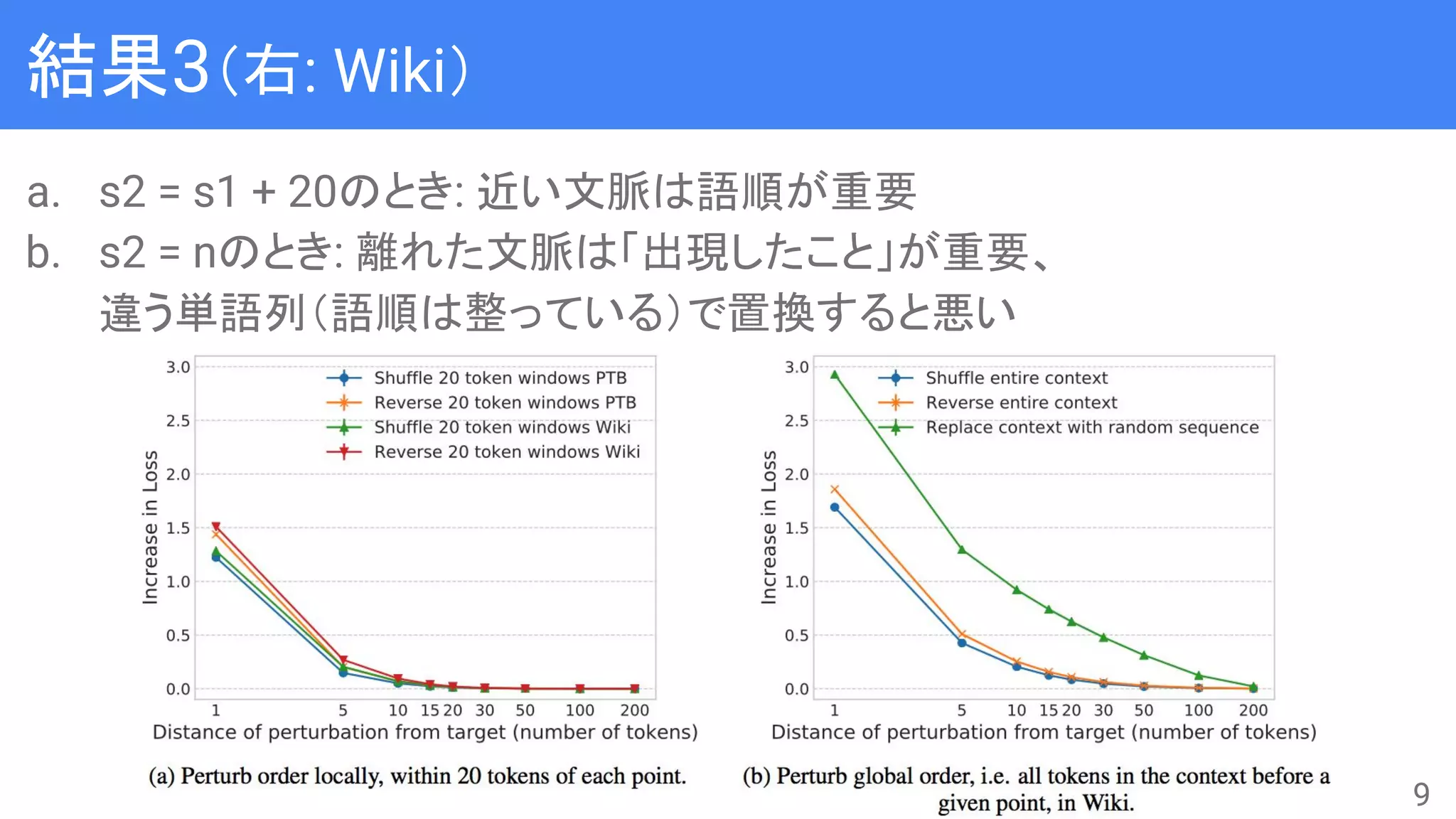
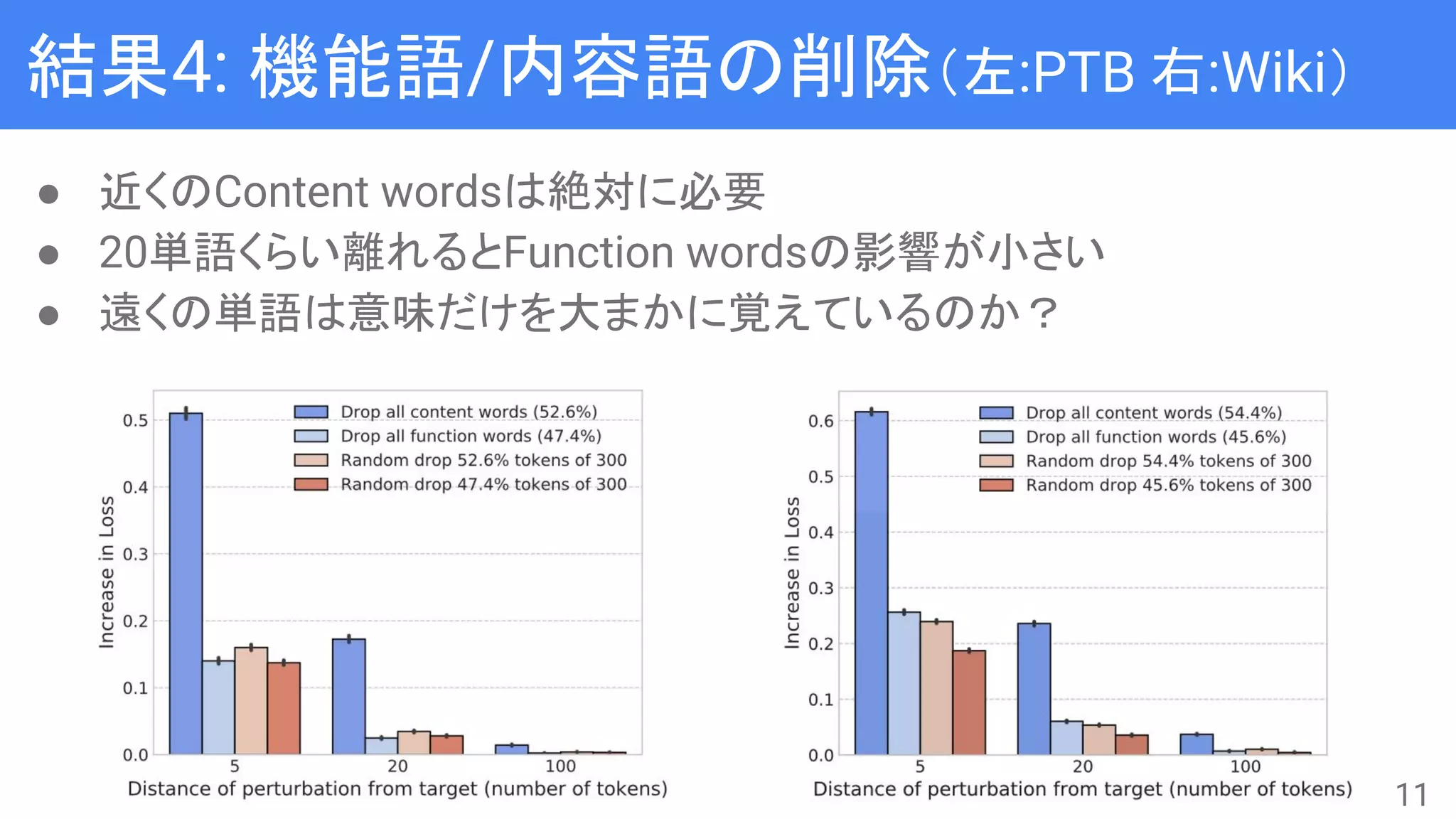
● n-gram LanguageModelと比較して、Neural Language Model
(NLM)は長距離文脈を使えるようになったとされる
● 実際に長距離文脈を捉えられているのかをAblation Test
● Neural Cache ModelはLMにどう影響するかを調査
読んだ理由
● 文脈の知見が欲しかったから
● “We propose a novel architecture …” に疲れたから
2
3.
言語モデルの復習と今回の入力例
● 以下の確率を計算
● NegativeLog Likelihoodを計算
● Perplexityで評価
... the company reported a loss after
taxation and minority interests of NUM
million irish borrowings under the
short-term parts of a credit agreement
</s> berlitz which is based in
princeton n.j. provides language
instruction and translation services
through more than NUM language centers
in NUM countries </s> in the past five
years more sim has set a fresh target
of $ NUM a share by the end of </s>
reaching that goal says robert t. UNK
applied 's chief financial officer than
NUM NUM of its sales have been outside
the u.s. </s> macmillan has owned
berlitz since NUM </s> in the first six
3





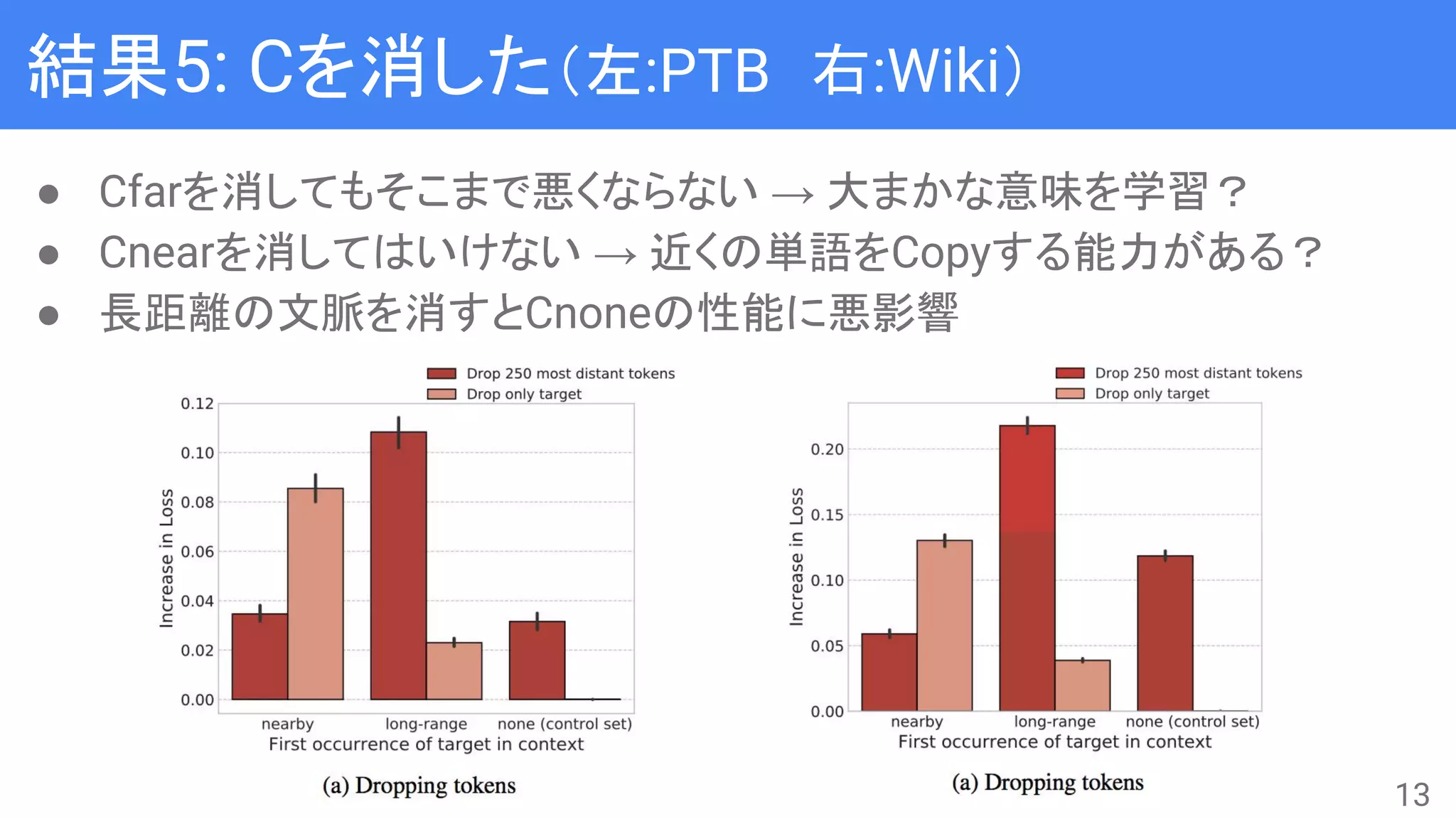
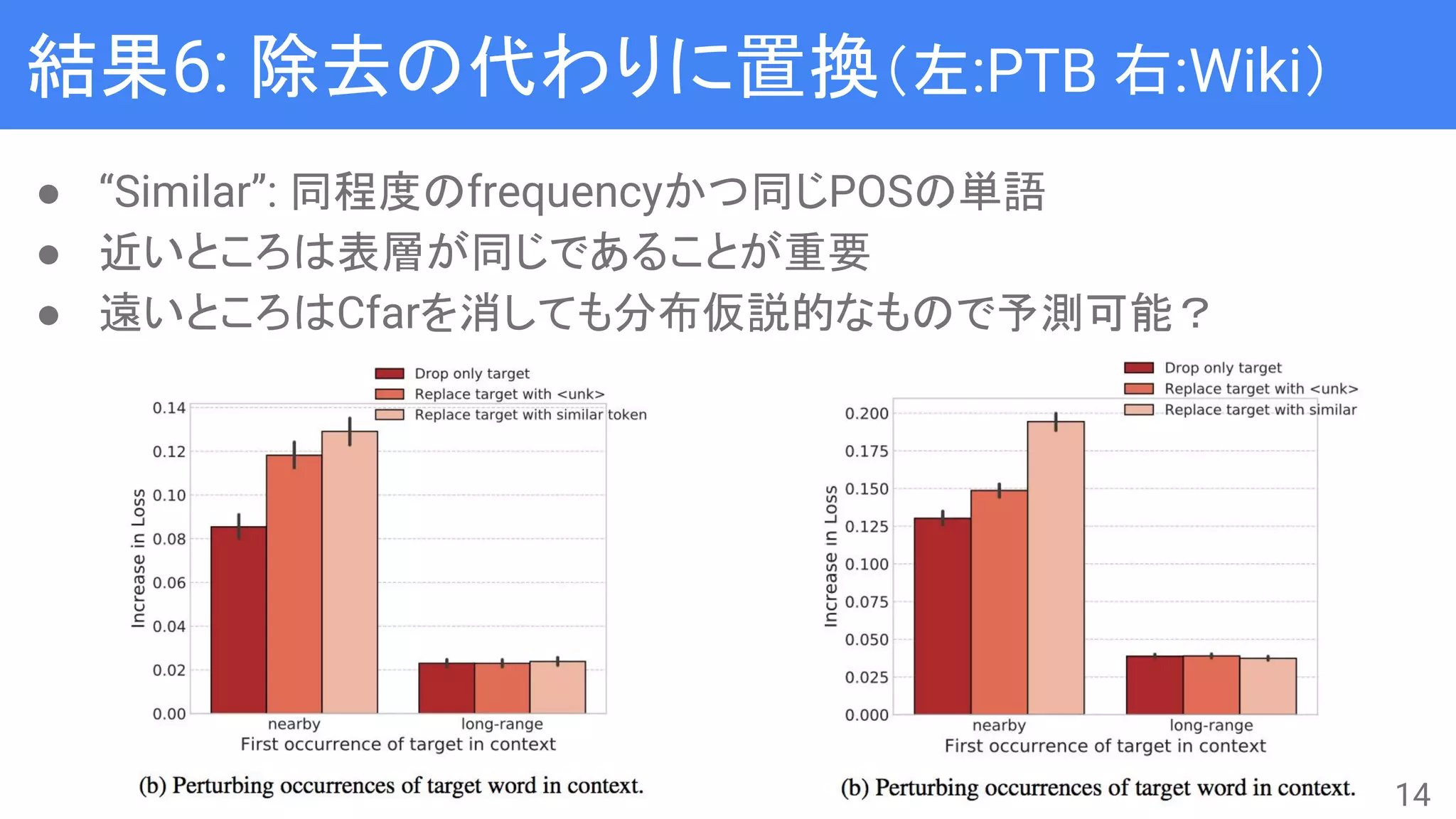
![Nearby vs. long-range context
● LSTMはだいたい200単語くらい覚えられる
→ 場所による特徴はあるのか?
● 文脈の途中(長さは span = (s1, s2] で管理 )を変化させる
○ ρはshuffleかreverse
● 文長は300単語で固定
8](https://image.slidesharecdn.com/acl2018reading-181029052106/75/ACL2018-Sharp-Nearby-Fuzzy-Far-Away-How-Neural-Language-Models-Use-Context-8-2048.jpg)


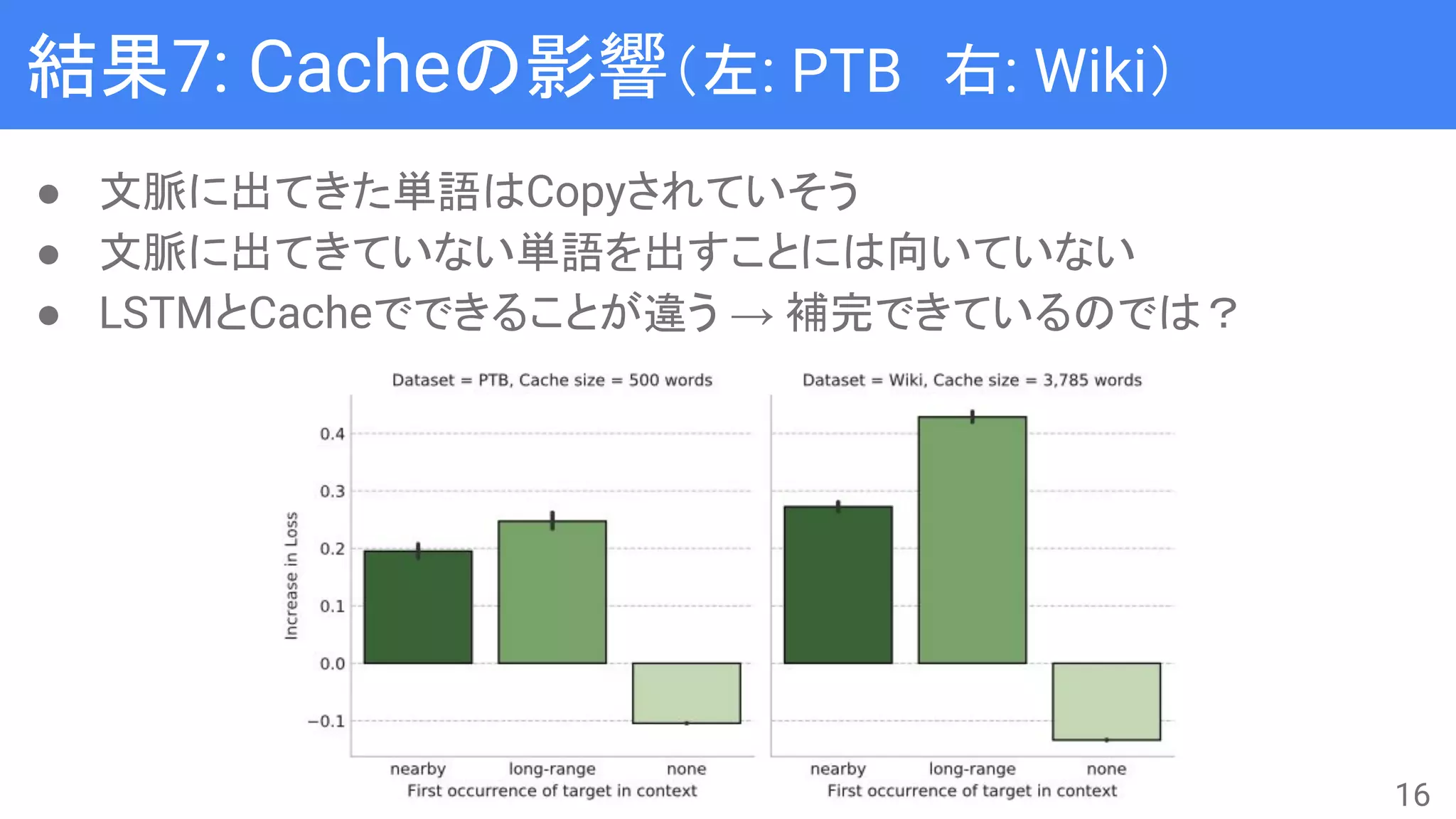
![How does the cache help?
● Neural Cache Model [Grave+, ICLR2017]
○ hi
はそれまでのhidden states
○ 各単語に対してPcacheを計算し、Plm + Pcacheを生成確率とする
● 300単語以上使う(Document lengthの平均)
○ PTB: 500単語
○ Wiki: 3875単語
● Cache Modelを基準としたNLMのPPLの増加率で評価
15](https://image.slidesharecdn.com/acl2018reading-181029052106/75/ACL2018-Sharp-Nearby-Fuzzy-Far-Away-How-Neural-Language-Models-Use-Context-15-2048.jpg)
















![[NeurIPS2018読み会@PFN] On the Dimensionality of Word Embedding](https://cdn.slidesharecdn.com/ss_thumbnails/pfnonthedimensionalityofwordembedding-190126060357-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]BERT: Pre-training of Deep Bidirectional Transformers for Language Und...](https://cdn.slidesharecdn.com/ss_thumbnails/dlreadingpaper20181019-181019010218-thumbnail.jpg?width=640&height=640&fit=bounds)

![[ACL2016] Achieving Open Vocabulary Neural Machine Translation with Hybrid Wo...](https://cdn.slidesharecdn.com/ss_thumbnails/acl-161026074300-thumbnail.jpg?width=640&height=640&fit=bounds)


















![[ML論文読み会資料] Teaching Machines to Read and Comprehend](https://cdn.slidesharecdn.com/ss_thumbnails/ml2-171222014201-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Abstractive Summarization of Reddit Posts with Multi-level Memory Netw...](https://cdn.slidesharecdn.com/ss_thumbnails/abstractivesummarizationofredditpostswithmulti-levelmemorynetworks-190219034601-thumbnail.jpg?width=640&height=640&fit=bounds)


![[ACL2017読み会] What do Neural Machine Translation Models Learn about Morphology?](https://cdn.slidesharecdn.com/ss_thumbnails/acl2017-171011024754-thumbnail.jpg?width=640&height=640&fit=bounds)
![[PACLING2019] Improving Context-aware Neural Machine Translation with Target-...](https://cdn.slidesharecdn.com/ss_thumbnails/paclingpresen-191012011632-thumbnail.jpg?width=640&height=640&fit=bounds)
![[論文読み会資料] Beyond Error Propagation in Neural Machine Translation: Characteris...](https://cdn.slidesharecdn.com/ss_thumbnails/paperreading2018later-181107050738-thumbnail.jpg?width=640&height=640&fit=bounds)

![[NAACL2018読み会] Deep Communicating Agents for Abstractive Summarization](https://cdn.slidesharecdn.com/ss_thumbnails/naacl2018reading-180801082628-thumbnail.jpg?width=640&height=640&fit=bounds)
![[EMNLP2017読み会] Efficient Attention using a Fixed-Size Memory Representation](https://cdn.slidesharecdn.com/ss_thumbnails/emnlp2017-171122025333-thumbnail.jpg?width=640&height=640&fit=bounds)

![[論文読み会資料] Asynchronous Bidirectional Decoding for Neural Machine Translation](https://cdn.slidesharecdn.com/ss_thumbnails/reading0510-180511063343-thumbnail.jpg?width=640&height=640&fit=bounds)

![[ML論文読み会資料] Training RNNs as Fast as CNNs](https://cdn.slidesharecdn.com/ss_thumbnails/ml-171110024905-thumbnail.jpg?width=640&height=640&fit=bounds)
![[EMNLP2016読み会] Memory-enhanced Decoder for Neural Machine Translation](https://cdn.slidesharecdn.com/ss_thumbnails/emnlp-170228052941-thumbnail.jpg?width=640&height=640&fit=bounds)

![[修論発表会資料] 目的言語の文書文脈を用いたニューラル機械翻訳](https://cdn.slidesharecdn.com/ss_thumbnails/shuronpresen-191012004831-thumbnail.jpg?width=640&height=640&fit=bounds)






