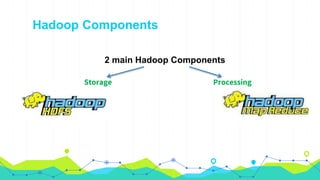
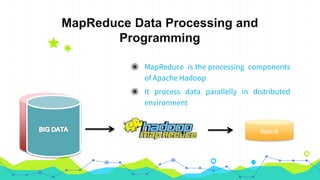
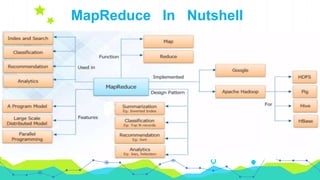
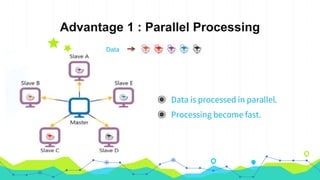
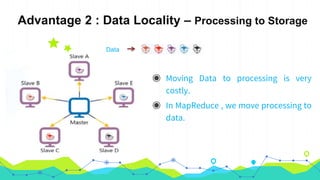
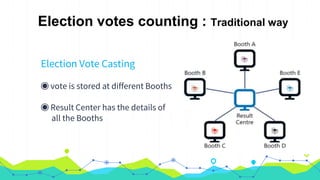
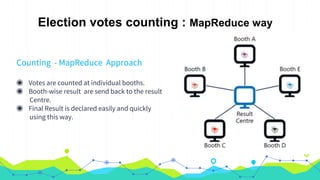
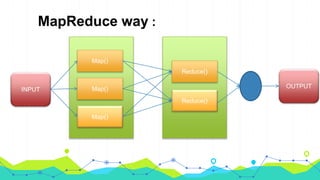
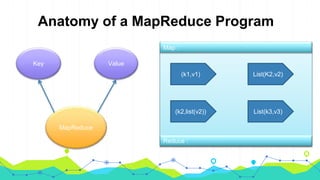
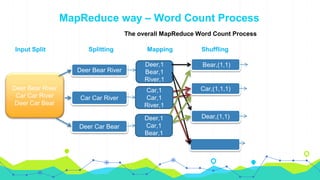
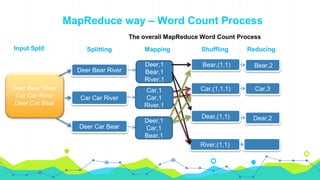
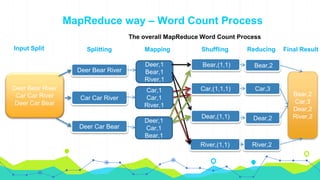
This document provides an overview of Hadoop MapReduce. It begins with an introduction to MapReduce and defines it as the processing component of Apache Hadoop that processes data in parallel across a distributed environment. The document then discusses two main advantages of MapReduce: 1) parallel processing, which makes data processing fast, and 2) data locality where processing is moved to the data rather than moving large amounts of data. It also provides an example of how MapReduce can be used to efficiently count words in a document by splitting the work across nodes and aggregating the results.






























































![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)

![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)









![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)




