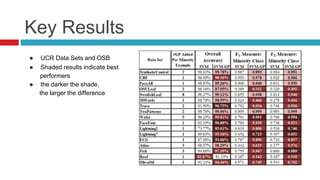
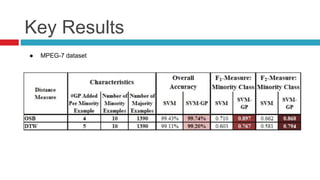
This paper proposes a new technique called "ghost points" to address class imbalance in time series classification problems. Ghost points are synthetic data points generated in the distance space between real data points rather than feature space. The paper defines a methodology to calculate distances between real and ghost points. It tests the approach on 17 time series datasets and an image dataset, finding it significantly improves classification performance over the baselines, especially when used with dynamic time warping and optimal subsequence matching. However, over-sampling adds computational cost and introduces a new parameter around the number of ghost points to generate.