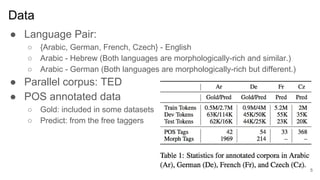
1) The document examines what neural machine translation models learn about morphology through experiments analyzing the hidden states of NMT models.
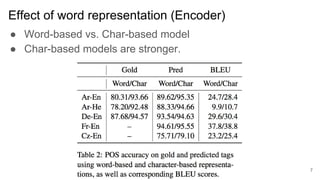
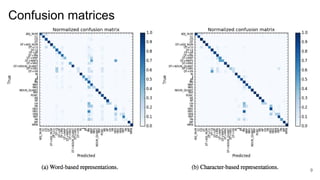
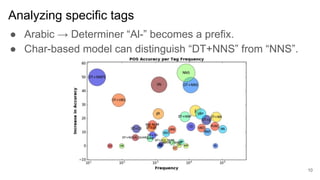
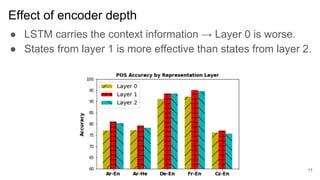
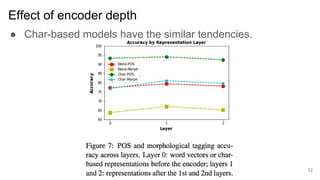
2) It finds that character-based word representations better capture morphological information than word-based representations, and that lower encoder layers learn more about a word's structure while higher layers improve translation.
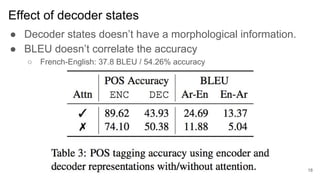
3) The target language does not significantly impact how much the model learns about source language morphology, and decoder states do not capture rich morphological information.





![Char-base Encoder
● Character-aware Neural Language
Model [Kim+, AAAI2016]
● Character-based Neural Machine
Translation [Costa-jussa and Fonollosa,
ACL2016]
● Character embedding
→ word embedding
● Obtained word embeddings are inputted
into the word-based RNN-LM.
6](https://image.slidesharecdn.com/acl2017-171011024754/85/ACL2017-What-do-Neural-Machine-Translation-Models-Learn-about-Morphology-6-320.jpg)

























































![[PACLING2019] Improving Context-aware Neural Machine Translation with Target-...](https://cdn.slidesharecdn.com/ss_thumbnails/paclingpresen-191012011632-thumbnail.jpg?width=640&height=640&fit=bounds)
![[修論発表会資料] 目的言語の文書文脈を用いたニューラル機械翻訳](https://cdn.slidesharecdn.com/ss_thumbnails/shuronpresen-191012004831-thumbnail.jpg?width=640&height=640&fit=bounds)
![[論文読み会資料] Beyond Error Propagation in Neural Machine Translation: Characteris...](https://cdn.slidesharecdn.com/ss_thumbnails/paperreading2018later-181107050738-thumbnail.jpg?width=640&height=640&fit=bounds)
![[ACL2018読み会資料] Sharp Nearby, Fuzzy Far Away: How Neural Language Models Use C...](https://cdn.slidesharecdn.com/ss_thumbnails/acl2018reading-181029052106-thumbnail.jpg?width=640&height=640&fit=bounds)
![[NAACL2018読み会] Deep Communicating Agents for Abstractive Summarization](https://cdn.slidesharecdn.com/ss_thumbnails/naacl2018reading-180801082628-thumbnail.jpg?width=640&height=640&fit=bounds)
![[論文読み会資料] Asynchronous Bidirectional Decoding for Neural Machine Translation](https://cdn.slidesharecdn.com/ss_thumbnails/reading0510-180511063343-thumbnail.jpg?width=640&height=640&fit=bounds)
![[ML論文読み会資料] Teaching Machines to Read and Comprehend](https://cdn.slidesharecdn.com/ss_thumbnails/ml2-171222014201-thumbnail.jpg?width=640&height=640&fit=bounds)
![[EMNLP2017読み会] Efficient Attention using a Fixed-Size Memory Representation](https://cdn.slidesharecdn.com/ss_thumbnails/emnlp2017-171122025333-thumbnail.jpg?width=640&height=640&fit=bounds)
![[ML論文読み会資料] Training RNNs as Fast as CNNs](https://cdn.slidesharecdn.com/ss_thumbnails/ml-171110024905-thumbnail.jpg?width=640&height=640&fit=bounds)





![[EMNLP2016読み会] Memory-enhanced Decoder for Neural Machine Translation](https://cdn.slidesharecdn.com/ss_thumbnails/emnlp-170228052941-thumbnail.jpg?width=640&height=640&fit=bounds)
![[ACL2016] Achieving Open Vocabulary Neural Machine Translation with Hybrid Wo...](https://cdn.slidesharecdn.com/ss_thumbnails/acl-161026074300-thumbnail.jpg?width=640&height=640&fit=bounds)



















