Downloaded 27 times





































![MapReduce job example
public static void main(String[] args) throws Exception {
JobConf conf = new JobConf(WordCount.class);
conf.setJobName("wordcount");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(Map.class);
conf.setCombinerClass(Reduce.class);
conf.setReducerClass(Reduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
JobClient.runJob(conf);
}
}](https://image.slidesharecdn.com/a4nw53ewqa2qyx1xeyku-signature-b873971af6e009937fba5f74268de91ea90842eeaa417538a5c0eee94318ab9d-poli-141203043602-conversion-gate01/85/Big-Data-a-space-adventure-Mario-Cartia-Codemotion-Milan-2014-51-320.jpg)






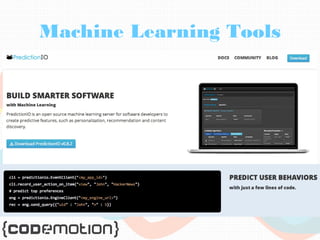




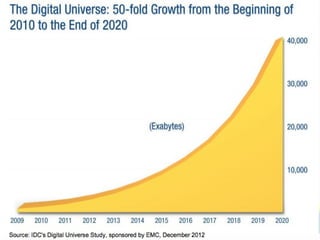
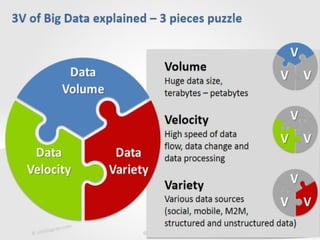
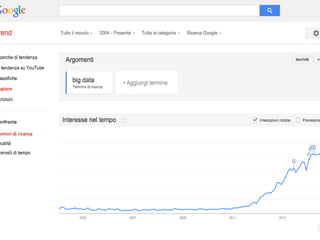
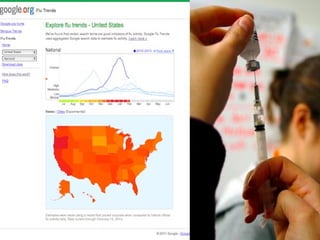
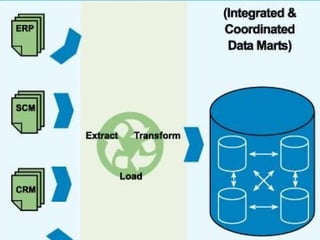
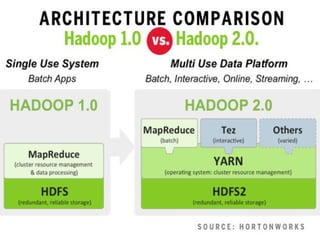
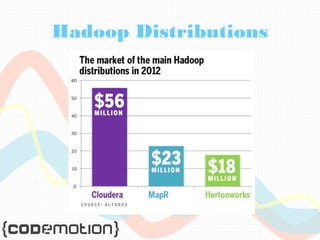
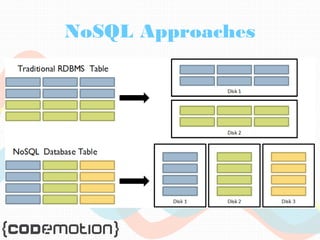
The document provides an overview of big data, highlighting its volume, variety, and velocity, alongside examples of its successful applications such as Amazon's targeted advertising and Google Flu Trends. It explains the transition from traditional relational databases to NoSQL solutions, emphasizing Apache Hadoop and the MapReduce programming model for handling large data sets. Additionally, it covers machine learning methods and data visualization tools that aid in analyzing and interpreting big data insights.



































































