Download as PDF, PPTX




















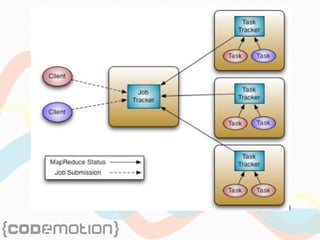
















![MapReduce job example
public static void main(String[] args) throws Exception {
JobConf conf = new JobConf(WordCount.class);
conf.setJobName("wordcount");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(Map.class);
conf.setCombinerClass(Reduce.class);
conf.setReducerClass(Reduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
JobClient.runJob(conf);
}
}](https://image.slidesharecdn.com/codemotionwsbigdataconf-150402084453-conversion-gate01/85/Big-Data-a-space-adventure-Mario-Cartia-Codemotion-Rome-2015-51-320.jpg)










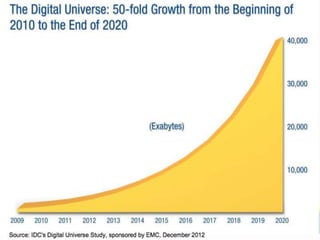
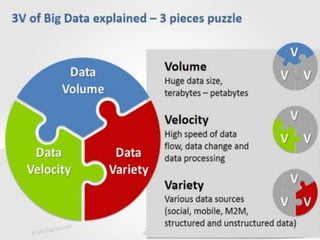
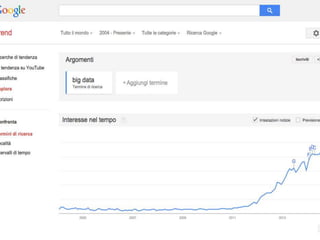
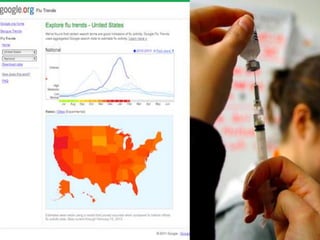
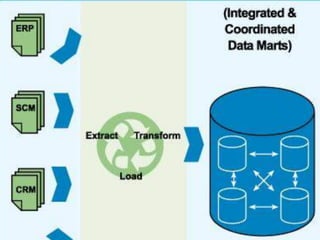
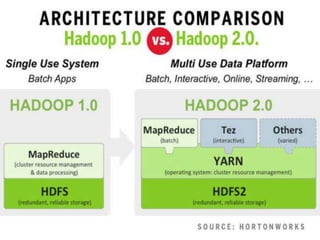
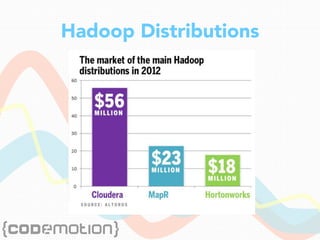
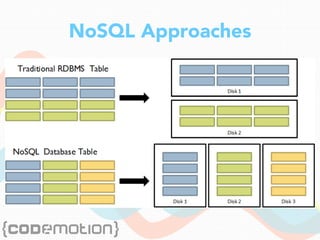
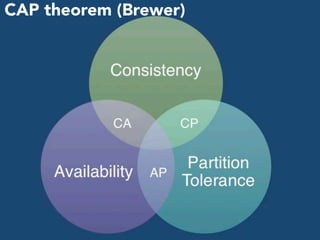
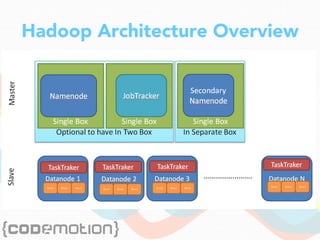
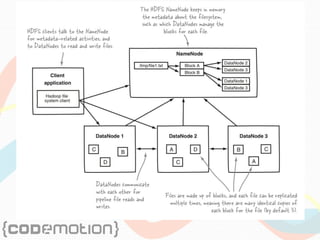
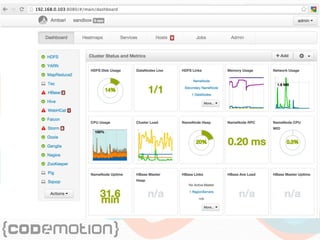
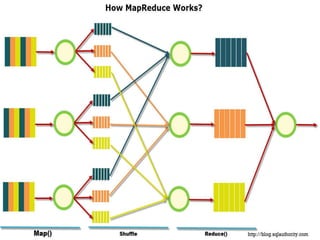
The document discusses the foundations of big data, specifically focusing on NoSQL and Hadoop technologies, and highlights the significance of volume, variety, and velocity in data processing. It includes examples of successful big data applications such as Amazon's targeted advertising, Google Flu Trends, and recaptcha services, illustrating how organizations leverage data for insights. Additionally, it explains Hadoop's architecture, the MapReduce programming model, and introduces machine learning concepts and tools relevant to big data analytics.









































































































