実験1 Text Simplification
Data sets
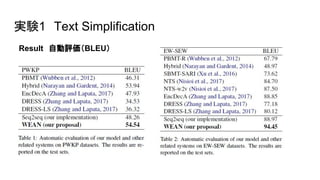
●Parallel WIkipedia Simplification Corpus (PWKP) (Zhu et al., 2010)
○ train 89,042 pair
○ dev 205 pair
○ test 100 pair
● English Wikipedia and Simple English Wikipedia (EW-SEW) (Hwang et al.2015)
○ train 280,000 pair
○ dev 2000 pair
○ test 359 pair
10.
実験1 Text Simplification
Evaluation Metrics
●Automatic evaluation. BLEU(Paineni et al., 2002)
○ PWKP single reference
○ EW-SEW multi reference
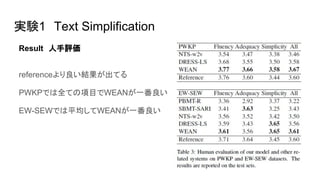
● Human evaluation. (1 is very bad, 5 is very good)
○ Fluency(流暢性) 1 ~ 5
○ Adequacy(妥当性)1 ~ 5
○ Simplicity(簡潔性) 1 ~ 5
実験2 Large ScaleText Summarization
Dataset
Large Scale Chinese Social Media Short Text Summarization Dataset(LCSTS)
2,400,000文ペア
● Part1 2,400,591ペア train
● Part2 8,685ぺア validation
● Part3 725ペア test
Part2とPart3は1~5で自動評価されていて、スコア3以上のものを選択




![モデル Query
qt: query
Wc: parameter
st: hidden state of decoder
ct: context vector
[st; ct]: concat](https://image.slidesharecdn.com/queryandoutputgeneratingwordsbyqueryingdistributedwordrepresentationsforparaphrasegeneration-180719051133/85/Query-and-output-generating-words-by-querying-distributed-word-representations-for-paraphrase-generation-6-320.jpg)


















![[DL輪読会]Batch Renormalization: Towards Reducing Minibatch Dependence in Batch-...](https://cdn.slidesharecdn.com/ss_thumbnails/dlu8f2au8aadu4f1av2-170407001546-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]Abstractive Summarization of Reddit Posts with Multi-level Memory Netw...](https://cdn.slidesharecdn.com/ss_thumbnails/abstractivesummarizationofredditpostswithmulti-levelmemorynetworks-190219034601-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL Hacks]Pretraining-Based Natural Language Generation for Text Summarizatio...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhackspretraining-basednaturallanguagegenerationfortextsummarization-190422070150-thumbnail.jpg?width=640&height=640&fit=bounds)






![[ACL2018読み会資料] Sharp Nearby, Fuzzy Far Away: How Neural Language Models Use C...](https://cdn.slidesharecdn.com/ss_thumbnails/acl2018reading-181029052106-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DLHacks]Topic‑Aware Neu ral KeyphraseGenerationforSocial Media Language](https://cdn.slidesharecdn.com/ss_thumbnails/dlhackstakgfinal-190820070754-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]GraphSeq2Seq: Graph-Sequence-to-Sequence for Neural Machine Translation](https://cdn.slidesharecdn.com/ss_thumbnails/20181117graphseq2seqkayama-181116022737-thumbnail.jpg?width=640&height=640&fit=bounds)






