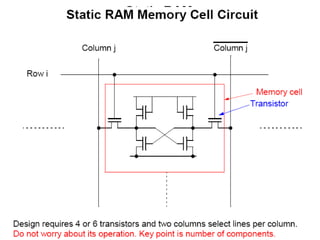
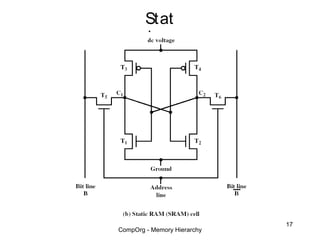
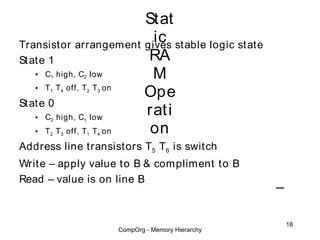
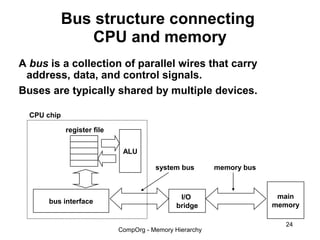
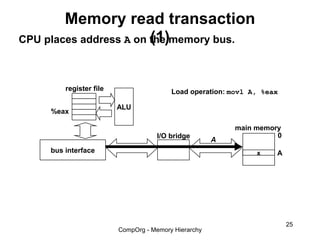
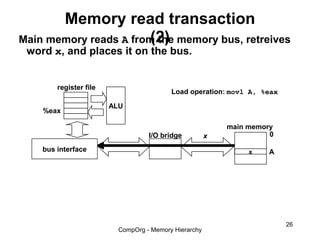
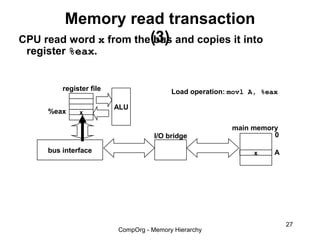
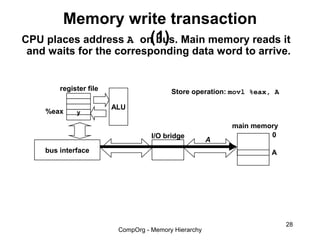
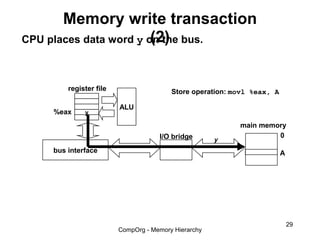
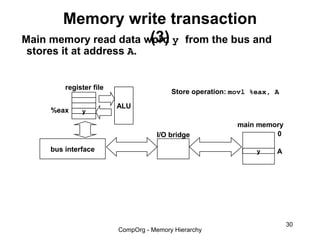
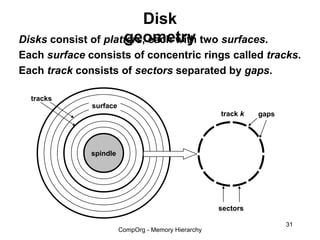
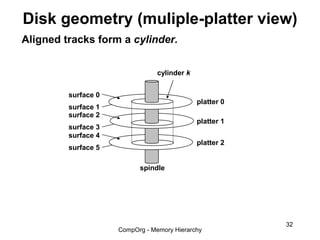
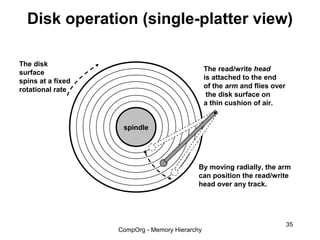
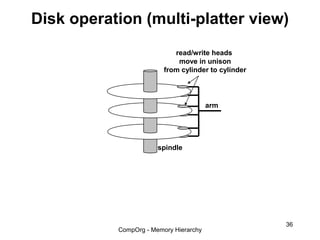
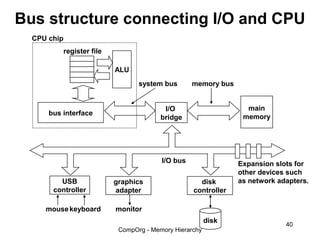
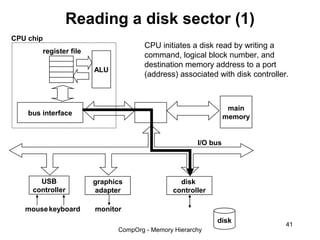
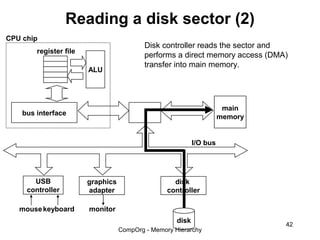
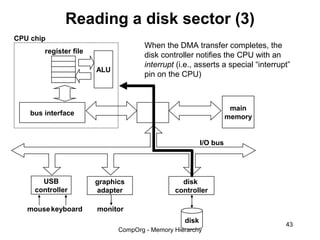
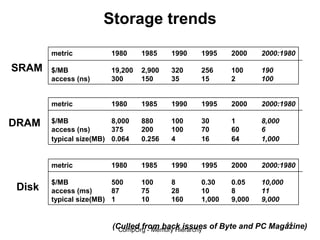
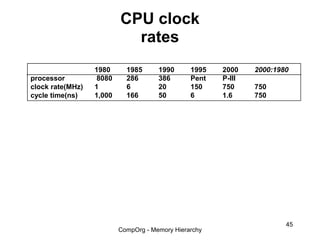
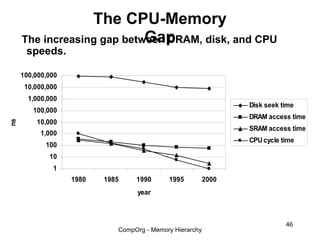
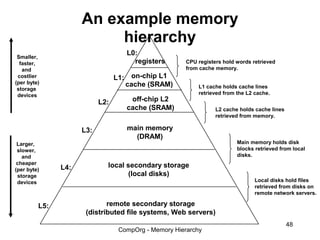
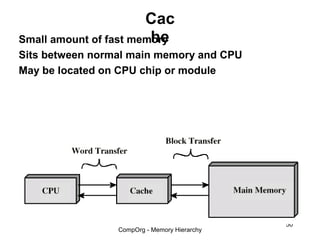
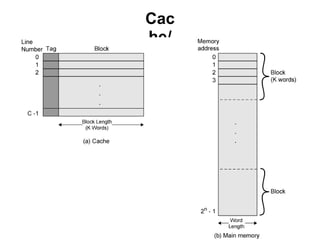
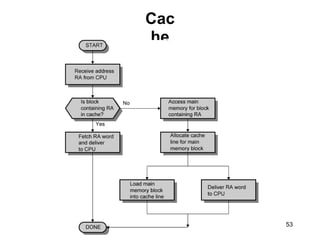
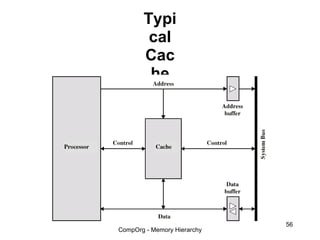
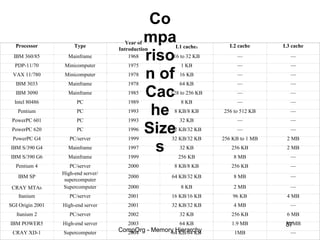
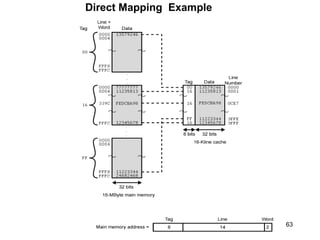
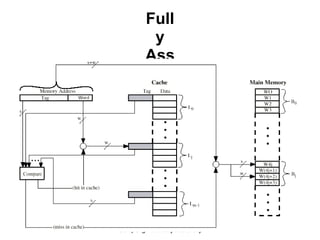
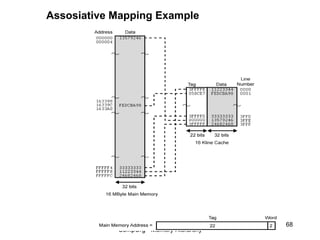
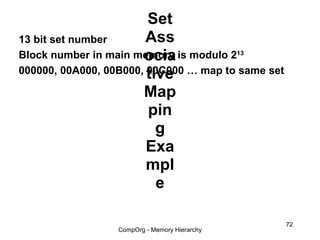
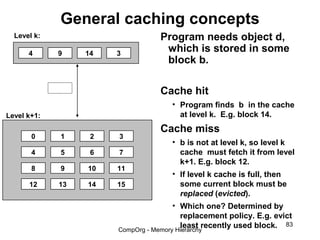
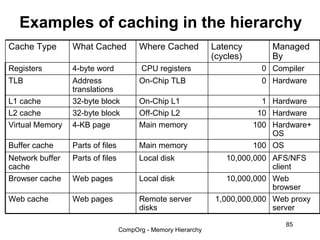
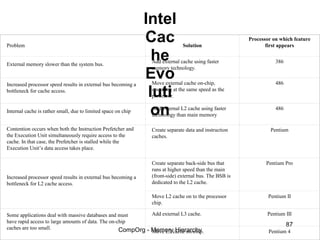
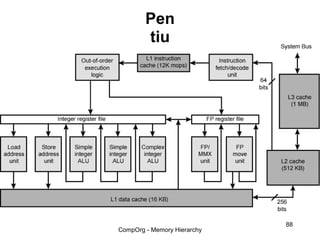
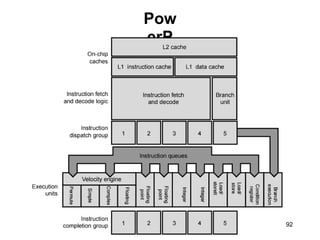
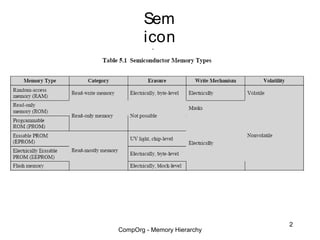
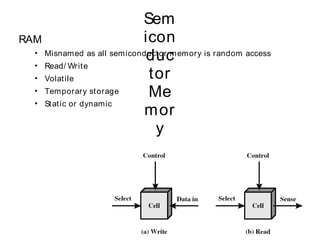
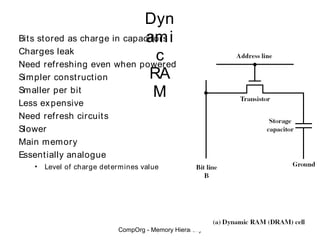
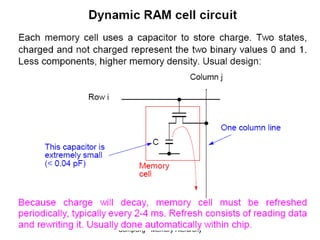
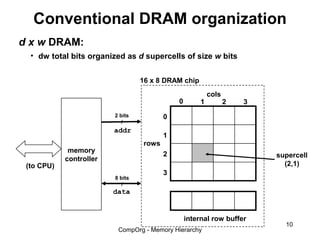
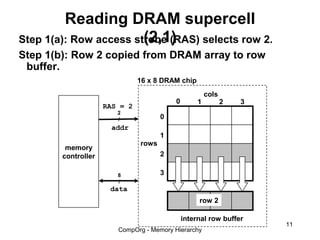
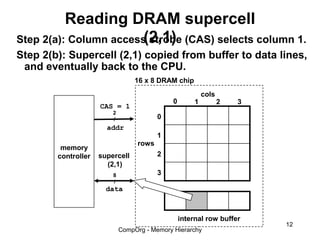
This document discusses different types of memory. It compares static RAM (SRAM) and dynamic RAM (DRAM). SRAM uses 6 transistors per bit to store data without refreshing, while DRAM uses 1 transistor and a capacitor, requiring refreshing every 10-100 milliseconds. DRAM is slower than SRAM but is cheaper to produce, making it suitable for main memory applications. The document also describes the basic structure and operation of DRAM, including row access, column access, and memory modules. Enhanced DRAM types like FPM, EDO, SDRAM, and DDR are mentioned as well.






![Enhanced
DRAMs
All enhanced DRAMs are built around the conventional
DRAM core.
• Fast page mode DRAM (FPM DRAM)
– Access contents of row with [RAS, CAS, CAS, CAS, CAS] instead of
[(RAS,CAS), (RAS,CAS), (RAS,CAS), (RAS,CAS)].
• Extended data out DRAM (EDO DRAM)
– Enhanced FPM DRAM with more closely spaced CAS signals.
• Synchronous DRAM (SDRAM)
– Driven with rising clock edge instead of asynchronous control signals.
• Double data-rate synchronous DRAM (DDR SDRAM)
– Enhancement of SDRAM that uses both clock edges as control signals.
• Video RAM (VRAM)
– Like FPM DRAM, but output is produced by shifting row buffer
– Dual ported (allows concurrent reads and writes)
14
CompOrg - Memory Hierarchy](https://image.slidesharecdn.com/memory-hir-121121071333-phpapp01/85/Memory-hir-14-320.jpg)