Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
HY
Uploaded by
Hayahide Yamagishi
PPTX, PDF
386 views
[EMNLP2016読み会] Memory-enhanced Decoder for Neural Machine Translation
首都大学東京・小町研内のEMNLP2016読み会で使用する資料です
Data & Analytics
◦
Read more
0
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 17
2
/ 17
3
/ 17
4
/ 17
5
/ 17
6
/ 17
7
/ 17
8
/ 17
9
/ 17
10
/ 17
11
/ 17
12
/ 17
13
/ 17
14
/ 17
15
/ 17
16
/ 17
17
/ 17
More Related Content
PDF
OSとWindowsとMicrosoft
by
Masato Hanayama
PPTX
WebGLで浮動小数点テクスチャを扱う話
by
翔 石井
PDF
JubaQLご紹介
by
JubatusOfficial
PPTX
"アレ"からJubatusを使う
by
JubatusOfficial
PPTX
FPGAでmrubyを動かす
by
Shuta Kimura
PDF
Jubatus 新機能ハイライト
by
JubatusOfficial
PDF
蛇を埋葬する(PythonをEmbedする)
by
Shintarou Okada
PPTX
EC2クラスタインスタンス使ってみました!
by
Eiji Sato
OSとWindowsとMicrosoft
by
Masato Hanayama
WebGLで浮動小数点テクスチャを扱う話
by
翔 石井
JubaQLご紹介
by
JubatusOfficial
"アレ"からJubatusを使う
by
JubatusOfficial
FPGAでmrubyを動かす
by
Shuta Kimura
Jubatus 新機能ハイライト
by
JubatusOfficial
蛇を埋葬する(PythonをEmbedする)
by
Shintarou Okada
EC2クラスタインスタンス使ってみました!
by
Eiji Sato
What's hot
PDF
データ圧縮アルゴリズムを用いたマルウェア感染通信ログの判定
by
JubatusOfficial
PPTX
CPUをちょっと
by
Tksenda
PPTX
脱! 俺たちは雰囲気でBPをいじっている
by
Naoaki Yamaji
PPTX
無印Pentium debian install memo
by
Yukiyoshi Yoshimoto
ODP
札幌シムトラ学会 発表資料
by
myagami
PDF
ML Studio / CNTK ハンズオン資料の紹介と開発環境の構築手順
by
Yoshitaka Seo
PDF
Introducing mroonga 20111129
by
Kentoku
データ圧縮アルゴリズムを用いたマルウェア感染通信ログの判定
by
JubatusOfficial
CPUをちょっと
by
Tksenda
脱! 俺たちは雰囲気でBPをいじっている
by
Naoaki Yamaji
無印Pentium debian install memo
by
Yukiyoshi Yoshimoto
札幌シムトラ学会 発表資料
by
myagami
ML Studio / CNTK ハンズオン資料の紹介と開発環境の構築手順
by
Yoshitaka Seo
Introducing mroonga 20111129
by
Kentoku
Viewers also liked
PPTX
[ACL2016] Achieving Open Vocabulary Neural Machine Translation with Hybrid Wo...
by
Hayahide Yamagishi
PDF
Chainerの使い方と 自然言語処理への応用
by
Yuya Unno
PDF
EDI Certificates for Diploma
by
Dave Lee
PPT
John williams
by
María José Martín Martínez
PDF
AL SARABI CV
by
Ahmad M. Sarabi
PPTX
BIOCOMBUSTIBLES - biología general 16 (letras- san marcos)
by
scarlett torres
DOCX
RESUME
by
Scott Marshall
PDF
CV_WeifnegLi_2016
by
Weifeng Li
DOC
Nicolette Ure_Curriculum Vitae (2)
by
Nicolette Ure
PDF
Seo проектирование сайта
by
Михаил Харченко
PPTX
Serm управление репутацией в поисковых системах
by
Михаил Харченко
PPT
Peritonitis Linda Fajardo
by
Linda Fajardo Moreno
PPT
Peritonitis linda fajardo
by
Linda Fajardo Moreno
PPTX
Projet Presentation
by
Uttam Sahu
[ACL2016] Achieving Open Vocabulary Neural Machine Translation with Hybrid Wo...
by
Hayahide Yamagishi
Chainerの使い方と 自然言語処理への応用
by
Yuya Unno
EDI Certificates for Diploma
by
Dave Lee
John williams
by
María José Martín Martínez
AL SARABI CV
by
Ahmad M. Sarabi
BIOCOMBUSTIBLES - biología general 16 (letras- san marcos)
by
scarlett torres
RESUME
by
Scott Marshall
CV_WeifnegLi_2016
by
Weifeng Li
Nicolette Ure_Curriculum Vitae (2)
by
Nicolette Ure
Seo проектирование сайта
by
Михаил Харченко
Serm управление репутацией в поисковых системах
by
Михаил Харченко
Peritonitis Linda Fajardo
by
Linda Fajardo Moreno
Peritonitis linda fajardo
by
Linda Fajardo Moreno
Projet Presentation
by
Uttam Sahu
Similar to [EMNLP2016読み会] Memory-enhanced Decoder for Neural Machine Translation
PDF
Learning Phrase Representations using RNN Encoder-Decoder for Statistical Mac...
by
Yuta Kikuchi
PDF
Memory-augmented Neural Machine Translation
by
Satoru Katsumata
PPTX
Attention-based NMT description
by
Toshiaki Nakazawa
PPTX
ニューラル機械翻訳の動向@IBIS2017
by
Toshiaki Nakazawa
PDF
Memory Networks (End-to-End Memory Networks の Chainer 実装)
by
Shuyo Nakatani
PPTX
Variational Template Machine for Data-to-Text Generation
by
harmonylab
PDF
transformer解説~Chat-GPTの源流~
by
MasayoshiTsutsui
PPTX
A convolutional encoder model for neural machine translation
by
Satoru Katsumata
PPTX
[DL輪読会]Unsupervised Neural Machine Translation
by
Deep Learning JP
PDF
RNN-based Translation Models (Japanese)
by
NAIST Machine Translation Study Group
PDF
最近のDeep Learning (NLP) 界隈におけるAttention事情
by
Yuta Kikuchi
PDF
Deep Learningの基礎と応用
by
Seiya Tokui
PDF
Recurrent Neural Networks
by
Seiya Tokui
PDF
東京大学2020年度深層学習(Deep learning基礎講座) 第9回「深層学習と自然言語処理」(一部文字が欠けてます)
by
Hitomi Yanaka
PDF
Extract and edit
by
禎晃 山崎
PDF
[DL輪読会]Pervasive Attention: 2D Convolutional Neural Networks for Sequence-to-...
by
Deep Learning JP
PDF
東京大学2021年度深層学習(Deep learning基礎講座2021) 第8回「深層学習と自然言語処理」
by
Hitomi Yanaka
PDF
Deep nlp 4.2-4.3_0309
by
cfiken
PDF
【文献紹介】Abstractive Text Summarization Using Sequence-to-Sequence RNNs and Beyond
by
Takashi YAMAMURA
DOCX
レポート深層学習Day3
by
ssuser9d95b3
Learning Phrase Representations using RNN Encoder-Decoder for Statistical Mac...
by
Yuta Kikuchi
Memory-augmented Neural Machine Translation
by
Satoru Katsumata
Attention-based NMT description
by
Toshiaki Nakazawa
ニューラル機械翻訳の動向@IBIS2017
by
Toshiaki Nakazawa
Memory Networks (End-to-End Memory Networks の Chainer 実装)
by
Shuyo Nakatani
Variational Template Machine for Data-to-Text Generation
by
harmonylab
transformer解説~Chat-GPTの源流~
by
MasayoshiTsutsui
A convolutional encoder model for neural machine translation
by
Satoru Katsumata
[DL輪読会]Unsupervised Neural Machine Translation
by
Deep Learning JP
RNN-based Translation Models (Japanese)
by
NAIST Machine Translation Study Group
最近のDeep Learning (NLP) 界隈におけるAttention事情
by
Yuta Kikuchi
Deep Learningの基礎と応用
by
Seiya Tokui
Recurrent Neural Networks
by
Seiya Tokui
東京大学2020年度深層学習(Deep learning基礎講座) 第9回「深層学習と自然言語処理」(一部文字が欠けてます)
by
Hitomi Yanaka
Extract and edit
by
禎晃 山崎
[DL輪読会]Pervasive Attention: 2D Convolutional Neural Networks for Sequence-to-...
by
Deep Learning JP
東京大学2021年度深層学習(Deep learning基礎講座2021) 第8回「深層学習と自然言語処理」
by
Hitomi Yanaka
Deep nlp 4.2-4.3_0309
by
cfiken
【文献紹介】Abstractive Text Summarization Using Sequence-to-Sequence RNNs and Beyond
by
Takashi YAMAMURA
レポート深層学習Day3
by
ssuser9d95b3
More from Hayahide Yamagishi
PPTX
[PACLING2019] Improving Context-aware Neural Machine Translation with Target-...
by
Hayahide Yamagishi
PDF
[修論発表会資料] 目的言語の文書文脈を用いたニューラル機械翻訳
by
Hayahide Yamagishi
PDF
[論文読み会資料] Beyond Error Propagation in Neural Machine Translation: Characteris...
by
Hayahide Yamagishi
PDF
[ACL2018読み会資料] Sharp Nearby, Fuzzy Far Away: How Neural Language Models Use C...
by
Hayahide Yamagishi
PDF
[NAACL2018読み会] Deep Communicating Agents for Abstractive Summarization
by
Hayahide Yamagishi
PDF
[論文読み会資料] Asynchronous Bidirectional Decoding for Neural Machine Translation
by
Hayahide Yamagishi
PDF
[ML論文読み会資料] Teaching Machines to Read and Comprehend
by
Hayahide Yamagishi
PDF
[EMNLP2017読み会] Efficient Attention using a Fixed-Size Memory Representation
by
Hayahide Yamagishi
PDF
[ML論文読み会資料] Training RNNs as Fast as CNNs
by
Hayahide Yamagishi
PDF
入力文への情報の付加によるNMTの出力文の変化についてのエラー分析
by
Hayahide Yamagishi
PDF
[ACL2017読み会] What do Neural Machine Translation Models Learn about Morphology?
by
Hayahide Yamagishi
PDF
Why neural translations are the right length
by
Hayahide Yamagishi
PDF
A hierarchical neural autoencoder for paragraphs and documents
by
Hayahide Yamagishi
PDF
ニューラル論文を読む前に
by
Hayahide Yamagishi
PPTX
ニューラル日英翻訳における出力文の態制御
by
Hayahide Yamagishi
[PACLING2019] Improving Context-aware Neural Machine Translation with Target-...
by
Hayahide Yamagishi
[修論発表会資料] 目的言語の文書文脈を用いたニューラル機械翻訳
by
Hayahide Yamagishi
[論文読み会資料] Beyond Error Propagation in Neural Machine Translation: Characteris...
by
Hayahide Yamagishi
[ACL2018読み会資料] Sharp Nearby, Fuzzy Far Away: How Neural Language Models Use C...
by
Hayahide Yamagishi
[NAACL2018読み会] Deep Communicating Agents for Abstractive Summarization
by
Hayahide Yamagishi
[論文読み会資料] Asynchronous Bidirectional Decoding for Neural Machine Translation
by
Hayahide Yamagishi
[ML論文読み会資料] Teaching Machines to Read and Comprehend
by
Hayahide Yamagishi
[EMNLP2017読み会] Efficient Attention using a Fixed-Size Memory Representation
by
Hayahide Yamagishi
[ML論文読み会資料] Training RNNs as Fast as CNNs
by
Hayahide Yamagishi
入力文への情報の付加によるNMTの出力文の変化についてのエラー分析
by
Hayahide Yamagishi
[ACL2017読み会] What do Neural Machine Translation Models Learn about Morphology?
by
Hayahide Yamagishi
Why neural translations are the right length
by
Hayahide Yamagishi
A hierarchical neural autoencoder for paragraphs and documents
by
Hayahide Yamagishi
ニューラル論文を読む前に
by
Hayahide Yamagishi
ニューラル日英翻訳における出力文の態制御
by
Hayahide Yamagishi
[EMNLP2016読み会] Memory-enhanced Decoder for Neural Machine Translation
1.
Memory-enhanced Decoder for Neural
Machine Translation Mingxuan Wang, Zhengdong Lu, Hang Li and Qun Liu 2/22 EMNLP読み会 紹介: B4 山岸駿秀
2.
Introduction • Attention-based NMT
(RNNsearch) の成功 [Bahdanau+ 2015, ICLR] • 入力文全体を保存し、部分的に用いて出力することは有用である • Neural Turing Machine (NTM) [Graves+ 2014, arXivにのみ投稿] • ベクトルを格納する数個のメモリと、重みベクトルによるヘッドを持つ • 入力時にメモリの状態を読み込み、出力 • 出力と同時にメモリを書き換える • どのメモリをどれだけ読む/書くのかをヘッドの重みを用いて決定 • ヘッドの重みを学習する • これらを組み合わせ、外部メモリを持つRNNsearchを提案 • MEMDECと呼ぶ • 生成の後半で使うような情報を保存できる可能性がある 1
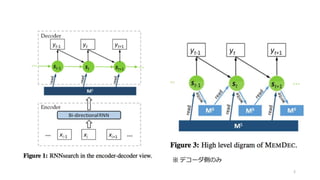
3.
※ デコーダ側のみ 2
4.
NMT with improved
attention • 入力x (xの文長はTx) がある • Encoderの単語jの隠れ層hjは、メ モリMsとして格納 • (1)を導出したい • (2): Decoderの時刻tでの隠れ層 • g()にはGRUを使用 • (3): Attentionベクトル • Wa、Uaは重み行列 3
5.
NMT with improved
attention • Groundhog (BahdanauらによるRNNsearchの実装) では、αt,jの計算 に前の出力yt-1が用いられていない • 前の出力を用いることは有用なのではないだろうか • 今回は、以下の計算式で計算した • H() = tanh() (GRUの方が性能がよいが、簡略化のためtanhを使用) • eはyt-1のembedding 4
6.
5
7.
Updating • MBは今回新たに追加する外部メモリ • Wはそれぞれ重み行列 •
メモリも更新 6
8.
Prediction • Bahdanauらの提案した手法によって単語を予測する • “ωy
is the parameters associated with the word y.” 7
9.
Reading Memory-state • MBはn
(メモリセルの数) * m (セルの次元数)の行列 • wR tはn次元、rtはm次元のベクトル • wR tは以下のようにして更新 • 、 • wR gはm次元のベクトル • vはm次元のベクトル、W、Uはm*m次元の行列 8
10.
Writing to Memory-states •
ERASEとADDの操作をすることでMBを更新 • 初めにERASE処理 • wW t、μERS tはm次元のベクトル、WERSはm*mの行列 • 次にADD処理 • μADD tはm次元のベクトル、WADDはm*mの行列 • wRとwWに同じ重みを用いると性能が良かった 9
11.
Setting • 中英翻訳 • 学習データ:
LDC corpus • 1.25M 文対 (中国語の単語数: 27.9M、英語の単語数: 34.5M) • 50単語以上の文はNMTでは不使用 (Mosesでは使用) • NMTでは、語彙数を30,000語に制限 • テストデータ: NIST2002 〜 2006 (MT02 〜 06と記述) • embedding: 512、hidden size: 512 • メモリセルの数n = 8、メモリセルの次元m = 1024 • Adadelta (ε = 10-6、ρ = 0.95)で最適化、batch size = 80 • 確率0.5でDropout 10
12.
Pre-training • パラメータ数がとても多いので、pre-trainingを行う 1. 外部メモリなしのRNNsearchを学習させる 2.
1を元に、EncoderとMEMDECのパラメータを学習させる • 以下の、メモリ状態に関係あるパラメータは学習させない 3. 全てのパラメータを用いてfine-tuningを行う 11
13.
Comparison system • Moses
(state-of-the-art SMT) • Groundhog (Baseline) • BahdanauらのAttention-based NMT (RNNsearch) の実装 • RNNsearch* (strong Baseline) • 一つ前の出力をAttentionベクトルCtの計算に用いるシステムを追加 • dropoutも追加 • coverage (state-of-the-art NMT, Tu+, ACL2016) • 入力の表現のカバレッジを用いる • MEMDEC (提案手法) 12
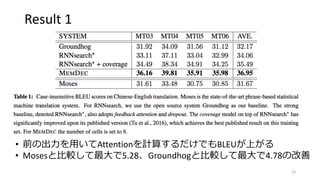
14.
Result 1 • 前の出力を用いてAttentionを計算するだけでもBLEUが上がる •
Mosesと比較して最大で5.28、Groundhogと比較して最大で4.78の改善 13
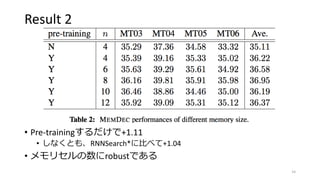
15.
Result 2 • Pre-trainingするだけで+1.11 •
しなくとも、RNNSearch*に比べて+1.04 • メモリセルの数にrobustである 14
16.
Result 3 15
17.
Conclusion • RNN Decoderを外部メモリを用いて拡張した •
メモリの数は大きく影響しない • 結果、中英翻訳のスコアを大きく改善できた • アテンションの計算に前の出力を用いることも有用である 16
Editor's Notes
#8
Stの計算時には、それらをcombineする?
Download


![Introduction
• Attention-based NMT (RNNsearch) の成功 [Bahdanau+ 2015, ICLR]
• 入力文全体を保存し、部分的に用いて出力することは有用である
• Neural Turing Machine (NTM) [Graves+ 2014, arXivにのみ投稿]
• ベクトルを格納する数個のメモリと、重みベクトルによるヘッドを持つ
• 入力時にメモリの状態を読み込み、出力
• 出力と同時にメモリを書き換える
• どのメモリをどれだけ読む/書くのかをヘッドの重みを用いて決定
• ヘッドの重みを学習する
• これらを組み合わせ、外部メモリを持つRNNsearchを提案
• MEMDECと呼ぶ
• 生成の後半で使うような情報を保存できる可能性がある
1](https://image.slidesharecdn.com/emnlp-170228052941/85/EMNLP2016-Memory-enhanced-Decoder-for-Neural-Machine-Translation-2-320.jpg)


























![[ACL2016] Achieving Open Vocabulary Neural Machine Translation with Hybrid Wo...](https://cdn.slidesharecdn.com/ss_thumbnails/acl-161026074300-thumbnail.jpg?width=640&height=640&fit=bounds)





















![[DL輪読会]Unsupervised Neural Machine Translation](https://cdn.slidesharecdn.com/ss_thumbnails/dlyokota20180316-180316003237-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Pervasive Attention: 2D Convolutional Neural Networks for Sequence-to-...](https://cdn.slidesharecdn.com/ss_thumbnails/20180907pervasiveattention2dconvolutionalneuralnetworksforsequence-to-sequenceprediction-180907000649-thumbnail.jpg?width=640&height=640&fit=bounds)




![[PACLING2019] Improving Context-aware Neural Machine Translation with Target-...](https://cdn.slidesharecdn.com/ss_thumbnails/paclingpresen-191012011632-thumbnail.jpg?width=640&height=640&fit=bounds)
![[修論発表会資料] 目的言語の文書文脈を用いたニューラル機械翻訳](https://cdn.slidesharecdn.com/ss_thumbnails/shuronpresen-191012004831-thumbnail.jpg?width=640&height=640&fit=bounds)
![[論文読み会資料] Beyond Error Propagation in Neural Machine Translation: Characteris...](https://cdn.slidesharecdn.com/ss_thumbnails/paperreading2018later-181107050738-thumbnail.jpg?width=640&height=640&fit=bounds)
![[ACL2018読み会資料] Sharp Nearby, Fuzzy Far Away: How Neural Language Models Use C...](https://cdn.slidesharecdn.com/ss_thumbnails/acl2018reading-181029052106-thumbnail.jpg?width=640&height=640&fit=bounds)
![[NAACL2018読み会] Deep Communicating Agents for Abstractive Summarization](https://cdn.slidesharecdn.com/ss_thumbnails/naacl2018reading-180801082628-thumbnail.jpg?width=640&height=640&fit=bounds)
![[論文読み会資料] Asynchronous Bidirectional Decoding for Neural Machine Translation](https://cdn.slidesharecdn.com/ss_thumbnails/reading0510-180511063343-thumbnail.jpg?width=640&height=640&fit=bounds)
![[ML論文読み会資料] Teaching Machines to Read and Comprehend](https://cdn.slidesharecdn.com/ss_thumbnails/ml2-171222014201-thumbnail.jpg?width=640&height=640&fit=bounds)
![[EMNLP2017読み会] Efficient Attention using a Fixed-Size Memory Representation](https://cdn.slidesharecdn.com/ss_thumbnails/emnlp2017-171122025333-thumbnail.jpg?width=640&height=640&fit=bounds)
![[ML論文読み会資料] Training RNNs as Fast as CNNs](https://cdn.slidesharecdn.com/ss_thumbnails/ml-171110024905-thumbnail.jpg?width=640&height=640&fit=bounds)

![[ACL2017読み会] What do Neural Machine Translation Models Learn about Morphology?](https://cdn.slidesharecdn.com/ss_thumbnails/acl2017-171011024754-thumbnail.jpg?width=640&height=640&fit=bounds)



